Command Palette
Search for a command to run...
You Only Look Once: Unified, Real-Time Object Detection
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon* Santosh Divvala*† Ross Girshick¶ Ali Farhadi*†
Abstract
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is far less likely to predict false detections where nothing exists. Finally, YOLO learns very general representations of objects. It outperforms all other detection methods, including DPM and R-CNN, by a wide margin when generalizing from natural images to artwork on both the Picasso Dataset and the People-Art Dataset.
One-sentence Summary
The authors present YOLO, a unified real-time object detection framework that frames detection as a regression problem using a single neural network rather than repurposing classifiers, processes images at 45 frames per second, and outperforms state-of-the-art systems like R-CNN in generalizing across domains.
Key Contributions
- YOLO frames object detection as a regression problem using a single neural network to predict bounding boxes and class probabilities from full images in one evaluation. The model is trained on a loss function that directly corresponds to detection performance, and the entire model is trained jointly.
- The base YOLO model processes images in real-time at 45 frames per second, while a smaller version named Fast YOLO processes images at 155 frames per second. Fast YOLO achieves double the mAP of other real-time detectors.
- The system learns very general representations of objects and outperforms detection methods like DPM and R-CNN when generalizing from natural images to other domains like artwork. YOLO makes more localization errors but is less likely to predict false positives on background compared to state-of-the-art detection systems.
Introduction
Real-time object detection is critical for autonomous driving and robotics, but traditional methods rely on complex pipelines that repurpose classifiers for detection. These prior systems often suffer from slow inference speeds and a limited ability to reason about global image context. To solve this, the authors present YOLO, which reframes object detection as a single regression problem predicting bounding boxes and class probabilities from full images. This unified architecture allows the network to optimize detection performance end-to-end while achieving real-time speeds of 45 frames per second.
Method
The authors propose a unified approach to object detection by treating it as a single regression problem. Instead of using separate components for region proposal and classification, their network uses features from the entire image to predict each bounding box and class probability simultaneously. This design enables end-to-end training and real-time speeds while maintaining high average precision.
Unified Detection Framework
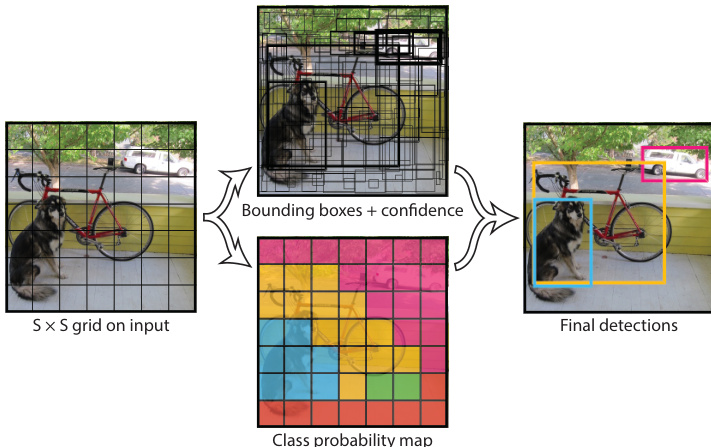
The system divides the input image into an S×S grid. If the center of an object falls into a grid cell, that specific grid cell becomes responsible for detecting that object. Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect the model's certainty that the box contains an object as well as the accuracy of the predicted box. Formally, confidence is defined as Pr(Object)∗IOUpredtruth. If no object exists in the cell, the confidence scores are zero.
Each bounding box prediction consists of five values: x, y, w, h, and confidence. The (x,y) coordinates represent the center of the box relative to the grid cell bounds, while width and height are predicted relative to the whole image. Additionally, each grid cell predicts C conditional class probabilities, Pr(Classi∣Object). At test time, these conditional class probabilities are multiplied by the individual box confidence predictions to produce class-specific confidence scores:
Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruthThese scores encode both the probability of the class appearing in the box and how well the predicted box fits the object. The final output is an S×S×(B∗5+C) tensor.
Network Architecture
The authors implement this model as a convolutional neural network inspired by the GoogLeNet architecture for image classification. The network consists of 24 convolutional layers followed by 2 fully connected layers. Instead of using inception modules, the design utilizes 1×1 reduction layers followed by 3×3 convolutional layers to reduce the feature space.
