HyperAI
Command Palette
Search for a command to run...
PaddleOCR-VL: マルチモーダルドキュメント解析
1. チュートリアルの概要

PaddleOCR-VLは、文書解析タスク向けに特別に設計された最先端(SOTA)かつリソース効率の高いモデルです。その中核コンポーネントは、NaViTスタイルの動的解像度のビジュアルエンコーダーとERNIE-4.5-0.3B言語モデルを統合し、正確な要素認識を可能にするコンパクトで強力なビジュアル言語モデル(VLM)であるPaddleOCR-VL-0.9Bです。この革新的なモデルは、109の言語を効率的にサポートし、テキスト、表、数式、グラフなどの複雑な要素の認識に優れており、リソース消費を極めて低く抑えています。広く使用されている公開ベンチマークと社内ベンチマークによる包括的な評価を通じて、PaddleOCR-VLはページレベルの文書解析と要素レベルの認識タスクの両方でSOTAパフォーマンスを達成しています。このモデルは既存のソリューションを大幅に上回り、トップレベルのビジュアル言語モデルに対して強力な競争力を示し、高速な推論速度を提供します。これらの利点により、実世界での展開に非常に適しています。関連する研究論文もご覧いただけます。 PaddleOCR-VL: 0.9B の超コンパクトな視覚言語モデルによる多言語ドキュメント解析の強化 。
このチュートリアルでは、コンピューティング リソースとして単一の RTX 5090 グラフィック カードを使用します。
2. 効果例
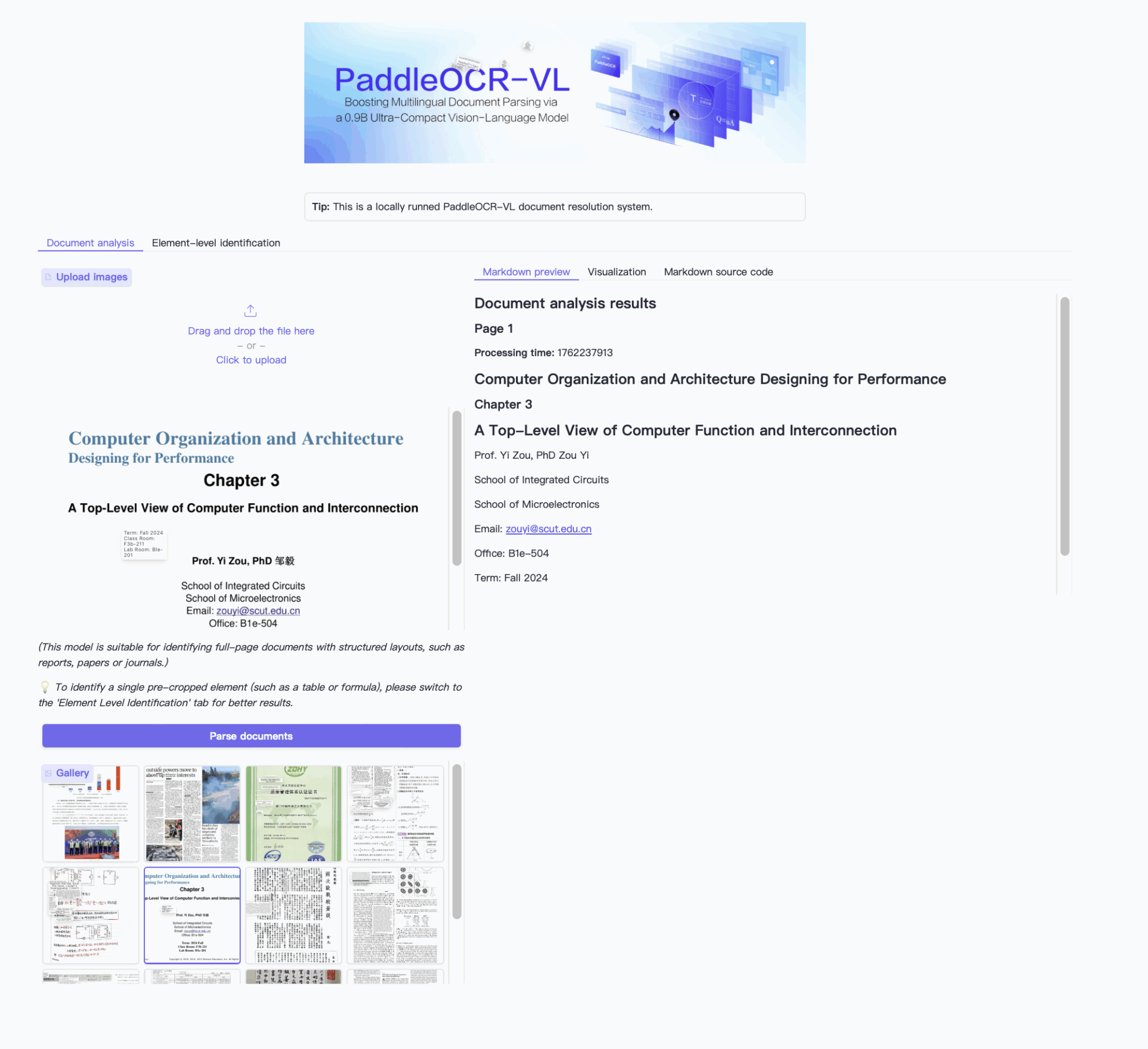
3. 操作手順
1. コンテナを起動します
2. Web ページに入ると、モデルと会話を開始できます。
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
利用手順
