HyperAI
Command Palette
Search for a command to run...
POINTS-Reader: 엔드투엔드 증류 없는 아키텍처를 갖춘 가벼운 문서 비전 언어 모델
GPU 컴퓨팅 에어드롭
단 20시간의 RTX 5090 컴퓨팅 리소스 $1 (가치 $7)
1. 튜토리얼 소개

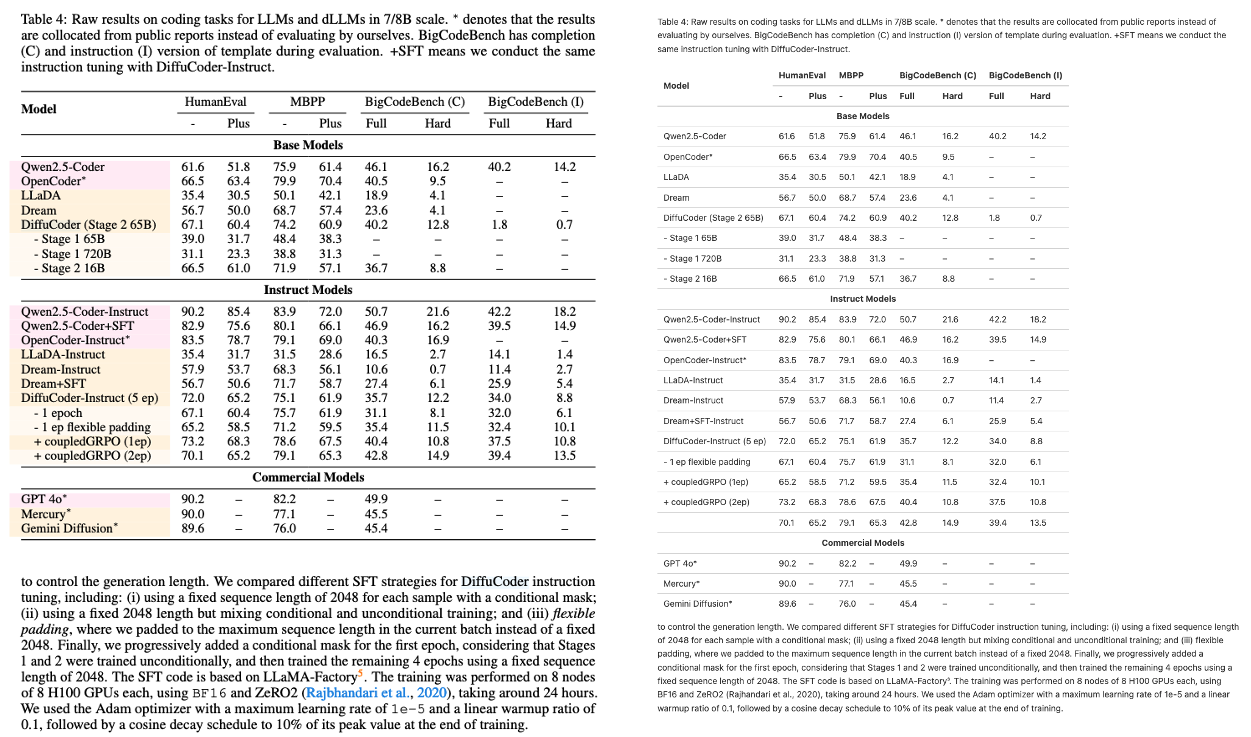
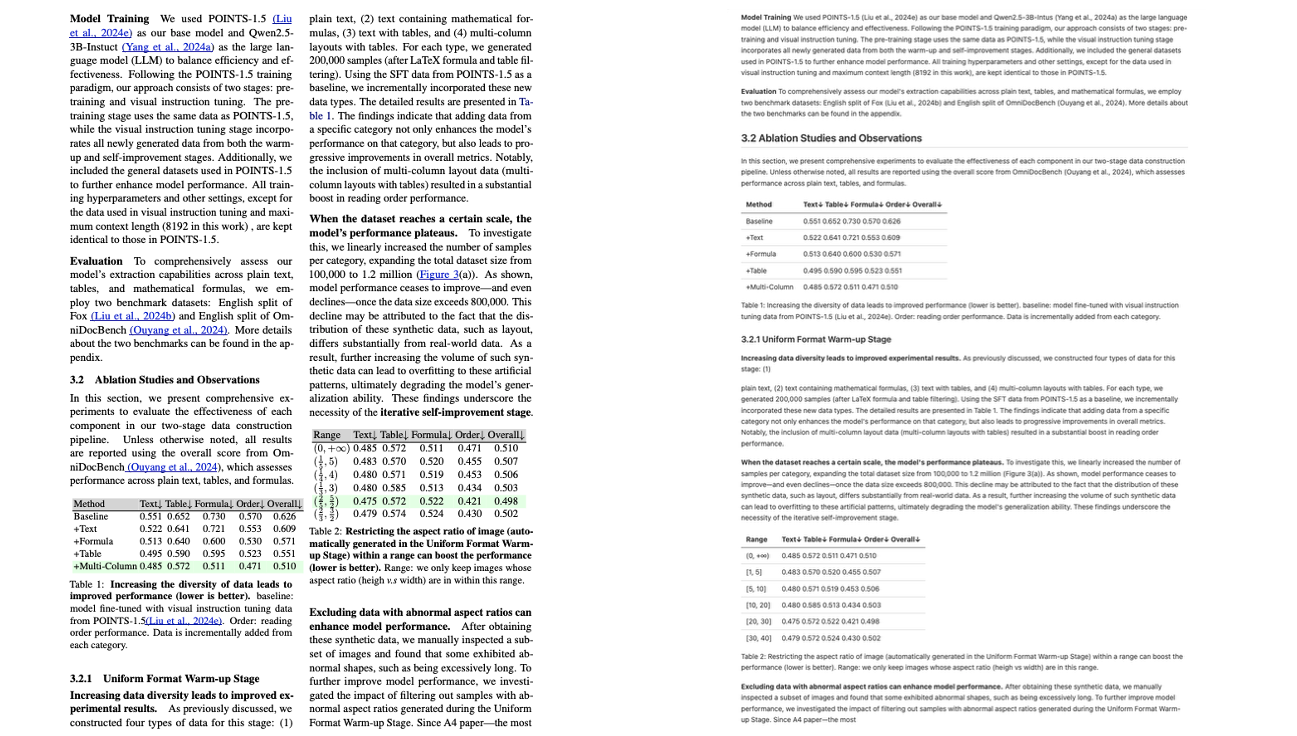
POINTS-Reader는 텐센트, 상하이 자오퉁 대학교, 칭화 대학교가 공동으로 2025년 8월에 출시한 경량 시각 언어 모델(VLM)로, 문서 이미지를 텍스트로 변환하도록 특별히 설계되었습니다. POINTS-Reader는 매개변수 개수를 늘리거나 교사 모델의 "정제"에 의존하지 않습니다. 대신, 2단계 자체 진화 프레임워크를 사용하여 복잡한 중국어 및 영어 문서(표, 수식, 다단 레이아웃 포함)를 고정밀로 처음부터 끝까지 인식하면서도 최소한의 구조를 유지합니다. 관련 연구 논문은 여기에서 확인할 수 있습니다. POINTS-Reader: 문서 변환을 위한 비전-언어 모델의 증류 없는 적응 이 논문은 EMNLP 2025에 채택되어 본 학술대회에서 발표될 예정입니다.
이 튜토리얼에서 사용된 컴퓨팅 리소스는 RTX 4090 카드 1개입니다.