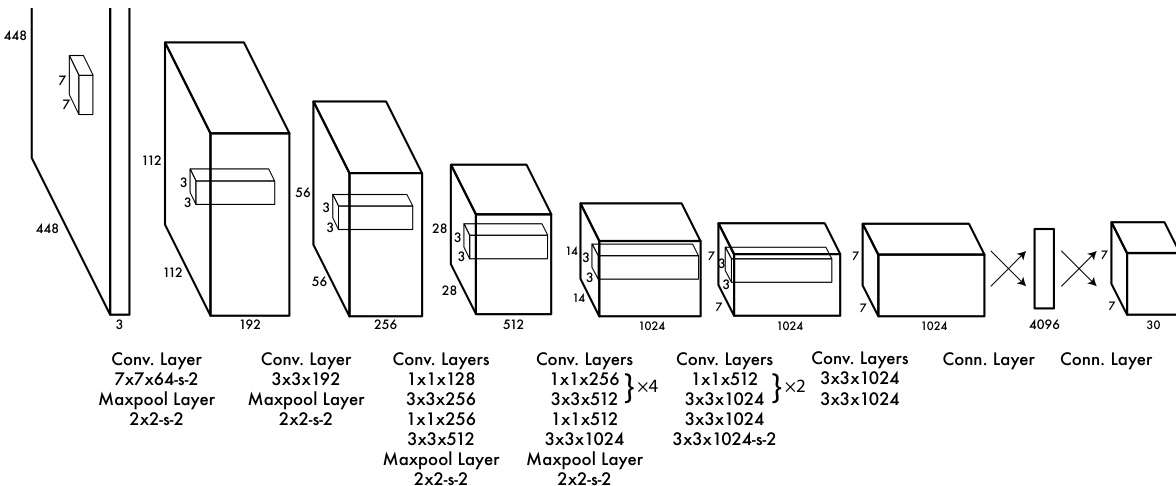
To evaluate the model on the PASCAL VOC dataset, the authors set S=7 and B=2. With 20 labeled classes (C=20), the final prediction tensor dimensions are 7×7×30. A faster version of the model, Fast YOLO, uses fewer convolutional layers (9 instead of 24) and fewer filters to push the boundaries of detection speed.
Training Process
The convolutional layers are pretrained on the ImageNet 1000-class competition dataset using the first 20 convolutional layers followed by an average-pooling layer and a fully connected layer. This pretraining achieves a top-5 accuracy of 88% on the ImageNet 2012 validation set. To adapt the model for detection, the authors add four convolutional layers and two fully connected layers with randomly initialized weights. The input resolution is increased from 224×224 to 448×448 to capture fine-grained visual information.
The network optimizes for sum-squared error in the output. However, to address issues where background cells overpower the gradient from object cells, the loss function is modified with weighting parameters λcoord and λnoobj. The authors set λcoord=5 to increase the loss for bounding box coordinate predictions and λnoobj=0.5 to decrease the loss for confidence predictions in boxes without objects. Furthermore, to handle the fact that small deviations in small boxes matter more than in large boxes, the model predicts the square root of the bounding box width and height.
The multi-part loss function is defined as:
λcoord∑i=0S2∑j=0B1ijobj[(xi−x^i)2+(yi−y^i)2]+λcoord∑i=0S2∑j=0B1ijobj[(wi−w^i)2+(hi−h^i)2]+∑i=0S2∑j=0B1ijobj(Ci−C^i)2+λnoobj∑i=0S2∑j=0B1ijnoobj(Ci−C^i)2+∑i=0S21iobj∑c∈classes(pi(c)−p^i(c))2Training is performed for approximately 135 epochs with a batch size of 64. A specific learning rate schedule is used to prevent divergence: the rate is slowly raised from 10−3 to 10−2, held at 10−2 for 75 epochs, then reduced to 10−3 for 30 epochs, and finally 10−4 for the last 30 epochs. Dropout with a rate of 0.5 is applied after the first connected layer to prevent co-adaptation, and extensive data augmentation involving scaling, translation, and HSV adjustments is employed.
Inference Pipeline
At test time, predicting detections requires only a single network evaluation. The grid design enforces spatial diversity, ensuring that the network predicts one box for each object in most cases. However, for large objects or those near cell borders, multiple cells may predict the same object. Non-maximal suppression is applied to fix these multiple detections, adding approximately 2-3% to the mean average precision (mAP).

