Command Palette
Search for a command to run...
Sa2VA: 이미지와 비디오에 대한 고밀도 지각적 이해를 향하여
GPU 컴퓨팅 에어드롭
1. 튜토리얼 소개

UC Merced, ByteDance Seed, 우한대학교, 베이징대학교 연구팀이 공동 개발한 Sa2VA가 2025년 1월 7일에 공개되었습니다. Sa2VA는 이미지와 비디오의 밀집된 지각적 이해를 위한 최초의 통합 모델입니다. 기존의 멀티모달 대규모 언어 모델은 일반적으로 특정 모달리티와 작업에 국한되는 반면, Sa2VA는 대수적 분할 및 대화 처리를 포함한 광범위한 이미지 및 비디오 작업을 지원하며, 최소한의 단일 명령 미세 조정만으로 작동합니다. 관련 논문 결과는 다음과 같습니다. Sa2VA: SAM2와 LLaVA를 결합하여 이미지와 비디오에 대한 깊이 있는 이해를 도모합니다. .
이 튜토리얼에서는 단일 카드 A6000에 대한 리소스를 사용합니다.
2. 프로젝트 예시



3. 작업 단계
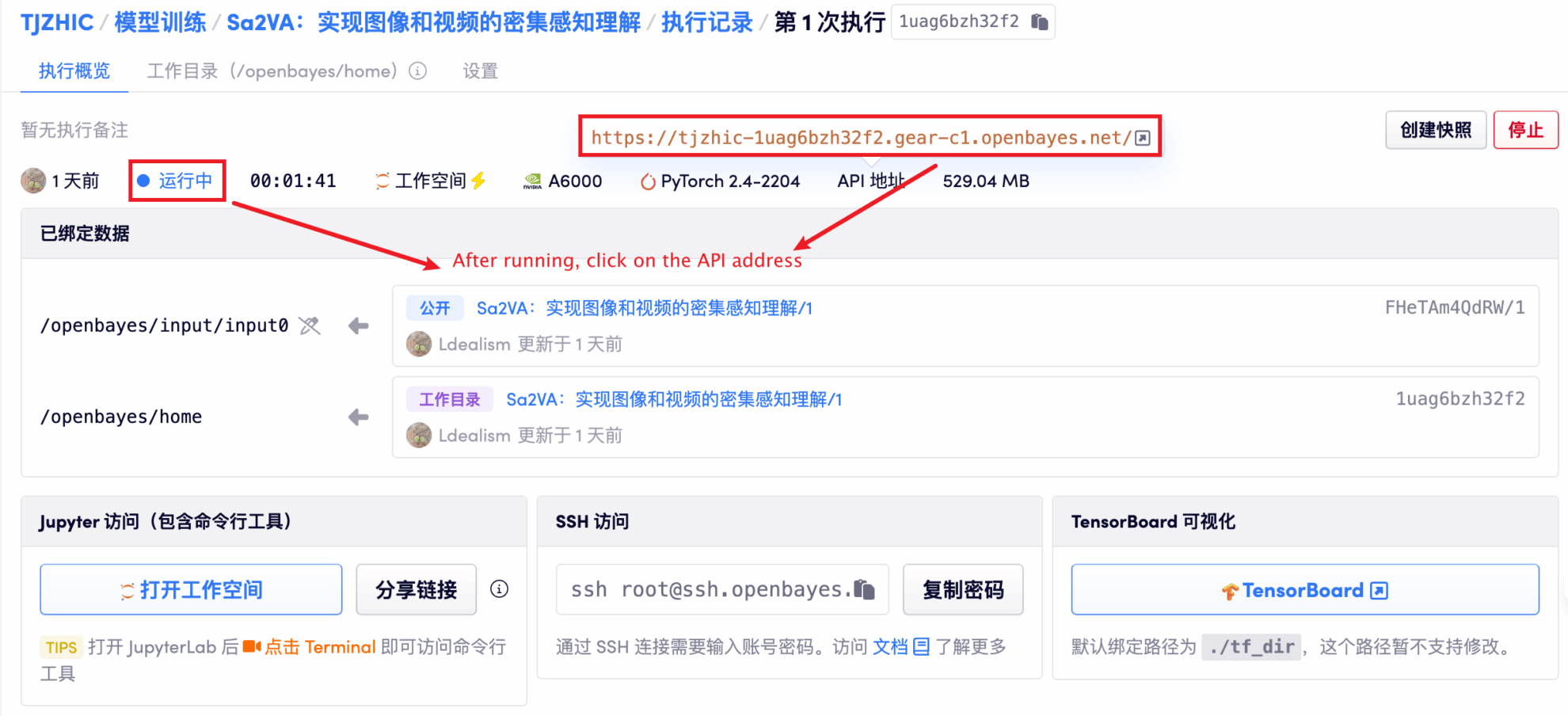
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 1~2분 정도 기다리신 후 페이지를 새로고침해 주세요.
