HyperAI
Command Palette
Search for a command to run...
Long-VITA: 수백만 개의 토큰을 활용한 멀티모달 이해 데모
GPU 컴퓨팅 에어드롭
단 20시간의 RTX 5090 컴퓨팅 리소스 $1 (가치 $7)
1. 튜토리얼 소개

Long-VITA는 2025년 2월 텐센트 유투 연구소, 난징대학교, 샤먼대학교가 공동으로 발표한 장문맥 멀티모달 대규모 모델 연구 성과입니다. 이 모델은 짧은 문맥에서도 뛰어난 정확도를 유지하면서 문맥 길이를 100만 토큰까지 확장하여 텍스트와 이미지 등 멀티모달 입력을 효율적으로 처리할 수 있습니다. 관련 논문 제목은 "..."입니다.Long-VITA: 최고 수준의 단기 컨텍스트 정확도를 유지하면서 대규모 멀티모달 모델을 100만 토큰까지 확장".
이 튜토리얼에서는 RTX 4090 그래픽 카드 하나를 사용하고 Long-VITA-16K_HF 모델을 배포합니다.
2. 효과 예시
텍스트 대화
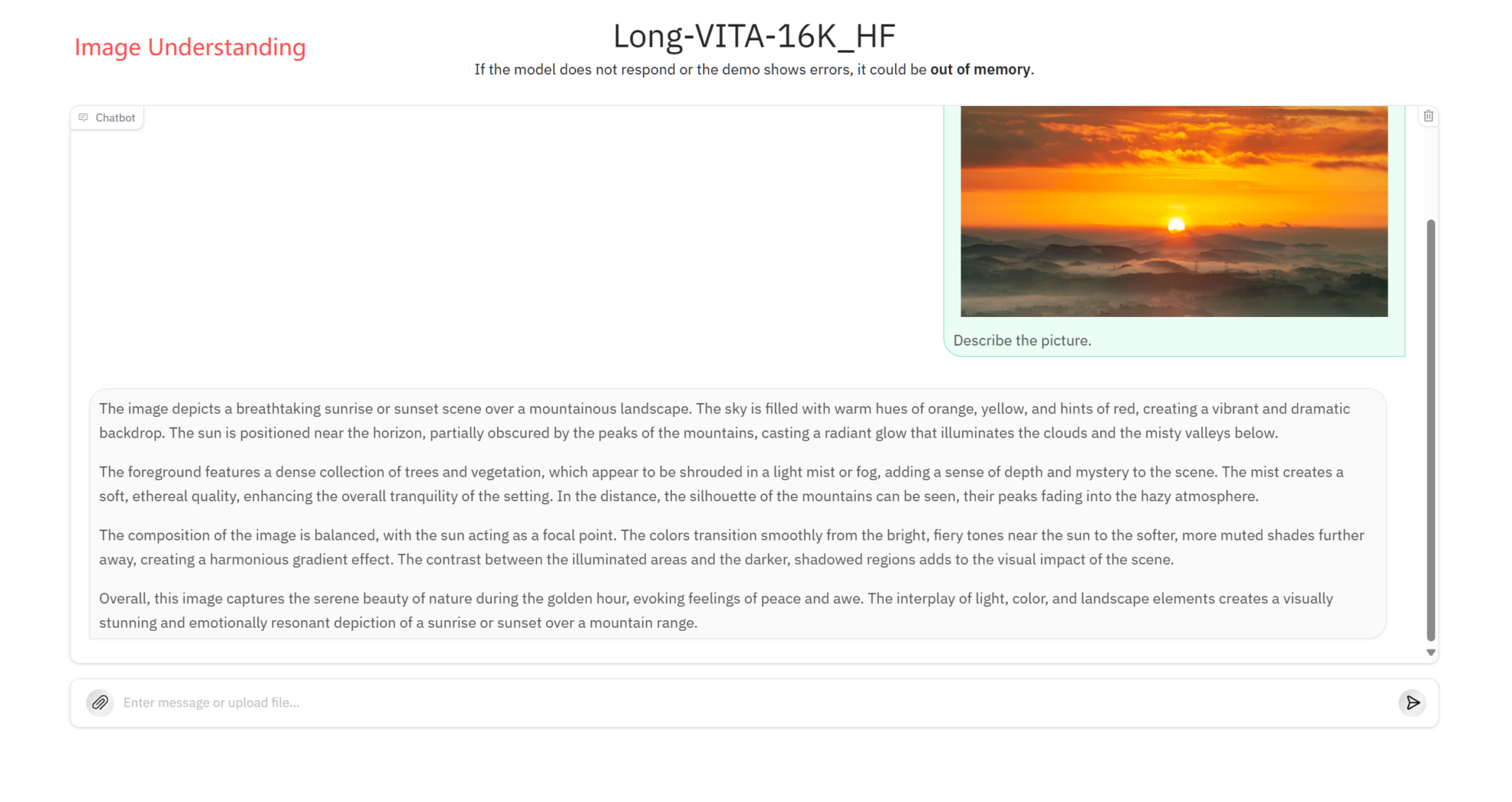
이미지 이해
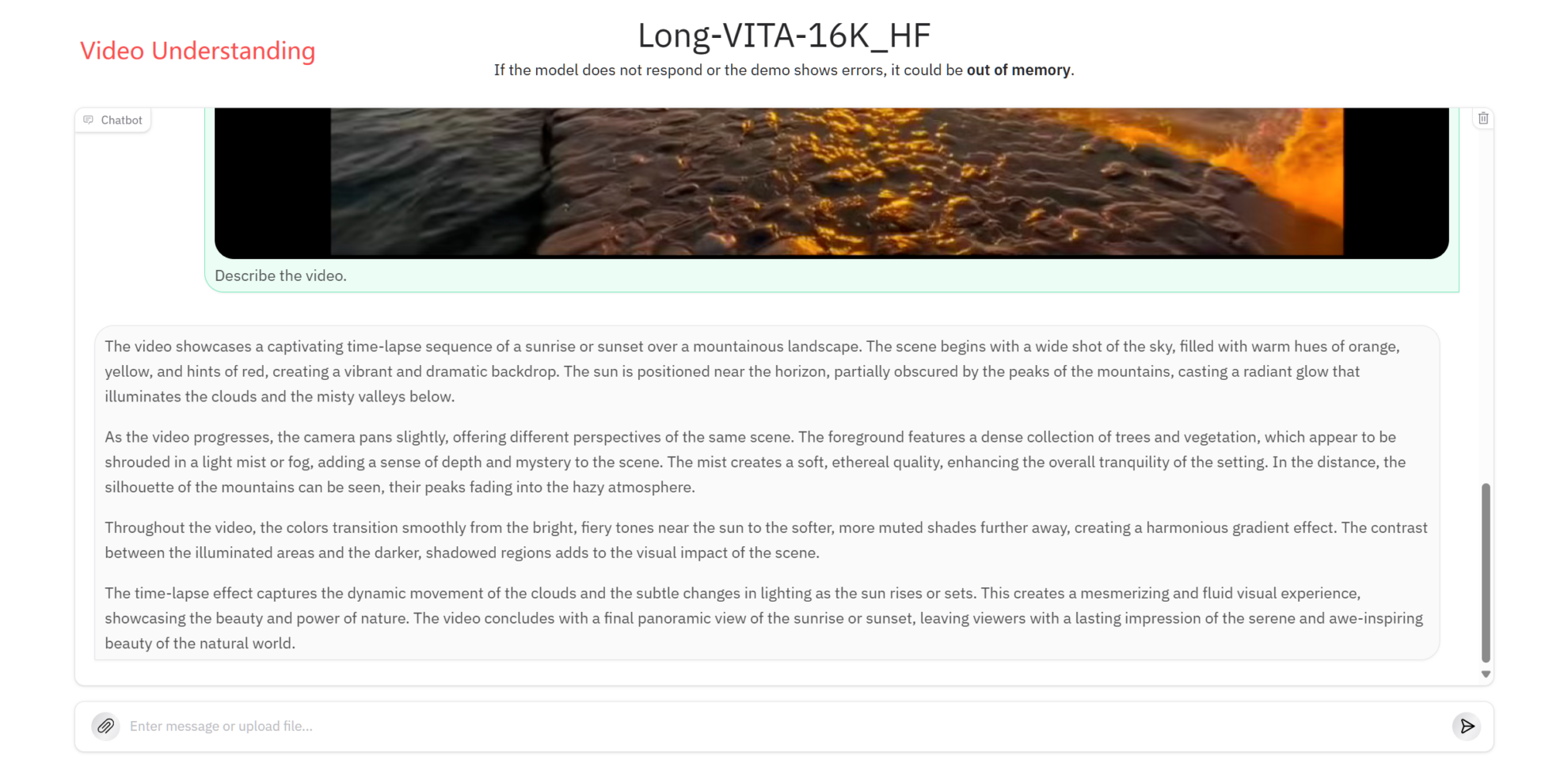
비디오 이해
3. 작업 단계
1. 컨테이너를 시작한 후 API 주소를 클릭하여 Gradio 대화형 인터페이스에 들어갑니다.
