HyperAI
Command Palette
Search for a command to run...
Qwen3-Omni-30B-A3B-Captioner: 오디오 설명 대형 모델
GPU 컴퓨팅 에어드롭
단 20시간의 RTX 5090 컴퓨팅 리소스 $1 (가치 $7)
1. 튜토리얼 소개

Qwen3-Omni-30B-A3B-Captioner는 Alibaba Tongyi Qianwen 팀이 2025년 9월에 출시한 대용량 오디오 설명 모델입니다. 이 모델은 별도의 프롬프트 없이 복잡한 음성, 주변 소리, 음악, 영화 및 TV 음향 효과에 대한 정확하고 포괄적인 설명을 자동으로 생성합니다. 화자의 감정, 음악적 요소(스타일 및 악기 등), 그리고 민감한 정보를 식별할 수 있습니다. 오디오 콘텐츠 분석, 보안 감사, 의도 인식, 오디오 편집 및 기타 분야에 적합합니다. 관련 논문은 "Qwen3-Omini 기술 보고서".
이 튜토리얼에서는 리소스로 단일 RTX A6000 카드를 사용합니다.
2. 프로젝트 예시
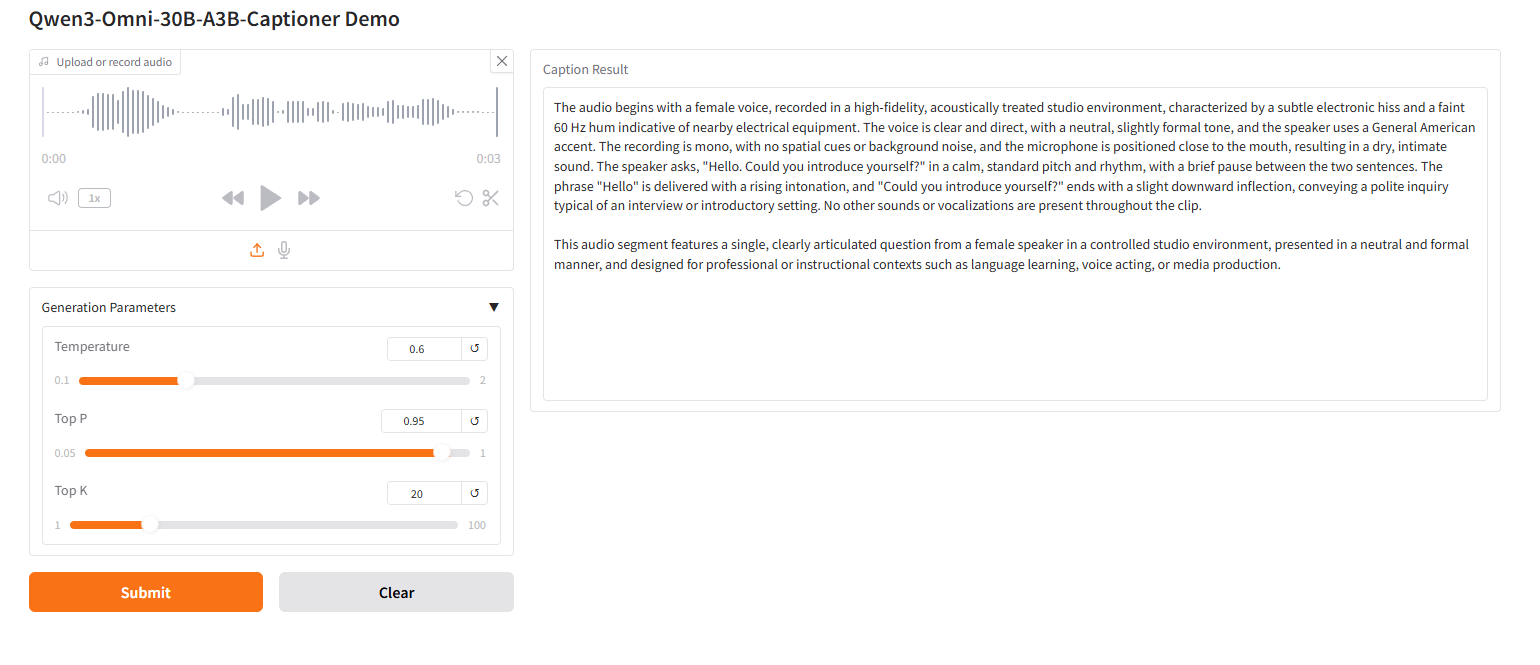
3. 작업 단계
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
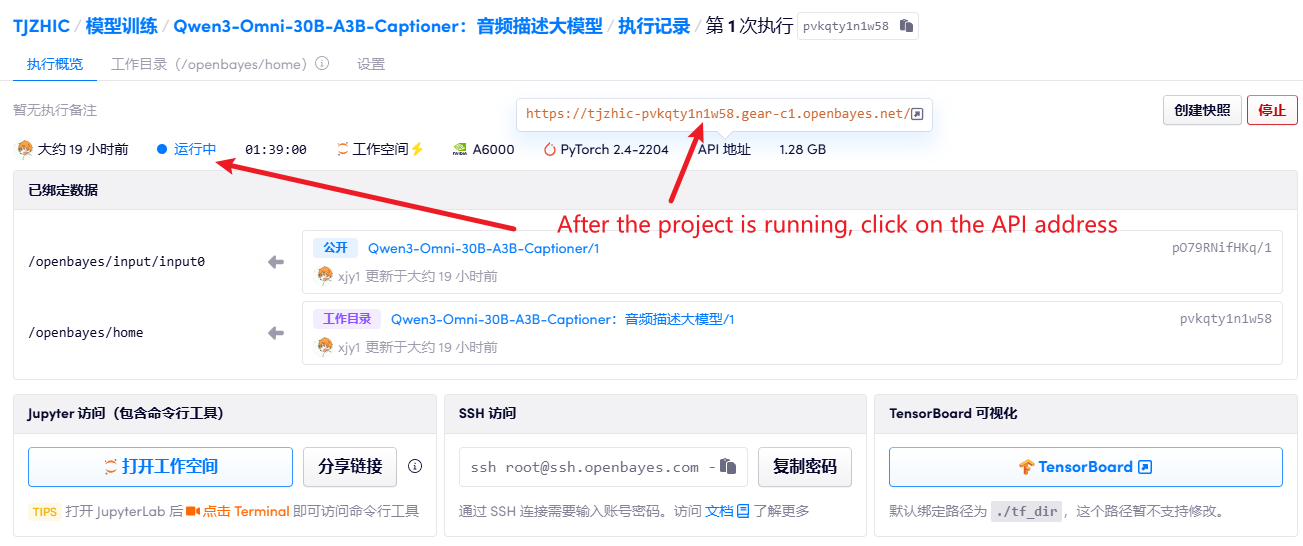
2. 사용 단계
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다. 참고: 오디오 길이는 30초로 제한됩니다. 결과 생성에는 약 3~5분이 소요됩니다.