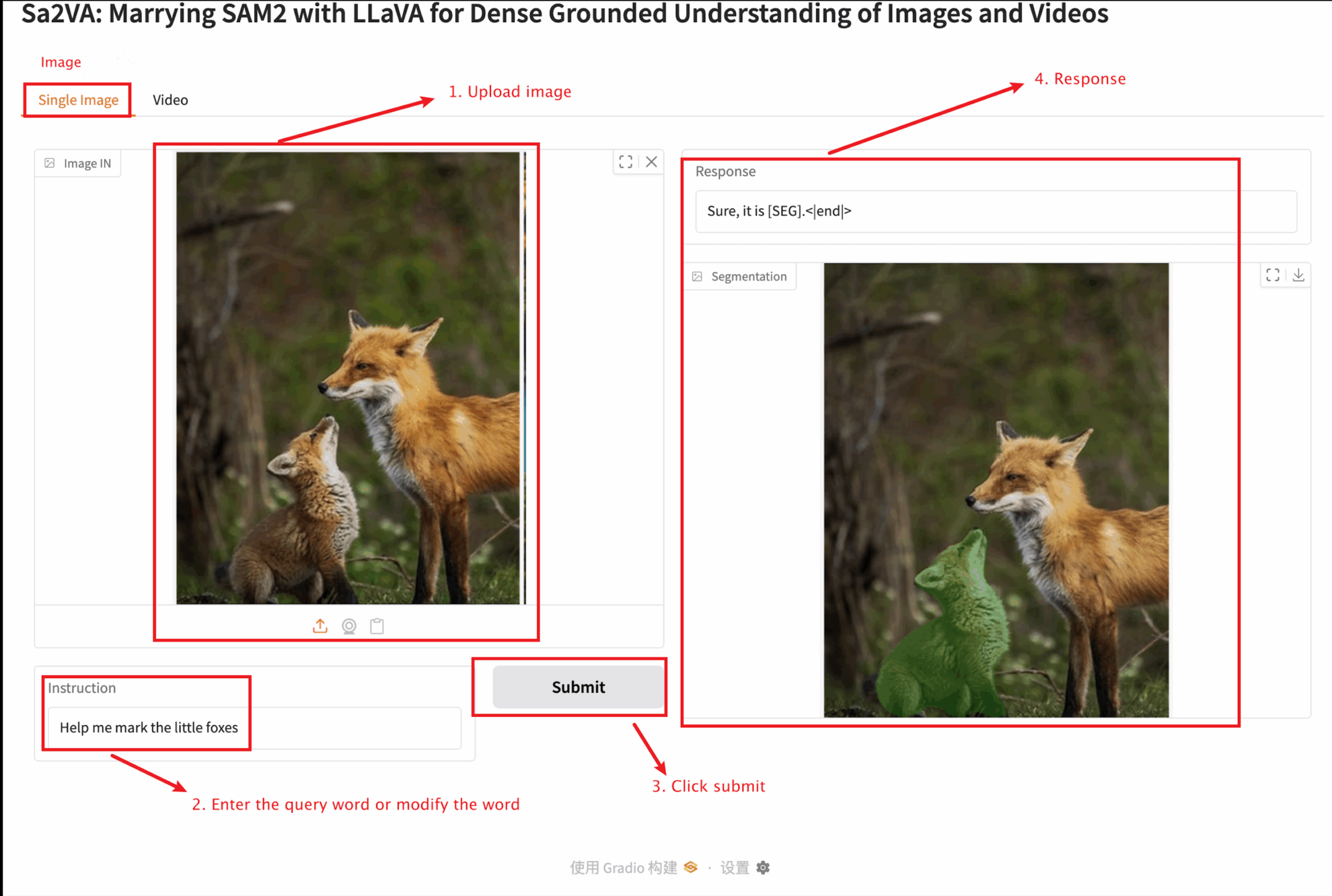
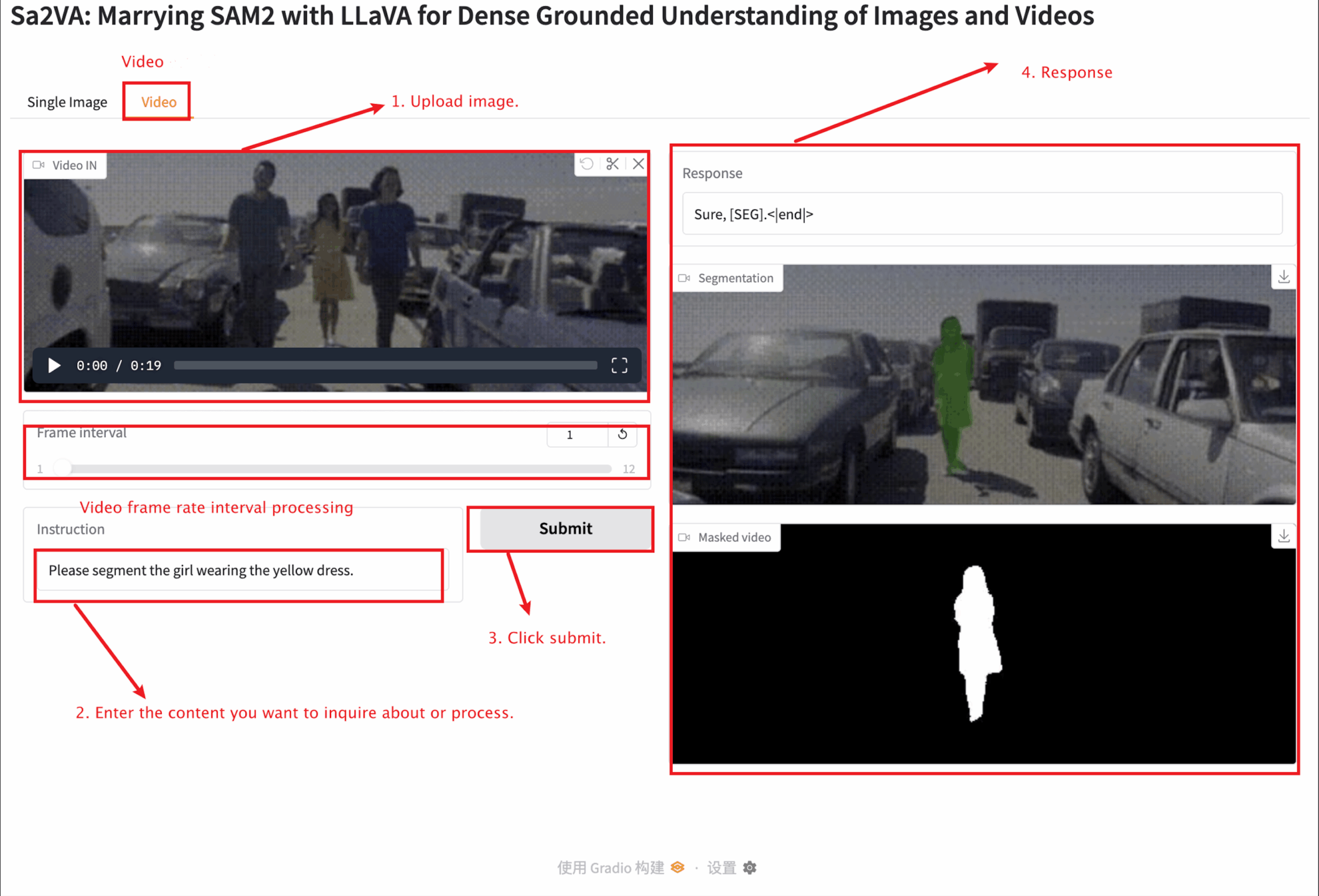
2. 웹 페이지에 접속하면 모델과 상호작용이 가능합니다.
이 튜토리얼에서는 단일 이미지 모듈과 비디오 모듈이라는 두 가지 모듈 테스트를 제공합니다.
업로드된 이미지 크기는 10MB를 넘을 수 없고, 업로드된 비디오 길이는 1분을 넘을 수 없으며, 비디오 크기는 50MB를 넘을 수 없습니다. 이보다 클 경우 모델이 느리게 실행되거나 오류가 보고될 수 있습니다.
중요한 매개변수 설명:
단일 이미지
동영상
4. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓

V. 인용 정보
Github 사용자에게 감사드립니다 장준창 이 튜토리얼을 배포하기 위한 프로젝트 참조 정보는 다음과 같습니다.
@article{pixel_sail,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Zhang, Tao and Li, Xiangtai and Huang, Zilong and Li, Yanwei and Lei, Weixian and Deng, Xueqing and Chen, Shihao and Ji, Shunping and and Feng, Jiashi},
journal={arXiv},
year={2025}
}
@article{sa2va,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Yuan, Haobo and Li, Xiangtai and Zhang, Tao and Huang, Zilong and Xu, Shilin and Ji, Shunping and Tong, Yunhai and Qi, Lu and Feng, Jiashi and Yang, Ming-Hsuan},
journal={arXiv},
year={2025}
}