Command Palette
Search for a command to run...
SAM 3D: 3Dfy Anything in Images
SAM 3D: 3Dfy Anything in Images
Abstract
We present SAM 3D, a generative model for visually grounded 3D object reconstruction, predicting geometry, texture, and layout from a single image. SAM 3D excels in natural images, where occlusion and scene clutter are common and visual recognition cues from context play a larger role. We achieve this with a human- and model-in-the-loop pipeline for annotating object shape, texture, and pose, providing visually grounded 3D reconstruction data at unprecedented scale. We learn from this data in a modern, multi-stage training framework that combines synthetic pretraining with real-world alignment, breaking the 3D "data barrier". We obtain significant gains over recent work, with at least a 5:1 win rate in human preference tests on real-world objects and scenes. We will release our code and model weights, an online demo, and a new challenging benchmark for in-the-wild 3D object reconstruction.
One-sentence Summary
SAM 3D is a generative model for visually grounded 3D object reconstruction from a single image that leverages a human-and-model-in-the-loop pipeline for generating large-scale annotated data and a modern multi-stage training framework combining synthetic pretraining with real-world alignment to achieve at least a 5:1 win rate over recent work in human preference tests on real-world objects and scenes with occlusion and clutter.
Key Contributions
- SAM 3D is a generative foundation model that predicts geometry, texture, and layout from a single natural image. The system excels in natural images where occlusion and scene clutter are common by utilizing visual recognition cues from context.
- A human-and-model-in-the-loop pipeline provides visually grounded 3D reconstruction data at an unprecedented scale. The approach employs a multi-stage framework combining synthetic pretraining with real-world alignment and self-training to bridge the domain gap.
- The release includes code, model weights, an online demo, and a new challenging benchmark for in-the-wild 3D object reconstruction. Evaluation results show significant gains over recent work with at least a 5:1 win rate in human preference tests on real-world objects and scenes.
Introduction
Single-image 3D reconstruction is vital for robotics and augmented reality yet struggles with occlusion and clutter in natural scenes. Existing methods depend on synthetic data or isolated objects, failing to generalize to real-world images due to a scarcity of paired 3D ground truth. The authors present SAM 3D, a generative foundation model capable of predicting full object geometry and texture from a single input. To address the data barrier, they utilize a human and model-in-the-loop annotation pipeline coupled with a multi-stage training framework that aligns synthetic pretraining with real-world data.
Dataset
The authors structure the training pipeline into three distinct phases, moving from synthetic pretraining to semi-synthetic mid-training and finally to real-world post-training.
-
Pretraining (Iso-3DO)
- Composition: 2.7 million object meshes sourced from Objaverse-XL and licensed datasets.
- Processing: Each mesh is rendered from 24 viewpoints to create high-resolution image, shape, and texture triplets of single centered objects.
- Filtering: A rule-based strategy removes samples with overly simplistic geometry, such as near-degenerate point structures or flat surfaces, and eliminates spatial outliers.
- Usage: The model trains for 2.5 trillion tokens to learn accurate 3D shape and texture reconstruction.
-
Mid-Training (RP-3DO)
- Composition: 61 million samples generated using 2.8 million unique meshes.
- Processing: A render-paste technique composites textured meshes into natural images using alpha compositing. Variants include Flying Occlusions (random orientation), Object Swap Random (depth-guided), and Object Swap Annotated (human-annotated pose).
- Capabilities: This phase targets mask-following, occlusion robustness, and layout estimation.
- Usage: Training continues for 2.7 trillion tokens to establish foundational skills for visually grounded reconstruction.
- Lighting: Lighting direction and intensity are randomized to encourage the model to predict de-lighted textures.
-
Post-Training (MITL-3DO)
- Composition: Almost 1 million real-world images from diverse sources including SA-1B, MetaCLIP, SA-VI, and Ego4D.
- Annotation Pipeline:
- Stage 1: Images are filtered for quality and masked using a 3D-oriented taxonomy based on LVIS.
- Stage 2: Annotators perform best-of-N selection from an ensemble of 6 to 10 model-generated candidates.
- Stage 2.5: Professional 3D artists manually create meshes for hard cases where models fail (Art-3DO).
- Stage 3: Annotators align selected meshes to 2.5D point clouds to determine translation, rotation, and scale.
- Scale: The dataset includes approximately 3.14 million untextured meshes and 100K textured meshes.
- Usage: Data is used for supervised fine-tuning and preference alignment to match human quality ratings.
-
Evaluation Benchmarks
- SA-3DAO: A new benchmark of 1,000 high-fidelity 3D objects created by professional artists from natural images.
- Additional Sets: ISO3D from 3D Arena and Aria Digital Twin are used for quantitative evaluation of shape, texture, and layout.
Method
The authors formulate the 3D reconstruction task as inverting the mapping from a 3D object to a set of 2D pixels. Given an image I and a mask M, the goal is to model the conditional distribution p(S,T,R,t,s∣I,M), where S represents shape, T texture, and (R,t,s) denote rotation, translation, and scale. To approximate this distribution, the system employs a two-stage generative model consisting of a Geometry Model and a Texture & Refinement Model.