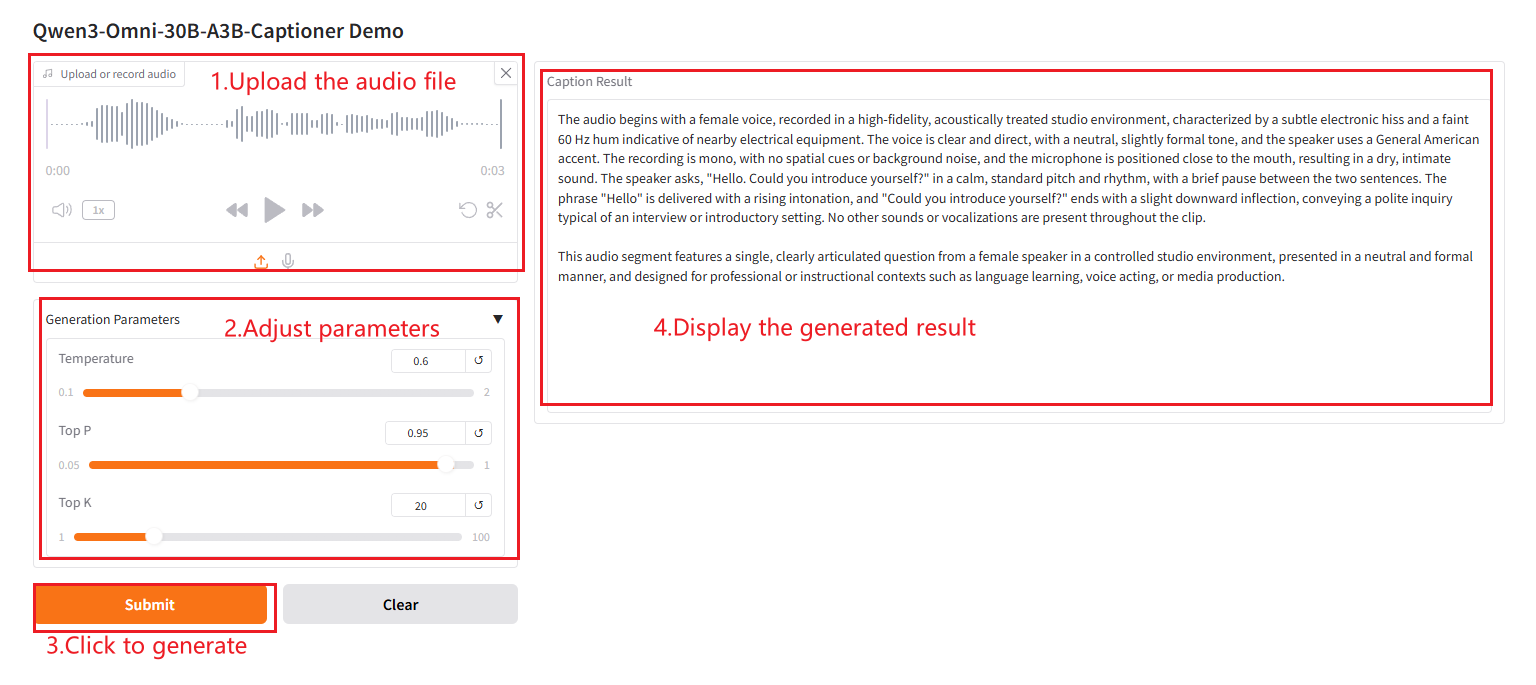
매개변수 설명
- 온도: 값이 작을수록 자막은 더 "보수적"이고 확실합니다. 값이 클수록 자막은 더 무작위적이고 혁신적입니다.
- 탑-피: 확률이 p로 누적되는 "점수가 높은 단어" 중에서만 선택합니다. p가 작을수록 후보가 적고 텍스트가 더 보수적입니다.
- 탑케이: 확률이 가장 높은 k개의 단어만 유지합니다. k가 작을수록 후보가 적고 텍스트가 더 보수적입니다.
이 노트북은 커뮤니티 사용자가 기여한 것으로 교육 및 정보 제공 목적으로만 사용됩니다. 저작권 침해와 관련된 콘텐츠가 있는 경우 [email protected]로 문의하시면 신속하게 검토 및 삭제 처리하겠습니다.