Command Palette
Search for a command to run...
Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun
Abstract
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
One-sentence Summary
The authors present a residual learning framework that reformulates layers to learn residual functions with reference to the layer inputs, facilitating the training of substantially deeper networks that achieve 3.57% error on the ImageNet test set with up to 152 layers, win first place on the ILSVRC 2015 classification task, obtain a 28% relative improvement on the COCO object detection dataset, and secure first places on ILSVRC and COCO 2015 competitions for detection, localization, and segmentation tasks.
Key Contributions
- The paper introduces a residual learning framework that reformulates network layers to learn residual functions with reference to layer inputs rather than unreferenced functions. This approach eases the training of networks that are substantially deeper than those used previously.
- Comprehensive experiments demonstrate that these residual networks are easier to optimize and gain accuracy from considerably increased depth compared to plain networks. The work successfully trains models with up to 152 layers on ImageNet and explores architectures with over 1000 layers on CIFAR-10.
- An ensemble of these residual nets achieves a 3.57% error rate on the ImageNet test set, securing first place in the ILSVRC 2015 classification competition. Additionally, the extremely deep representations lead to a 28% relative improvement on the COCO object detection dataset and top placements in multiple other vision tasks.
Introduction
Deep convolutional neural networks depend on substantial depth to integrate features for excellent image recognition, yet increasing depth often leads to optimization difficulties. Although prior solutions handled gradient issues, deeper networks frequently suffer from a degradation problem where training accuracy decreases as layers are added without overfitting. The authors resolve this by introducing a residual learning framework that explicitly reformulates layers to fit residual functions using identity shortcut connections. This approach simplifies optimization and enables the successful training of extremely deep networks that achieve top performance on the ImageNet dataset.
Method
The core of the proposed method is residual learning, which addresses the degradation problem observed in deep neural networks. Instead of expecting stacked layers to approximate an underlying mapping H(x), the authors explicitly let these layers approximate a residual function F(x):=H(x)−x. The original function then becomes F(x)+x. This reformulation suggests that if identity mappings are optimal, the solver can simply drive the weights of the nonlinear layers toward zero to approach this state, which is easier than learning an identity mapping from scratch.
The fundamental building block of this architecture is defined as y=F(x,{Wi})+x, where x and y are the input and output vectors. The operation F+x is realized via a shortcut connection and element-wise addition, followed by a nonlinearity.
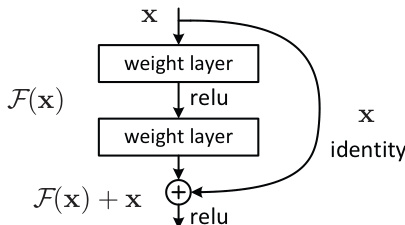
As shown in the figure above, the residual block consists of two weight layers with ReLU activations, where the input x is added to the output of the second weight layer before the final activation. This design introduces neither extra parameters nor computational complexity when the input and output dimensions are equal, allowing for a fair comparison with plain networks.
To evaluate the effectiveness of this design, the authors constructed several network architectures. The figure below illustrates the comparison between a VGG-19 model, a 34-layer plain network, and a 34-layer residual network.