Experiment
The experiments evaluate YOLO against other real-time detection systems on PASCAL VOC datasets and analyze error profiles to highlight tradeoffs between localization accuracy and background false positives. Leveraging YOLO's strength in filtering background noise yields a significant performance boost when rescoring Fast R-CNN detections, a gain unattainable through standard model ensembling. Furthermore, tests on artwork datasets and webcam deployment confirm that YOLO generalizes better to new domains than R-CNN variants while maintaining interactive real-time performance.
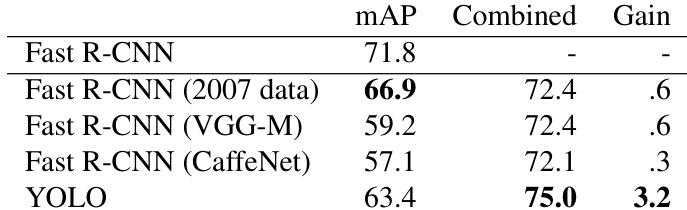
The authors evaluate combining the top-performing Fast R-CNN model with other detection systems on the VOC 2007 dataset to improve accuracy. While combining Fast R-CNN with other variants of itself yields only minor improvements, integrating YOLO leads to a substantial increase in mean average precision. This significant boost is attributed to YOLO's complementary error profile, which helps filter out background false positives common in Fast R-CNN. Combining YOLO with the best Fast R-CNN model provides a significantly larger performance gain compared to ensembling other Fast R-CNN variants. Ensembling different versions of Fast R-CNN using varied data or architectures results in only marginal improvements in accuracy. The performance increase from combining YOLO stems from its ability to correct background false positives that frequently occur in Fast R-CNN predictions.
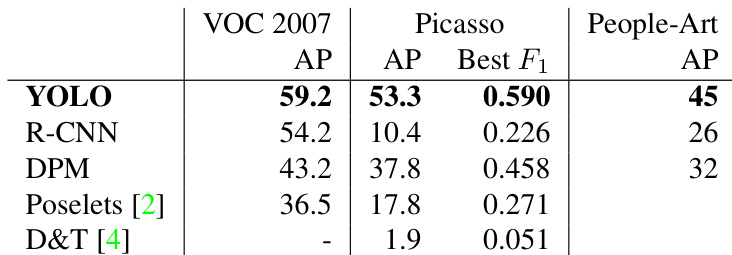
The authors evaluate YOLO against competing real-time and state-of-the-art detection systems on standard benchmarks and artwork datasets to assess generalizability. Results indicate that while R-CNN performs strongly on natural images, it struggles significantly with artwork, whereas YOLO maintains high accuracy across both domains. This demonstrates that YOLO's approach to modeling object structure allows it to transfer effectively to new visual environments where other methods fail. YOLO outperforms R-CNN and DPM on both standard benchmarks and specialized artwork datasets. R-CNN experiences a sharp decline in performance when detecting objects in artwork compared to natural images. YOLO demonstrates superior generalization capabilities by maintaining consistent accuracy across different visual domains.
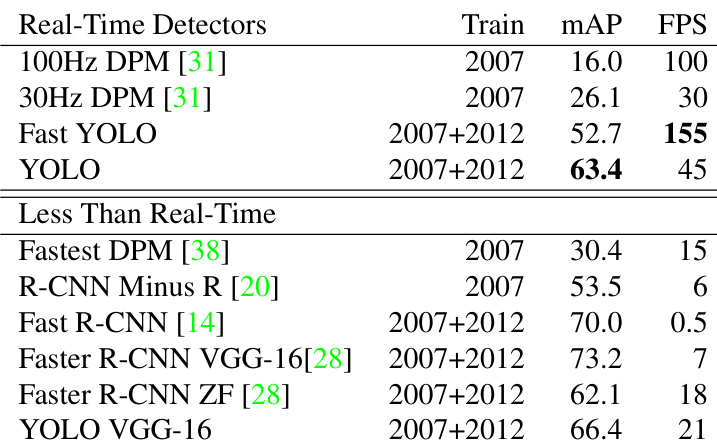
The authors compare YOLO against various real-time and non-real-time object detection systems on the PASCAL VOC 2007 dataset. The results demonstrate that YOLO achieves a strong balance between accuracy and speed, significantly outperforming other real-time detectors like DPM in terms of mean average precision while maintaining high frame rates. While slower methods like Faster R-CNN offer higher accuracy, YOLO remains the only real-time detector with performance competitive with state-of-the-art non-real-time models. Fast YOLO achieves the highest speed among all listed detectors while maintaining significantly higher accuracy than previous real-time methods. Standard YOLO improves upon Fast YOLO's accuracy significantly while still operating well within real-time speeds. Slower models like Faster R-CNN VGG-16 achieve higher accuracy metrics but operate at a fraction of the speed of YOLO.