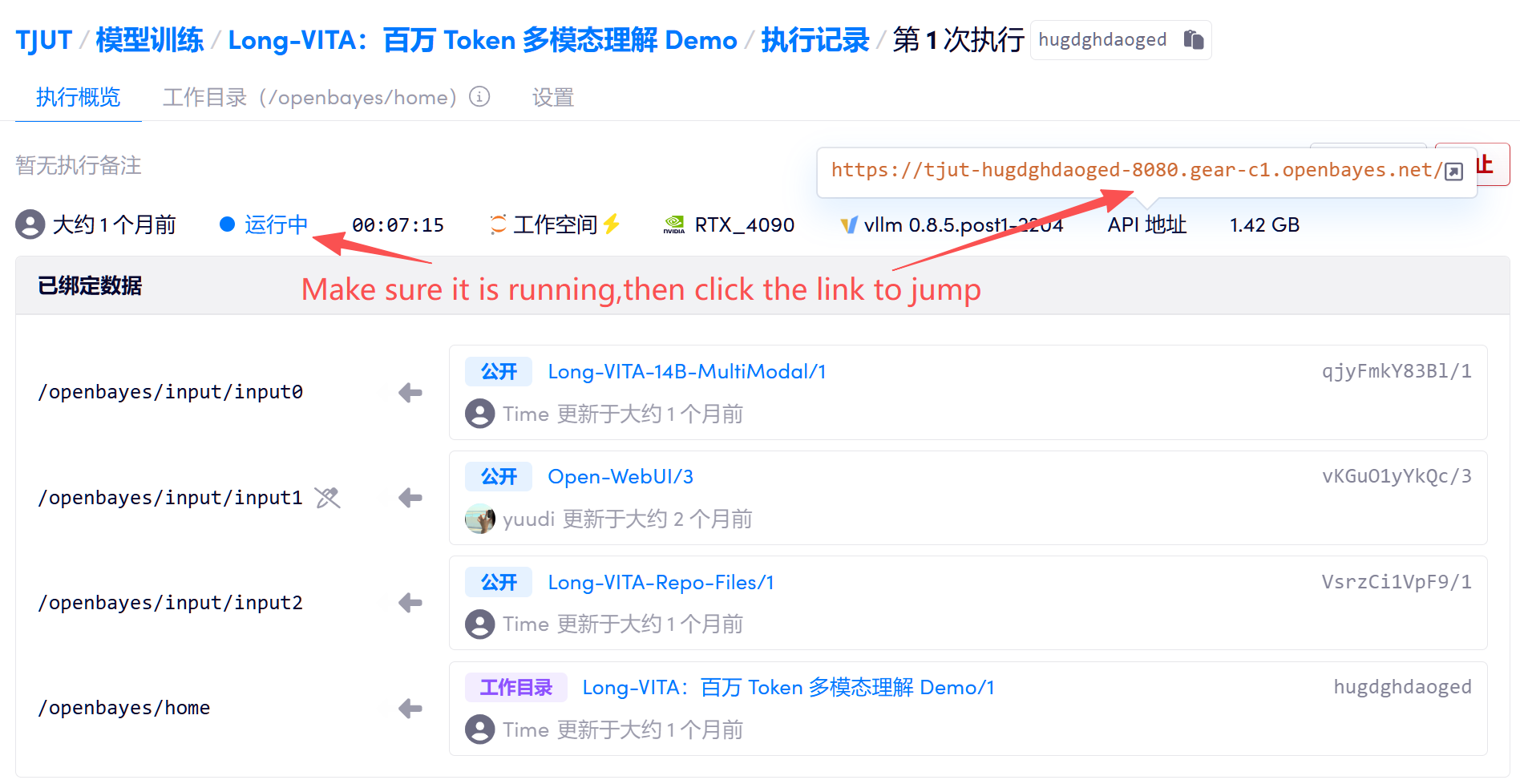
2. 웹페이지에 접속하시면 모델을 이용하실 수 있습니다.
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.
지침
- 긴 컨텍스트 입력의 경우 충분한 비디오 메모리를 확보해야 하며, 매우 큰 텍스트는 일괄적으로 로드하는 것이 좋습니다.
- 추론 지연 시간을 줄이기 위해 이미지 입력 시 한 변의 길이는 2048픽셀 이하인 것이 좋습니다.
- 추론에 실패하면 입력 형식을 확인하거나 입력 길이를 줄여서 다시 시도하십시오.
인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@misc{shen2025longvitascalinglargemultimodal,
title={Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy},
author={Yunhang Shen and Chaoyou Fu and Shaoqi Dong and Xiong Wang and Yi-Fan Zhang and Peixian Chen and Mengdan Zhang and Haoyu Cao and Ke Li and Xiawu Zheng and Yan Zhang and Yiyi Zhou and Ran He and Caifeng Shan and Rongrong Ji and Xing Sun},
year={2025},
eprint={2502.05177},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.05177},
}이 노트북은 커뮤니티 사용자가 기여한 것으로 교육 및 정보 제공 목적으로만 사용됩니다. 저작권 침해와 관련된 콘텐츠가 있는 경우 [email protected]로 문의하시면 신속하게 검토 및 삭제 처리하겠습니다.