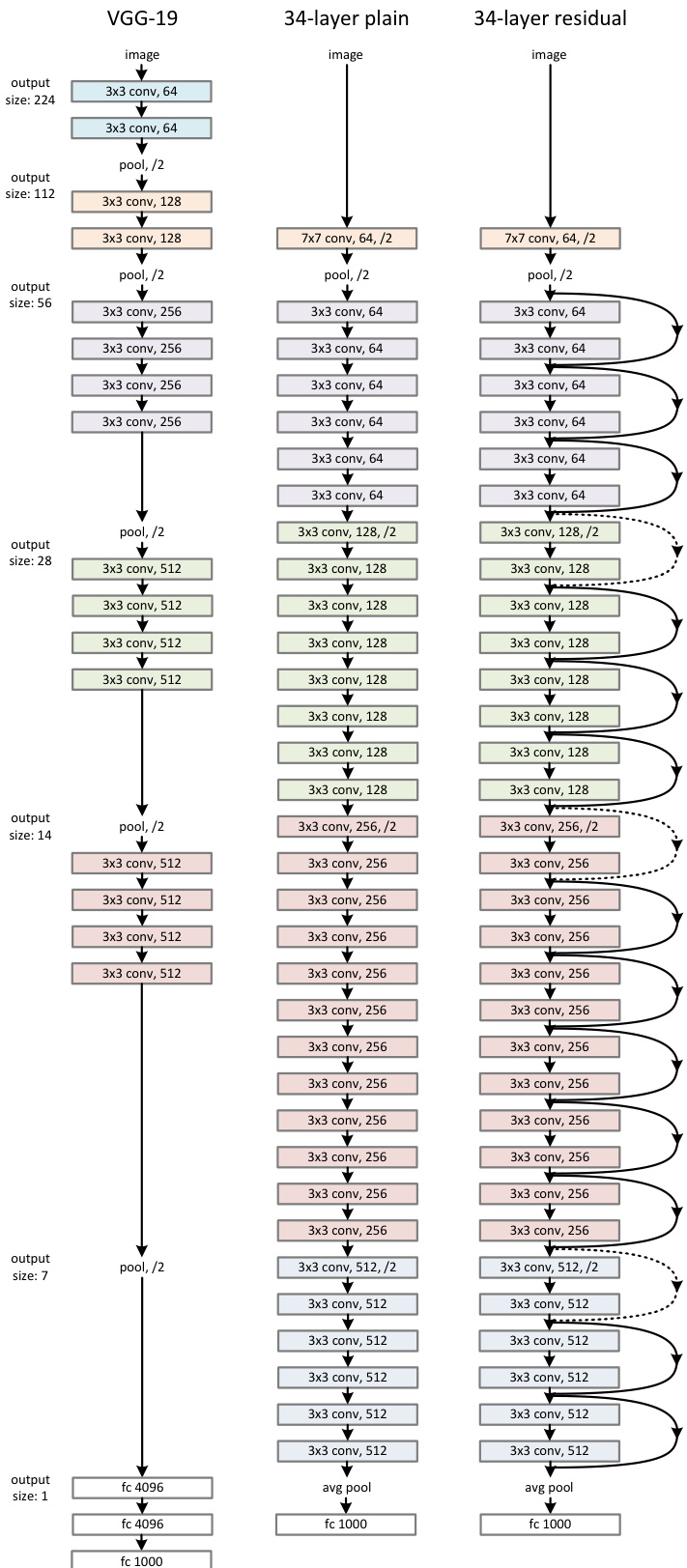
The residual network inserts shortcut connections into the plain network structure. Solid lines represent identity shortcuts used when dimensions match, while dotted lines indicate shortcuts that increase dimensions. When dimensions do not match, such as when changing the number of channels or spatial resolution, the authors employ a projection shortcut using 1×1 convolutions to match dimensions, defined as y=F(x,{Wi})+Wsx. Alternatively, zero-padding can be used for increasing dimensions without extra parameters.
For deeper networks, a bottleneck design is utilized to reduce computational cost. The figure below depicts two specific residual block designs used in the experiments.
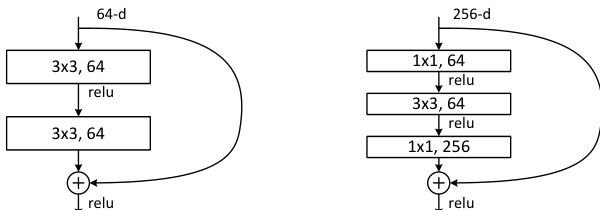
The left block shows a standard residual function with two 3×3 convolutional layers. The right block illustrates a bottleneck design with three layers: a 1×1 convolution to reduce dimensions, a 3×3 convolution, and a 1×1 convolution to restore dimensions. This structure allows the network to maintain depth while managing the number of parameters and FLOPs effectively.
Experiment
The study evaluates residual learning on ImageNet and CIFAR-10 classification tasks by comparing plain deep networks against residual networks with varying depths. Results indicate that plain networks suffer from a degradation problem where increased depth results in higher training error, whereas residual connections mitigate this issue and enable performance improvements through greater depth. Additionally, experiments involving extremely deep models and object detection benchmarks confirm that the method ensures stable optimization and generalizes effectively to other recognition tasks.
