HyperAI
Command Palette
Search for a command to run...
dots.ocr: 多言語文書解析モデル
1. チュートリアルの概要
dots.ocrは、小紅書のhiラボが2025年8月にリリースした多言語文書レイアウト解析モデルです。17億パラメータの視覚言語モデル(VLM)をベースに、レイアウト検出とコンテンツ認識を統合し、良好な読み順序を維持します。小型モデルでありながら最先端の性能を発揮し、OmniDocBenchなどのベンチマークで優れた結果を達成しています。数式認識性能はDoubao-1.5やGemini2.5-Proといった大規模モデルに匹敵し、少数言語の解析において大きな優位性を示しています。dots.ocrはシンプルで効率的なアーキテクチャを提供し、入力プロンプトを変更するだけでタスクを切り替えることができます。推論速度が速いため、さまざまな文書解析シナリオに適しています。
このチュートリアルでは、リソースとして単一の RTX 5090 カードを使用します。
2. プロジェクト例
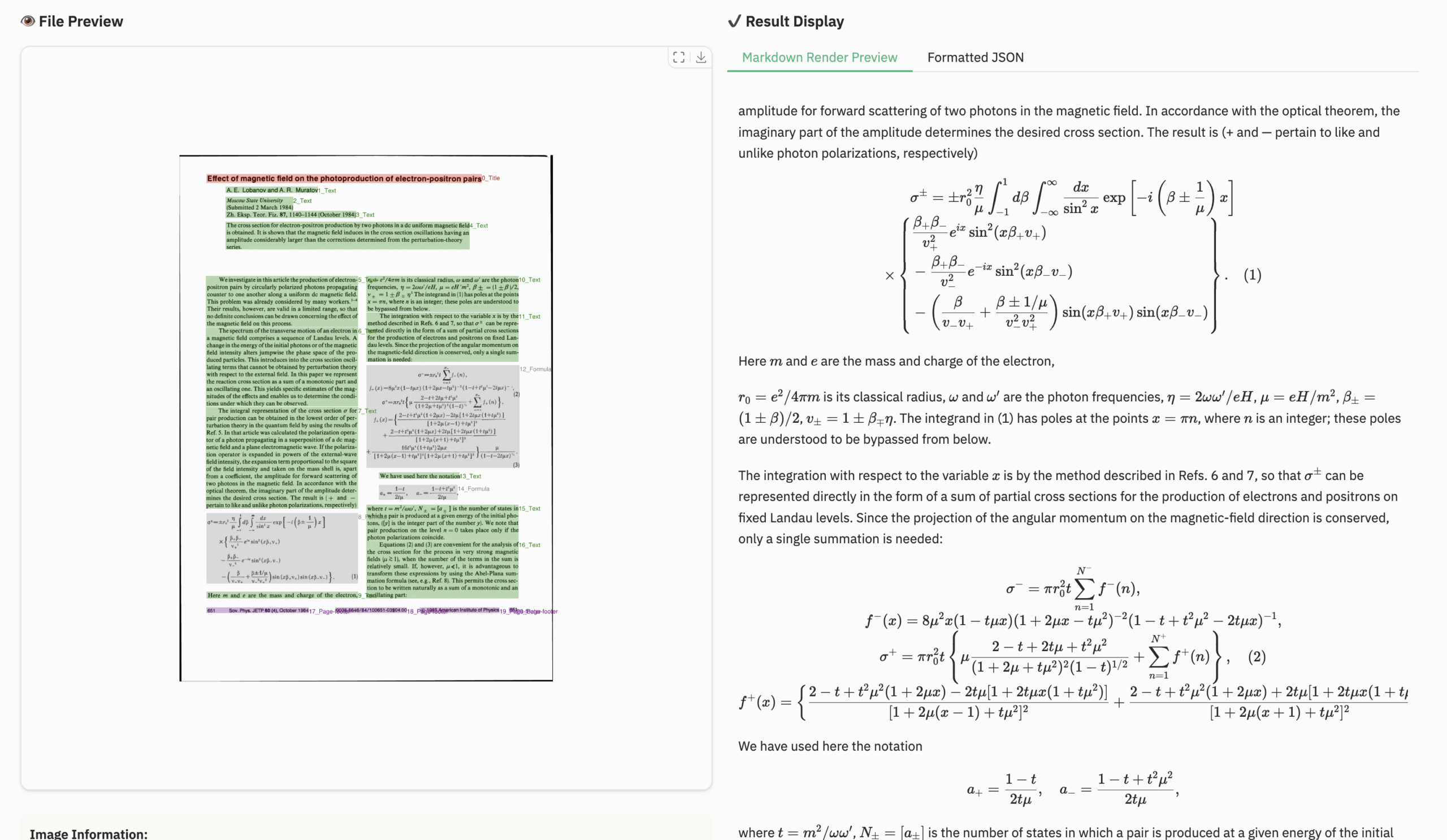
数式ドキュメントの例
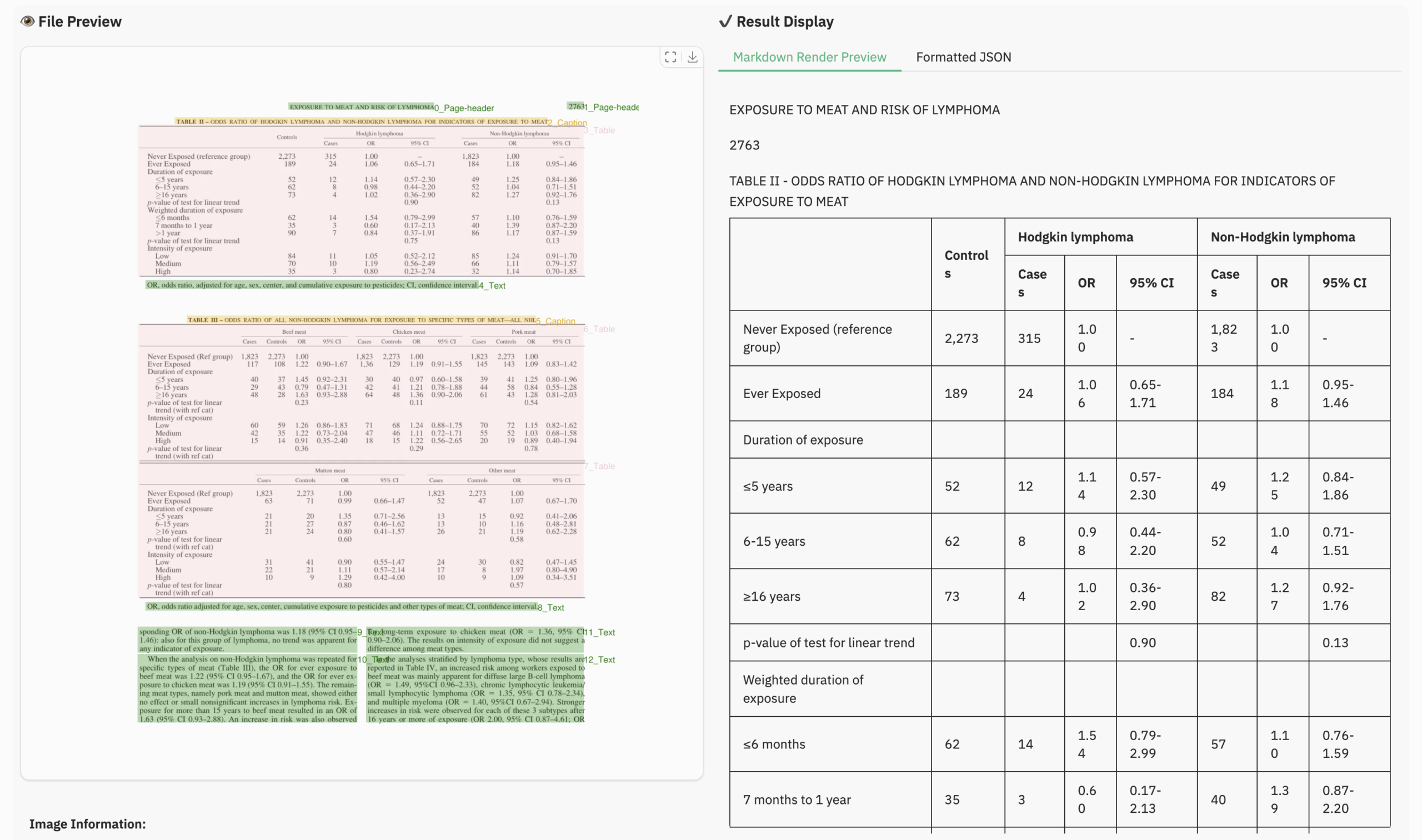
表文書の例
多言語ドキュメントの例



3. 操作手順
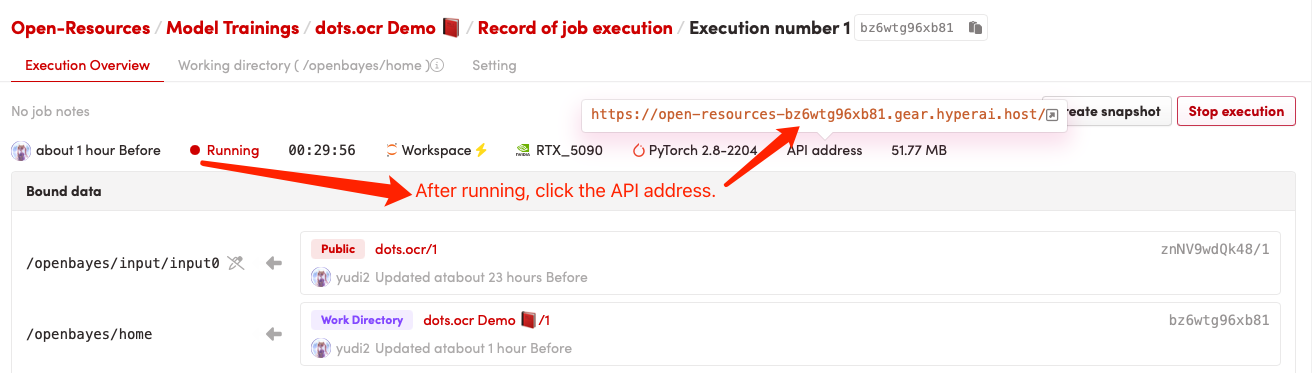
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
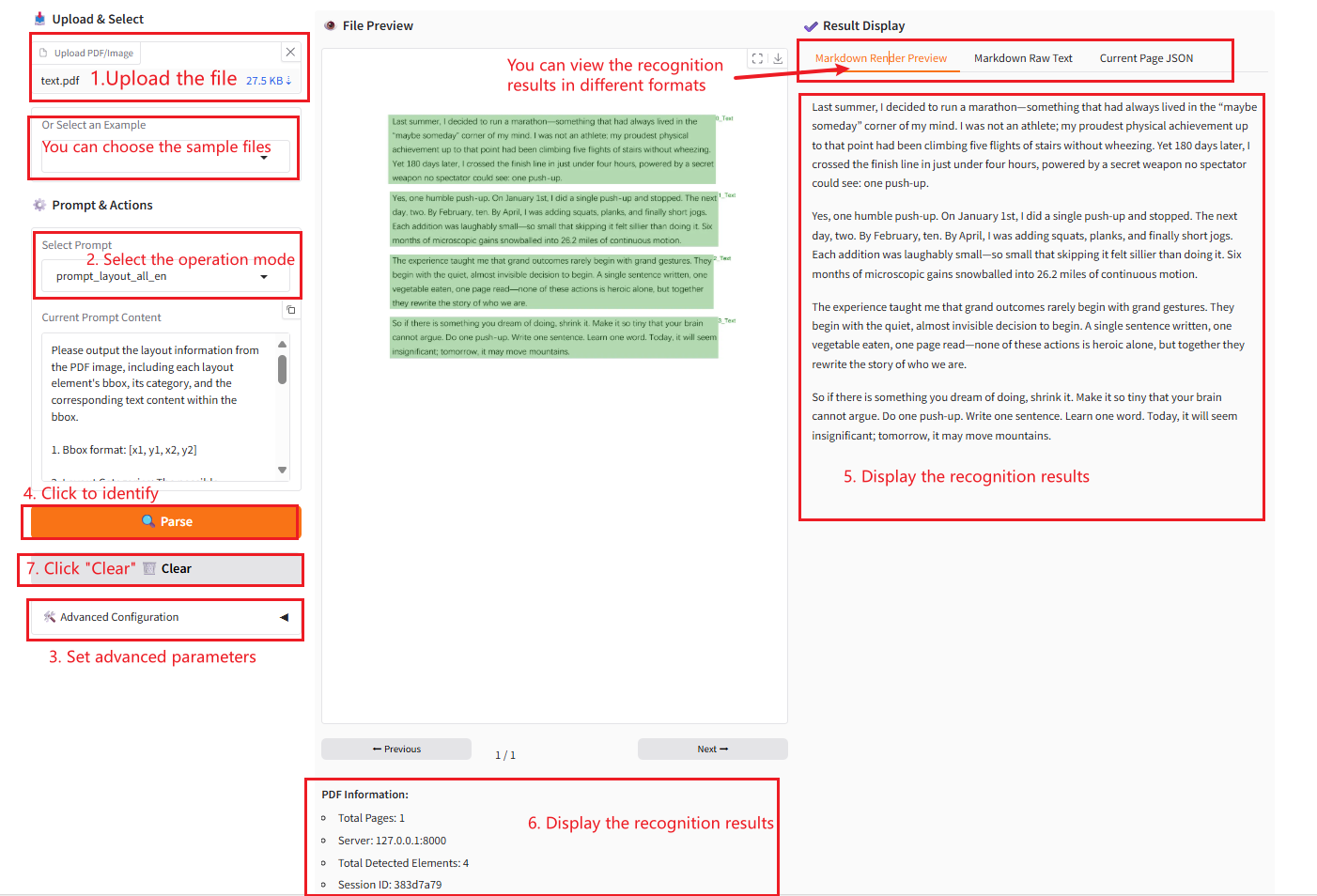
パラメータの説明
- プロンプトを選択:
- layout_all_en: 画像内のすべてのテキストを認識し、元のレイアウト構造を保持します。
- layout_only_en: 画像内の英語のテキストのみを認識し、他の言語は無視します。
- OCR: 構造を保持せずに画像内のテキストを認識します。
- 詳細設定:
- 画像に対してfitz_preprocessを有効にする:画像に対してfitz_preprocessを有効にするかどうか。画像のDPIが低い場合に推奨されます。
- 最小ピクセル: 画像内のピクセルの最小数。小さすぎる画像を除外するために使用されます。
- 最大ピクセル数: 画像の最大ピクセル数。大きすぎる画像を除外するために使用されます。
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。