Architecture
The overall framework is depicted below, illustrating the separation between geometry prediction and subsequent texture refinement.

Input Encoding The system utilizes DINOv2 as a backbone encoder to extract features from the input. It processes two pairs of images to generate conditioning tokens:
- Cropped Object: The image I masked by M and its binary mask are encoded to provide a focused, high-resolution view of the target object.
- Full Image: The full image I and its corresponding binary mask are encoded to capture global scene context and recognition cues. Optionally, the model can condition on a coarse scene point map P, derived from hardware sensors or monocular depth estimation, to integrate with other perception pipelines.
Geometry Model The Geometry Model predicts the object layout and coarse shape. It employs a 1.2B parameter flow transformer built on a Mixture-of-Transformers (MoT) architecture. The input consists of shape tokens and layout tokens. The MoT design utilizes two distinct transformer streams: one dedicated to shape tokens and a second with shared parameters for layout tokens (R,t,s). A structured attention mask allows for independent training of modalities (e.g., shape-only datasets) while maintaining cross-modal interaction during the forward pass. This shared context is critical for consistency, ensuring that rotation predictions remain meaningful relative to the predicted shape. The model outputs a coarse shape O∈R643 and layout parameters R∈R6, t∈R3, and s∈R3.
Texture & Refinement Model Following the geometry prediction, the Texture & Refinement Model learns the conditional distribution p(S,T∣I,M,O). It extracts active voxels from the coarse shape O and refines geometric details while synthesizing object texture. This stage uses a 600M parameter sparse latent flow transformer. The latent representations are subsequently decoded into either a mesh or 3D Gaussian splats via separate VAE decoders that share the same encoder and latent space structure.
Training Process
The authors employ a multi-stage training paradigm that progressively exposes the model to increasingly complex data and modalities, moving from synthetic pre-training to real-world alignment.

Pre-training and Mid-training The initial phase focuses on building foundational capabilities such as shape generation and mask-following using synthetic datasets. During pre-training, the model learns shape and texture priors from large-scale synthetic data like Iso-3DO. Mid-training, or continued pre-training, imparts general skills such as occlusion robustness and the ability to utilize visual cues for pose estimation. This is achieved using semi-synthetic data generated via render-paste strategies (e.g., RP-3DO), where synthetic meshes are inserted into natural images with depth-aware occlusion handling.
Post-training and Alignment To close the domain gap between synthetic and real-world data and align with human preferences, the model undergoes a post-training phase. This involves Supervised Fine-Tuning (SFT) on real-world annotated data (e.g., MITL-3DO, Art-3DO) followed by Direct Preference Optimization (DPO). The process relies on a data engine that iteratively collects training samples and preference data.

The alignment workflow progresses through distinct stages of data curation and model refinement.
Initially, the system performs object selection and masking. It then evaluates 3D shape and texture preferences, filtering for accurate outputs. Inaccurate predictions trigger a sampling loop involving 3D artists for shape modeling. Once accurate, the data is aligned to a 2.5D scene using human and point cloud verification. This iterative process allows the model to explore new regions of the data distribution where performance was previously low, effectively seeding new regions of strong performance with high-quality artist meshes.
To improve the efficiency of the data flywheel, the system processes failure data by generating multiple seeds, ranking them via a Vision-Language Model (VLM) tournament, and scoring them. Samples that pass a quality threshold are re-annotated and used for further SFT, creating a virtuous cycle of improvement.
Finally, to enable sub-second inference for applications like robotics, the authors employ a distillation stage. They adapt a shortcut model formulation to reduce the number of function evaluations (NFE) required during inference from 25 down to 4, without significantly degrading generation quality. This allows the model to switch seamlessly between high-quality flow matching inference and fast shortcut inference.
Experiment
SAM 3D was evaluated against prior methods for single-object generation and 3D scene reconstruction using human preference studies and quantitative benchmarks, where it significantly outperforms baselines on challenging real-world inputs with occlusion. Further analysis confirms that multi-stage training and iterative data engine improvements are crucial for robust performance, while additional experiments validate the effectiveness of test-time optimization and model distillation, though limitations persist regarding fine detail resolution and physical interaction reasoning.
The the the table outlines a multi-stage training curriculum that transitions from large-scale pre-training to specific alignment tasks. The process moves from using object-centric crops on synthetic data to utilizing full images and pointmaps from real-world datasets in later stages. Finally, the alignment stage employs a much smaller dataset with a significantly reduced learning rate compared to the preceding phases. The condition input evolves from object-centric crops in pre-training to full images and pointmaps in mid-training and SFT. The volume of training data decreases significantly from the pre-training stage to the final alignment stage. Learning rates are progressively lowered, with the alignment stage using a rate significantly smaller than pre-training.