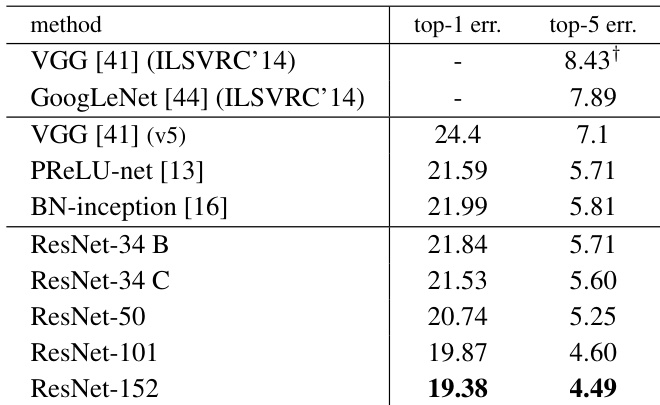
The provided data compares the classification performance of Residual Networks against prior state-of-the-art methods on the ImageNet dataset. The results show that deeper ResNet architectures consistently yield lower error rates, with the 152-layer variant achieving the highest accuracy among all listed models. The 152-layer ResNet model achieves the lowest top-1 and top-5 error rates compared to all other methods. Increasing the depth of the ResNet architecture from 34 to 152 layers leads to a consistent reduction in classification error. The proposed ResNet models outperform established architectures like VGG and GoogLeNet listed in the comparison.
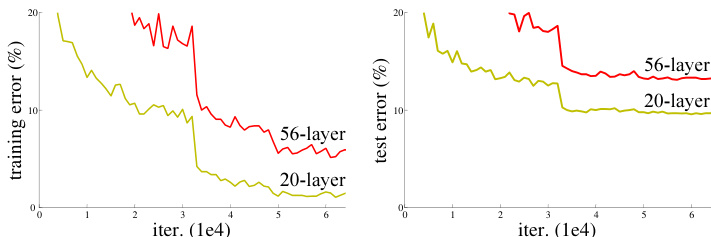
The authors evaluate plain neural networks of varying depths on the CIFAR-10 dataset, specifically comparing a 20-layer network against a 56-layer network. The results illustrate the degradation problem, where the deeper 56-layer network fails to optimize as effectively as the shallower 20-layer network, resulting in significantly higher training and test errors. The deeper 56-layer plain network exhibits consistently higher training error than the shallower 20-layer network throughout the training process. Test error trends mirror the training performance, with the 56-layer model achieving worse generalization accuracy than the 20-layer model. These findings confirm that increasing depth in plain networks leads to optimization difficulties rather than the expected performance gains.
The authors evaluate object detection on the COCO dataset using Faster R-CNN, comparing VGG-16 against ResNet-101. The results demonstrate that the deeper ResNet-101 backbone achieves significantly higher mean Average Precision scores than the VGG-16 baseline. This indicates that the residual learning framework provides superior feature representations for object detection. ResNet-101 outperforms VGG-16 in detection accuracy. Improvements are consistent across different Intersection over Union thresholds. The deeper network architecture leads to better generalization on the dataset.

The the the table displays object detection performance comparing GoogLeNet against the authors' single and ensemble models. The results indicate that the authors' models achieve substantially better detection accuracy than the GoogLeNet baseline, with the ensemble configuration yielding the best overall performance. The authors' ensemble model achieves the highest performance on the test set. Both the single and ensemble models outperform the GoogLeNet baseline. Validation performance is consistently higher than test performance for the authors' models.

The study evaluates object detection performance using the Faster R-CNN framework, comparing VGG-16 and ResNet-101 backbones. The results demonstrate that ResNet-101 consistently outperforms VGG-16 across various object categories. Additionally, training the ResNet-101 model on a larger combined dataset leads to further significant improvements in detection accuracy. ResNet-101 provides superior feature representations compared to VGG-16 for detection tasks. Expanding the training data to include COCO images results in the highest overall mean average precision. The performance gains are consistent across diverse categories such as vehicles, animals, and household objects.

The experiments evaluate Residual Networks against state-of-the-art methods on ImageNet and CIFAR-10 for classification, and on the COCO dataset for object detection using Faster R-CNN. Results indicate that deeper ResNet architectures consistently reduce classification error and avoid the optimization degradation observed in plain networks, while providing superior feature representations for detection compared to VGG and GoogLeNet backbones. Collectively, these findings validate that residual learning effectively mitigates depth-related issues and enhances performance across diverse visual recognition tasks.