2. 효과 표시
라텍스 포뮬러가 포함된 단일 컬럼

표가 있는 단일 열
라텍스 공식을 사용한 다중 열

표가 있는 다중 열
3. 작업 단계
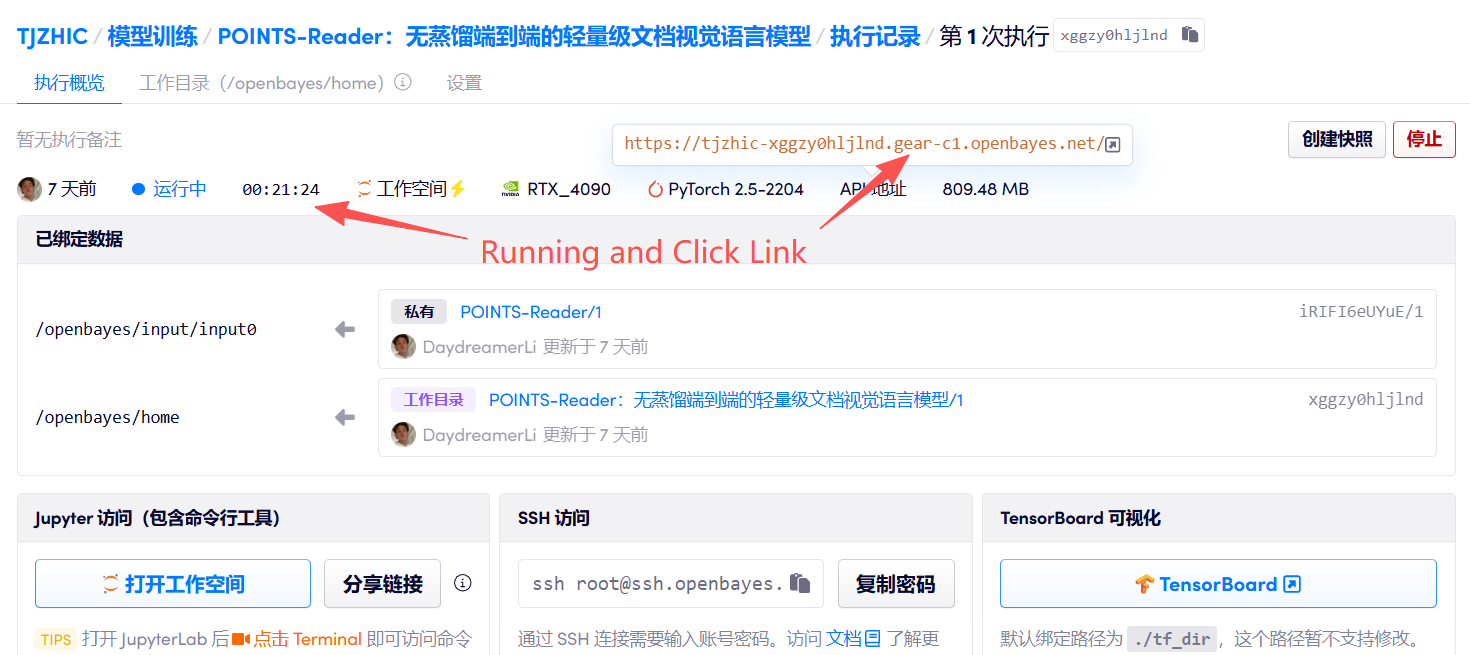
1. 컨테이너를 시작하세요
2. 사용 단계
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.
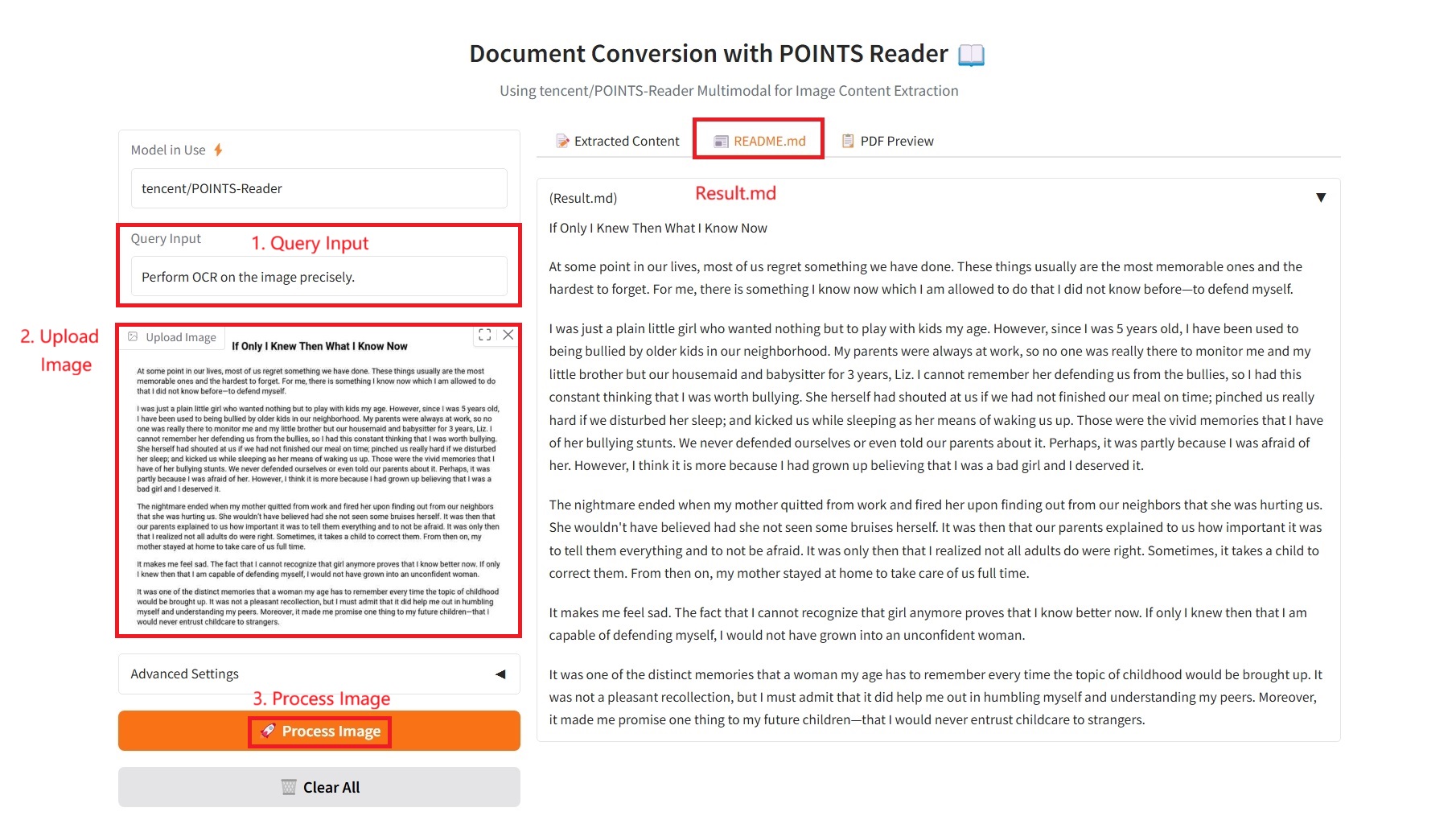
1. 추출된 콘텐츠
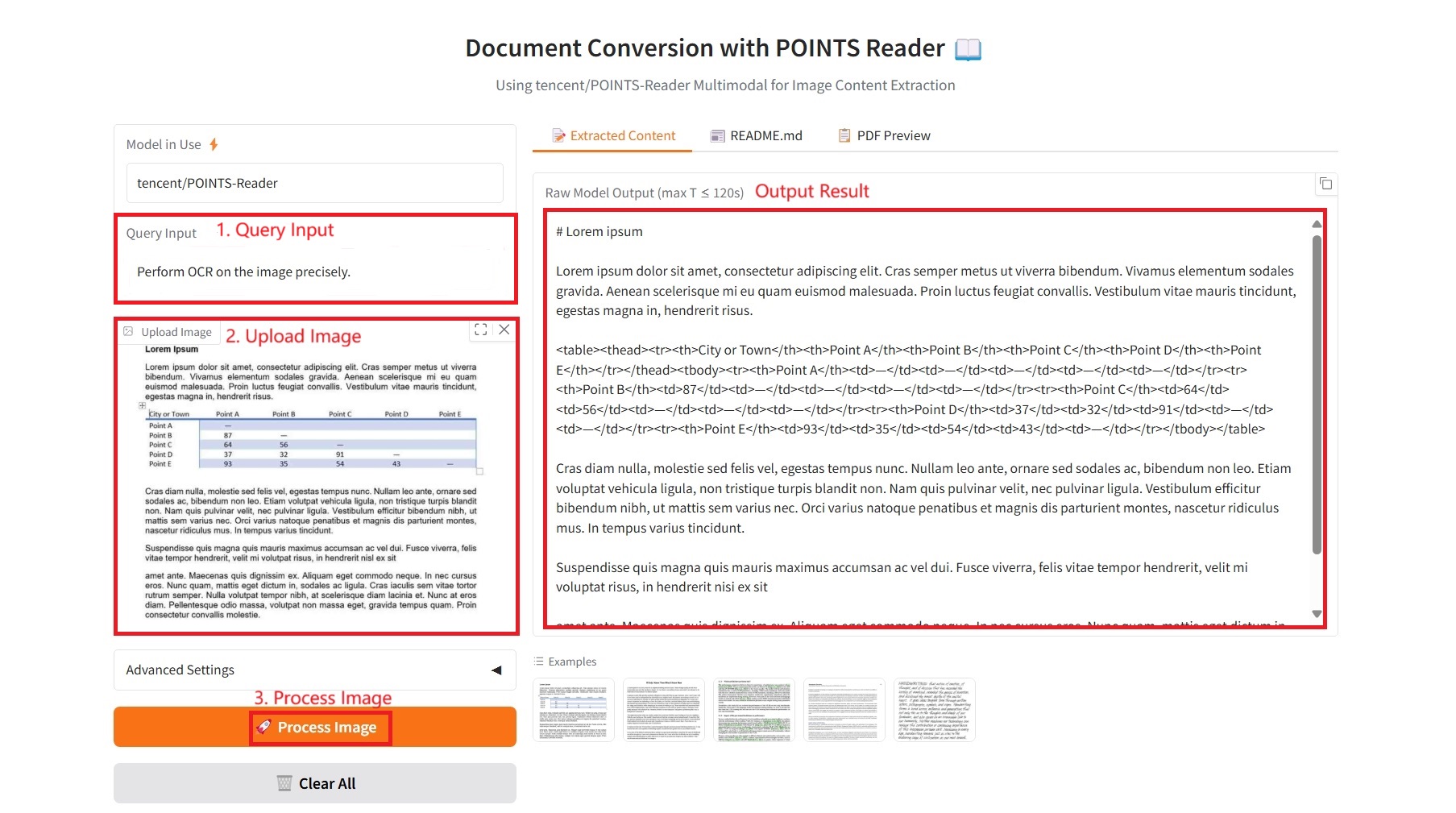
구체적인 매개변수:
- 쿼리 입력: 텍스트 요구 사항을 입력하세요.