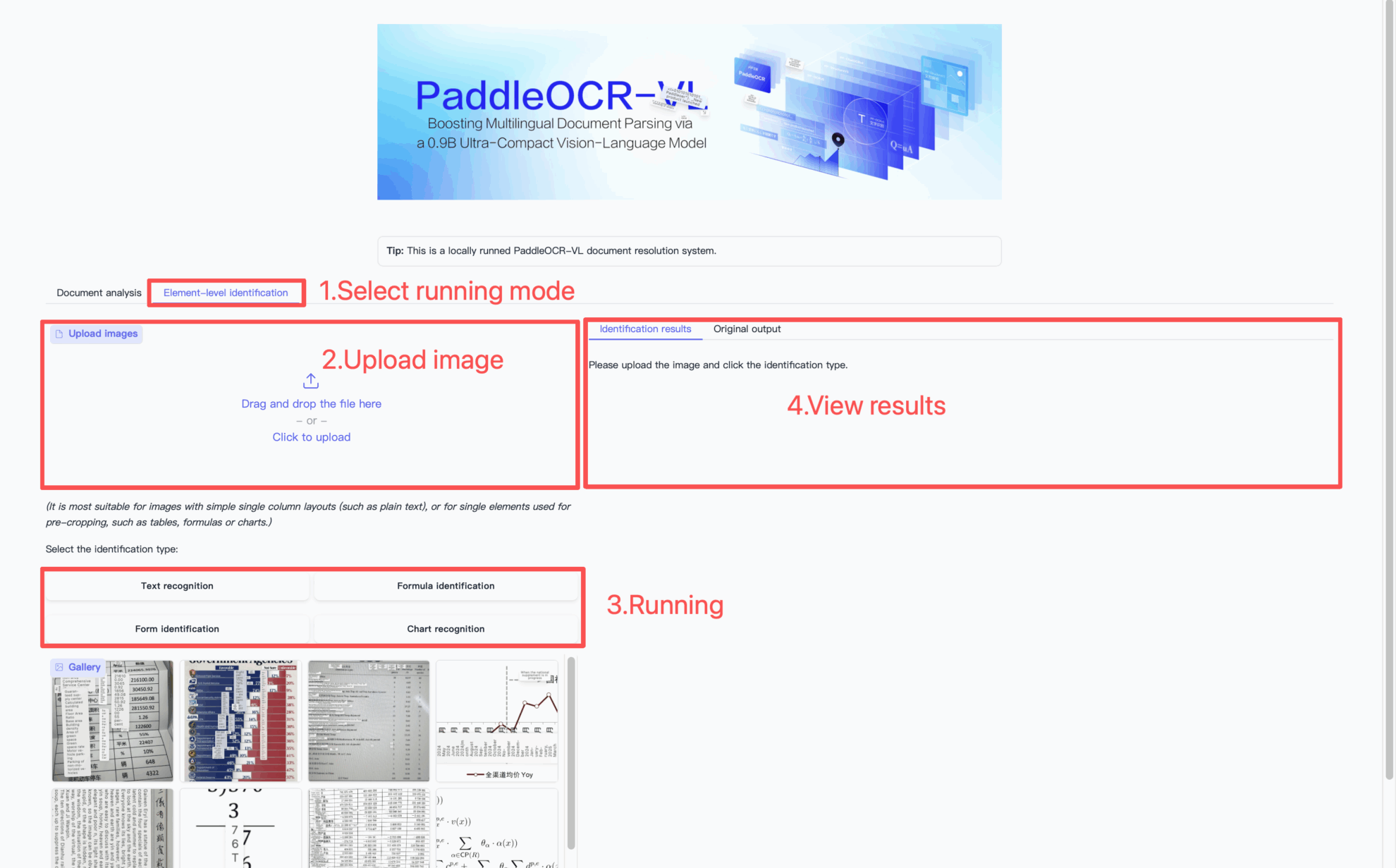
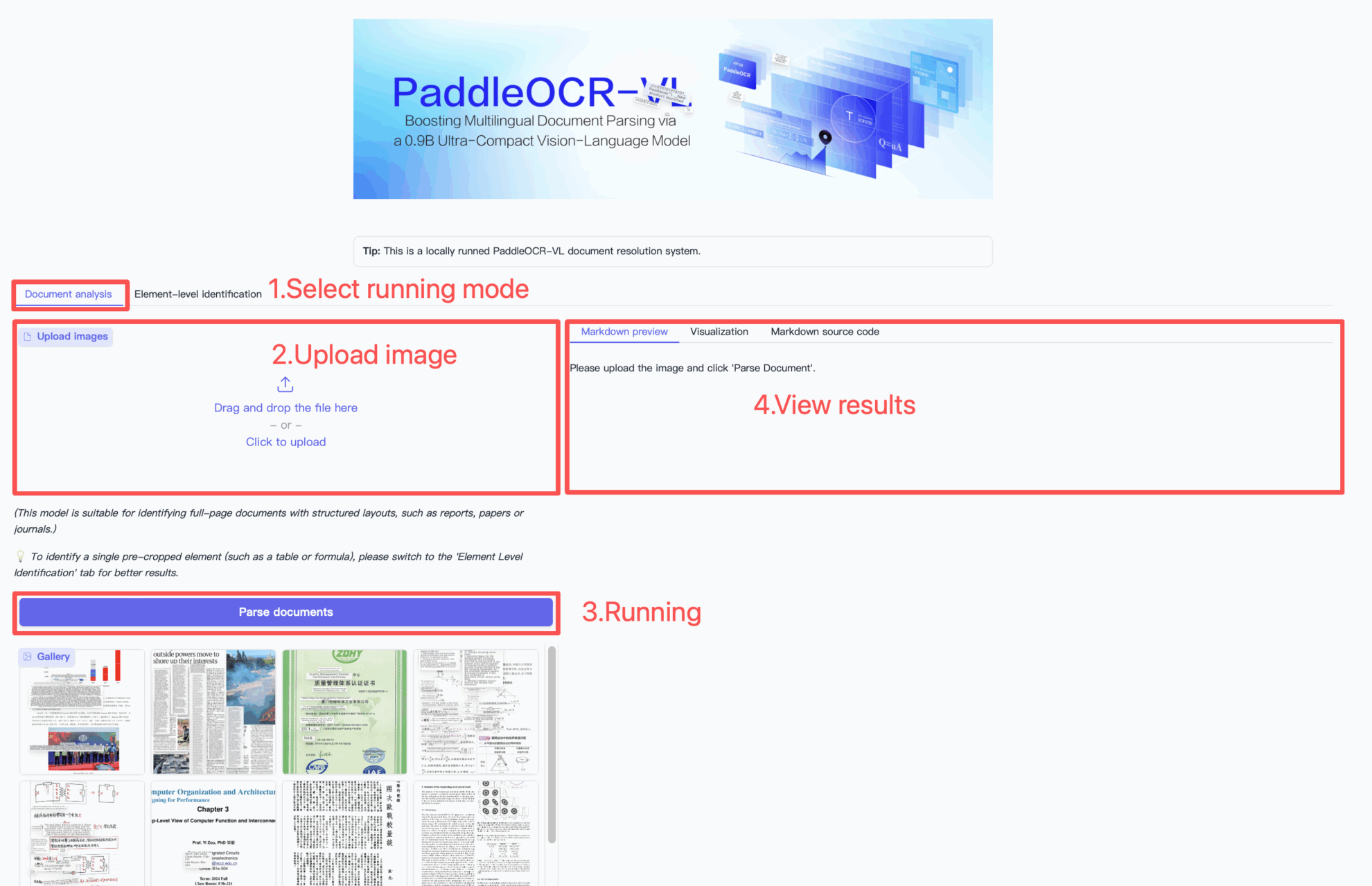
引用情報
@misc{cui2025paddleocrvlboostingmultilingualdocument,
title={PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Handong Zheng and Jing Zhang and Jun Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2025},
eprint={2510.14528},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.14528},
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。