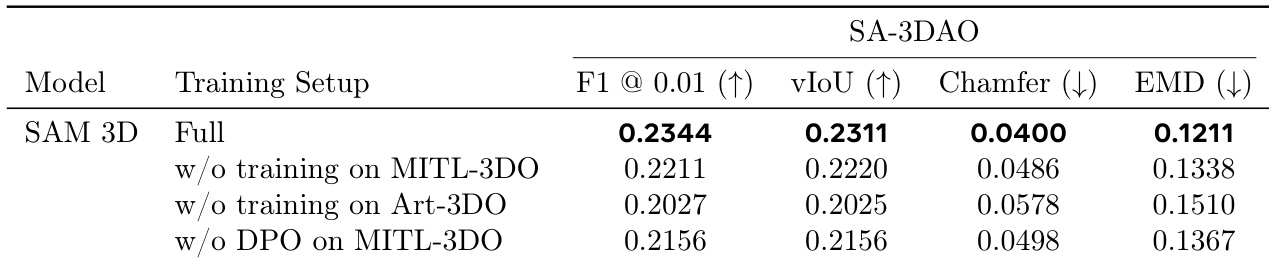
The authors conduct an ablation study to assess how different training components affect the SAM 3D model's performance on the SA-3DAO benchmark. The results demonstrate that the full multi-stage training pipeline, including specific datasets and direct preference optimization, yields the highest geometric accuracy and shape quality. The full training setup consistently outperforms ablated models across all shape quality metrics. Removing the Art-3DO dataset results in the most severe performance drop among the tested configurations. Excluding direct preference optimization on MITL-3DO data leads to measurable decreases in geometric fidelity.
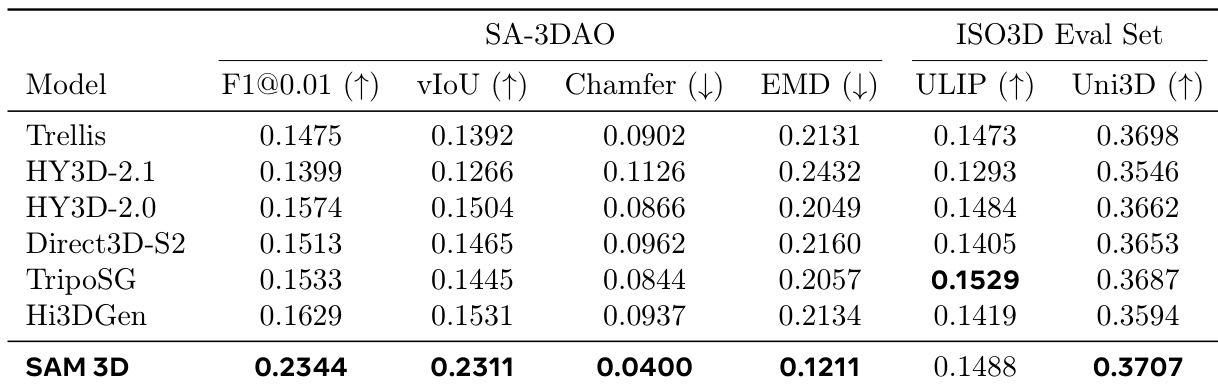
The authors evaluate SAM 3D against state-of-the-art methods on two datasets, demonstrating that the model matches or exceeds previous performance on isolated object images while significantly outperforming baselines on challenging real-world inputs. Results indicate superior geometric fidelity across all tested metrics on the real-world dataset and competitive or leading similarity scores on the isolated object dataset. SAM 3D achieves the highest performance across all shape quality metrics on the challenging real-world dataset. The model secures the leading position in Uni3D similarity scores on the isolated object evaluation set. Geometric fidelity measures show substantial improvements for SAM 3D compared to other baselines on the real-world dataset.
The authors investigate the effect of increasing the best-of-N search size from 2 to 50 during data generation to recover challenging samples for fine-tuning. The results demonstrate that utilizing this recovered data significantly enhances model performance on difficult inputs compared to the standard baseline. This approach leads to consistent improvements in geometric accuracy and shape quality across multiple evaluation sets. The recovery strategy using N=50 search yields superior Chamfer distances and F1 scores compared to the N=2 baseline. Performance improvements are consistent across Tail Holdout, Epic Kitchens, and SA-3DAO datasets. The method effectively recovers previously discarded samples, boosting robustness on hard categories like food items.

The authors present a quantitative comparison of 3D layout prediction methods, contrasting pipeline approaches with joint generative models on real-world datasets. The results indicate that the proposed SAM 3D model significantly outperforms existing baselines across all metrics, including 3D IoU, rotation error, and pose accuracy. SAM 3D achieves the highest 3D IoU and ADD-S scores compared to both pipeline and joint baselines. The joint generation approach demonstrates a substantial advantage over pipeline methods that combine separate shape and pose models. Rotation error is minimized by the proposed model, showing superior pose estimation capabilities compared to competitors.
The experiments validate a multi-stage training curriculum transitioning from synthetic to real-world data, confirming that the full pipeline with direct preference optimization yields the highest geometric accuracy and shape quality. Ablation studies reveal that specific datasets and data recovery strategies via best-of-N search are critical for robustness on challenging inputs. Furthermore, comparisons against state-of-the-art methods show the model significantly outperforms baselines on real-world datasets and demonstrates substantial advantages over pipeline methods in 3D layout prediction tasks.