- 이미지 확대 계수: 처리 전 이미지 크기를 늘립니다. 작은 텍스트의 OCR을 향상시킬 수 있습니다. 기본값: 1.0 (변경 없음).
- 최대 새 토큰: 생성된 텍스트의 최대 길이 제한으로, 출력 콘텐츠의 단어 수에 대한 상한을 제어합니다.
- Top-p(핵 샘플링): 출력 다양성을 제어하기 위해 샘플링을 위해 누적 확률 p로 최소 단어 집합을 선택하는 핵 샘플링 매개변수입니다.
- Top-k: 확률이 가장 높은 k개의 후보 단어에서 샘플을 추출합니다. 값이 클수록 출력이 더 무작위적이고, 값이 작을수록 출력이 더 확실합니다.
- 온도: 생성된 텍스트의 무작위성을 제어합니다. 값이 높을수록 더 무작위적이고 다양한 출력이 생성되고, 값이 낮을수록 더 명확하고 보수적인 출력이 생성됩니다.
- 반복 페널티: 1.0보다 큰 값을 설정하면 중복 콘텐츠 생성이 줄어듭니다. 값이 클수록 페널티가 커집니다.
- PDF 내보내기 설정:
- 글꼴 크기: PDF의 텍스트 글꼴 크기로, 내보낸 문서의 가독성을 제어합니다.
- 줄 간격: PDF의 문단 간 줄 간격은 문서의 미적 감각과 가독성에 영향을 미칩니다.
- 텍스트 정렬: PDF의 텍스트 정렬을 말하며 왼쪽 정렬, 가운데 정렬, 오른쪽 정렬 또는 양쪽 정렬이 포함됩니다.
- PDF의 이미지 크기: PDF에 포함된 이미지의 크기로, 작음, 보통, 큼 옵션이 있습니다.