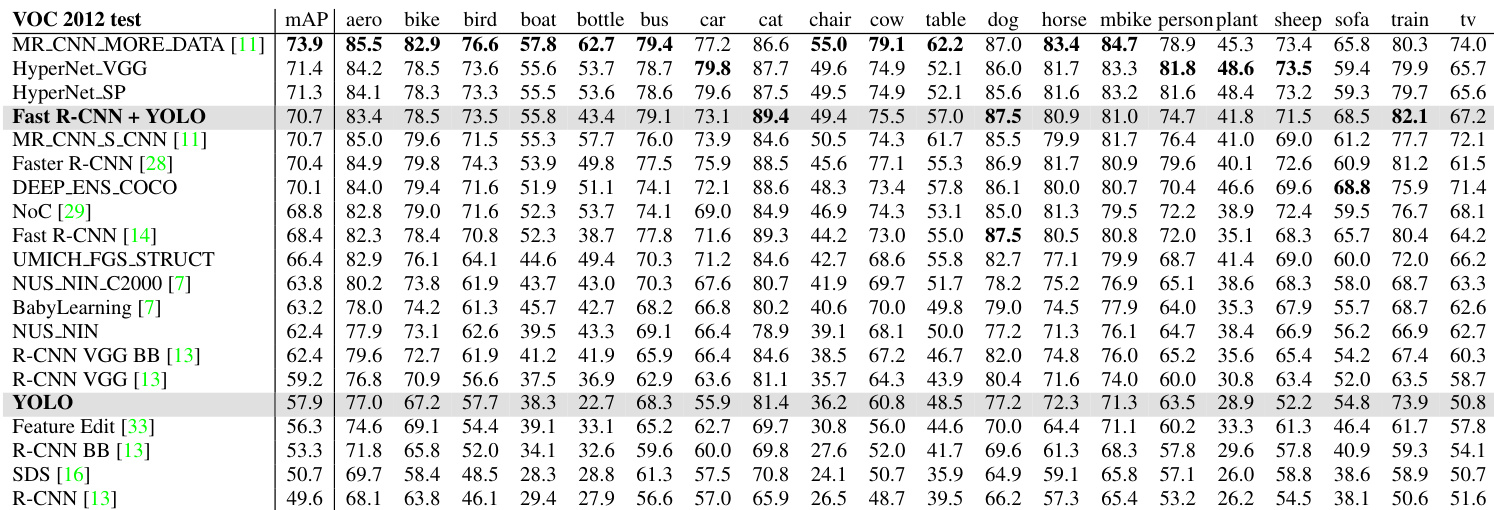
The the the table compares object detection performance on the VOC 2012 test set, highlighting the trade-off between speed and accuracy for different models. While standalone YOLO lags behind state-of-the-art methods in overall accuracy, combining it with Fast R-CNN yields a significant performance improvement over Fast R-CNN alone. The data suggests YOLO is particularly effective for certain categories like cats and trains but struggles more with smaller objects. The combination of Fast R-CNN and YOLO achieves a higher mean average precision than the standalone Fast R-CNN model. YOLO demonstrates stronger detection capabilities for specific categories such as cats and trains compared to its overall average performance. Detection accuracy is notably lower for smaller objects like bottles and sheep compared to larger objects in the dataset.
The authors evaluated YOLO against state-of-the-art detectors on standard VOC benchmarks and artwork datasets to assess accuracy, speed, and generalization capabilities. Results indicate that YOLO maintains consistent performance across different visual domains and achieves a superior balance between real-time speed and accuracy compared to competing systems. Furthermore, combining YOLO with Fast R-CNN yields substantial accuracy gains by correcting background false positives, while standalone YOLO exhibits limitations with smaller objects.