2. README.md
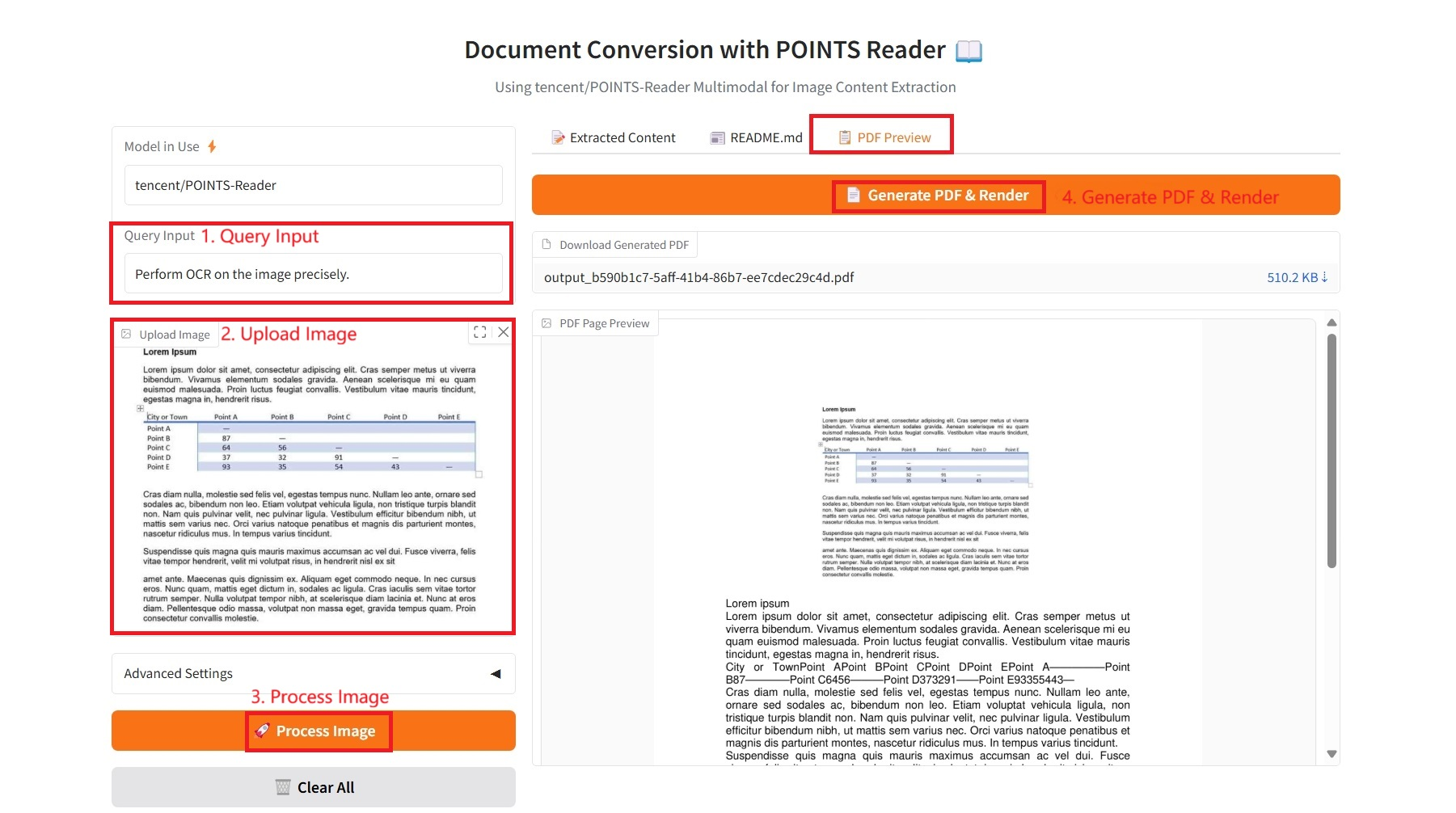
3. PDF 미리보기
인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@article{points-reader, title={POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion}, author={Liu, Yuan and Zhongyin Zhao and Tian, Le and Haicheng Wang and Xubing Ye and Yangxiu You and Zilin Yu and Chuhan Wu and Zhou, Xiao and Yu, Yang and Zhou, Jie}, journal={EMNLP2025}, year={2025} } @article{liu2024points1,
title={POINTS1. 5: Building a Vision-Language Model towards Real World Applications},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Gao, Xinyu and Yu, Kavio and Yu, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2412.08443},
year={2024}
} @article{liu2024points,
title={POINTS: Improving Your Vision-language Model with Affordable Strategies},
author={Liu, Yuan and Zhao, Zhongyin and Zhuang, Ziyuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2409.04828},
year={2024}
}@article{liu2024rethinking,
title={Rethinking Overlooked Aspects in Vision-Language Models},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2405.11850},
year={2024}
}
이 노트북은 커뮤니티 사용자가 기여한 것으로 교육 및 정보 제공 목적으로만 사용됩니다. 저작권 침해와 관련된 콘텐츠가 있는 경우 [email protected]로 문의하시면 신속하게 검토 및 삭제 처리하겠습니다.