HyperAI
Command Palette
Search for a command to run...
Nanonets-OCR-s: 文書情報抽出およびベンチマークツール
1. チュートリアルの概要

Nanonets-OCR-sは、Nanonetsが2025年6月10日にリリースした光学文字認識(OCR)モデルです。一般的なOCR技術は主に画像からプレーンテキストを抽出することに重点を置いていますが、Nanonets-OCR-sはさらに一歩進んでおり、数式、画像、署名、透かし、チェックボックス、表など、文書内の複数の要素を認識し、構造化されたMarkdown形式に整理することができます。これにより、学術論文、法律文書、ビジネスレポートなどの複雑な文書の処理において優れたパフォーマンスを発揮します。その出力は人間が読みやすいだけでなく、下流の自動処理のための強固な基盤を提供します。
このチュートリアルでは、リソースとしてRTX 4090カードを1枚使用します。このチュートリアルには2つの機能が含まれています。1. ドキュメントから情報を抽出する。2. 画像とPDFをMarkdownに変換する。
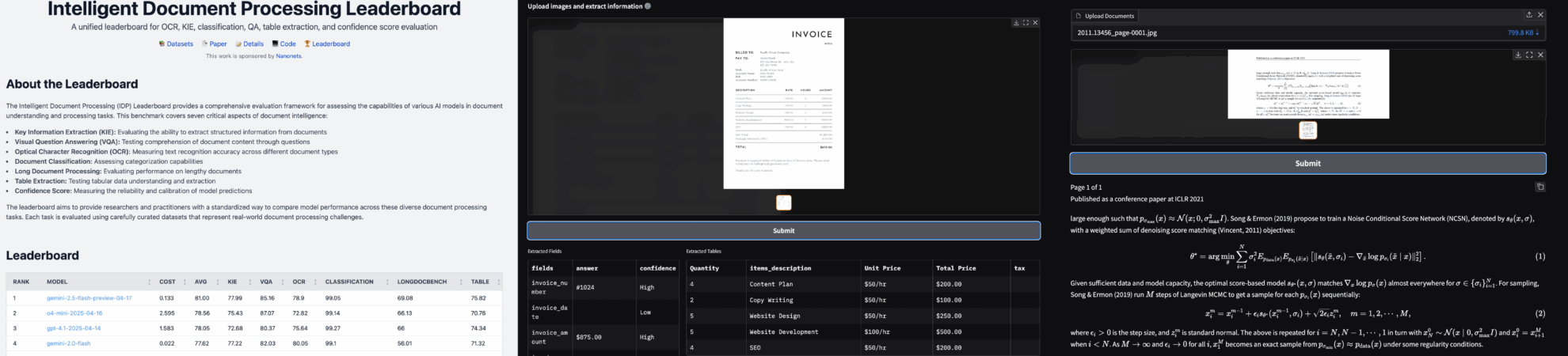
2. プロジェクト例
3. 操作手順
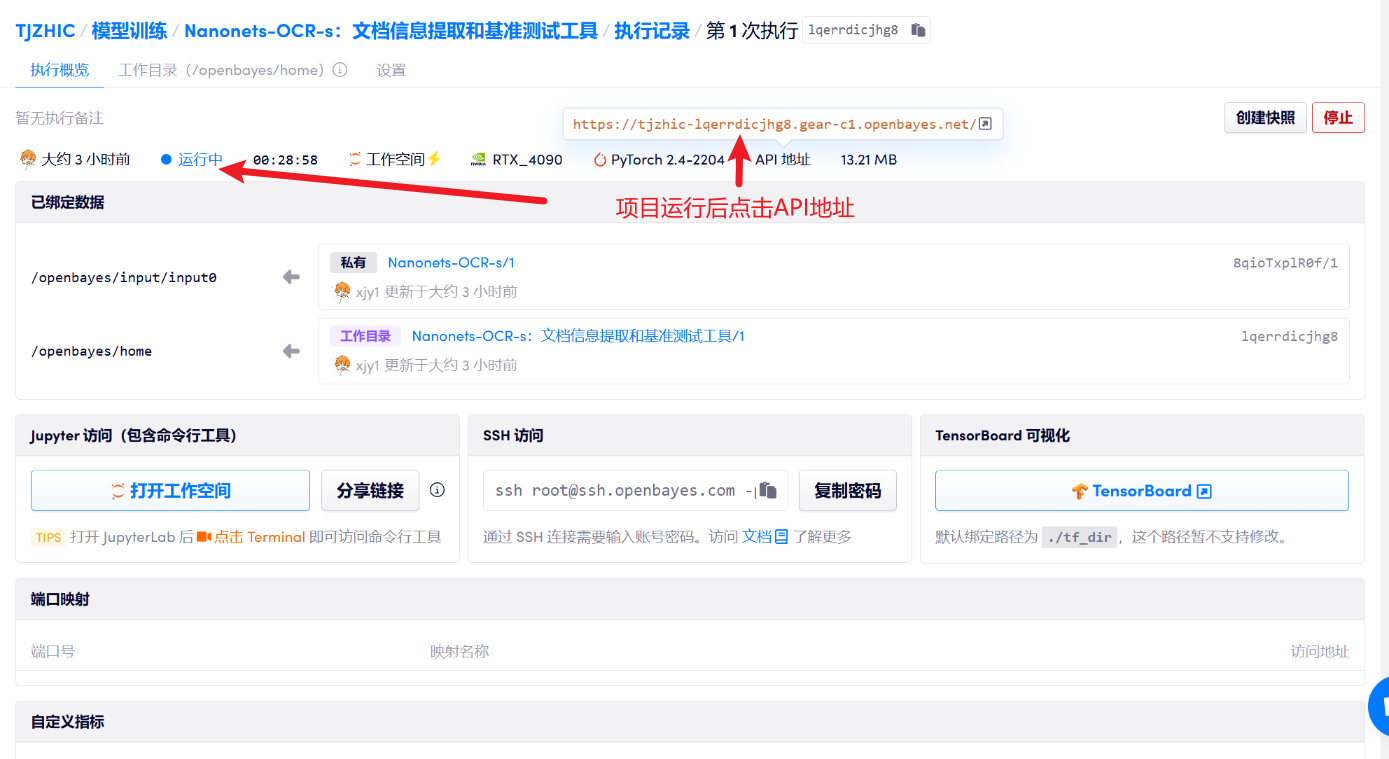
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってページを更新してください。
2.1 文書からの情報の抽出
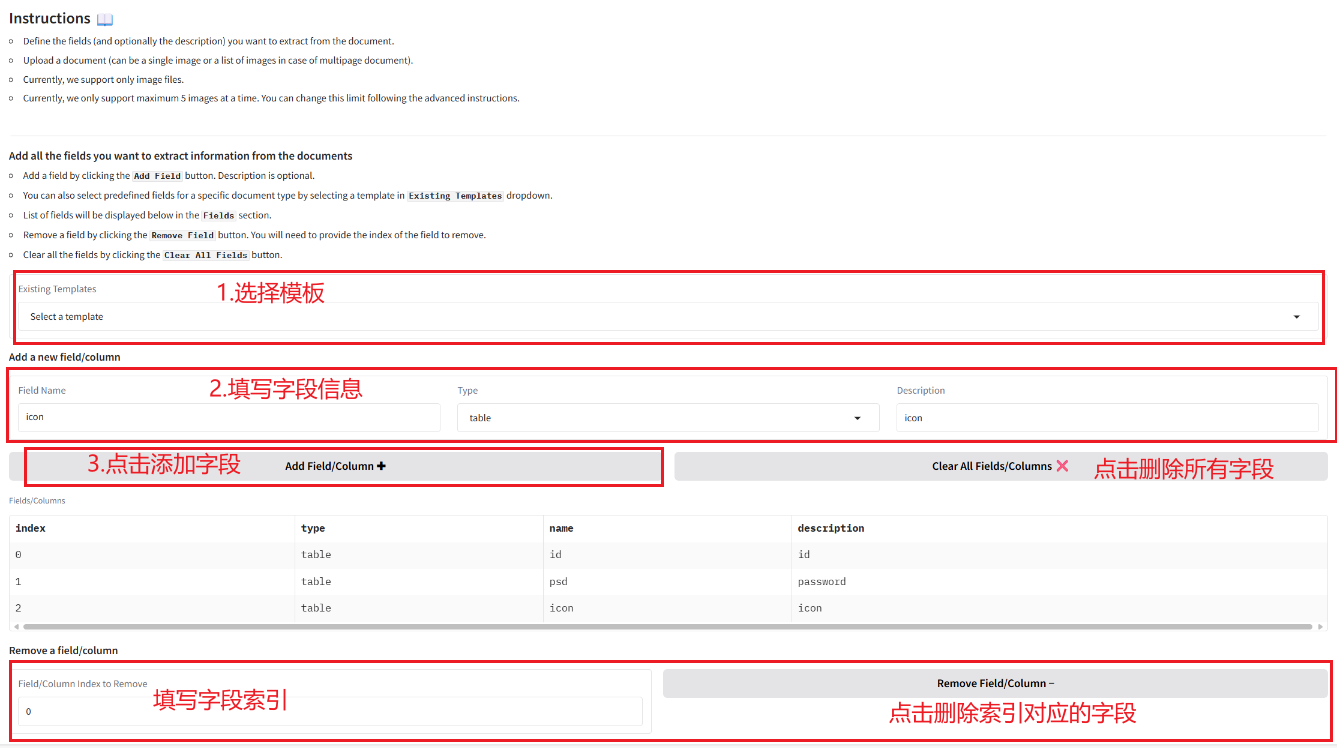
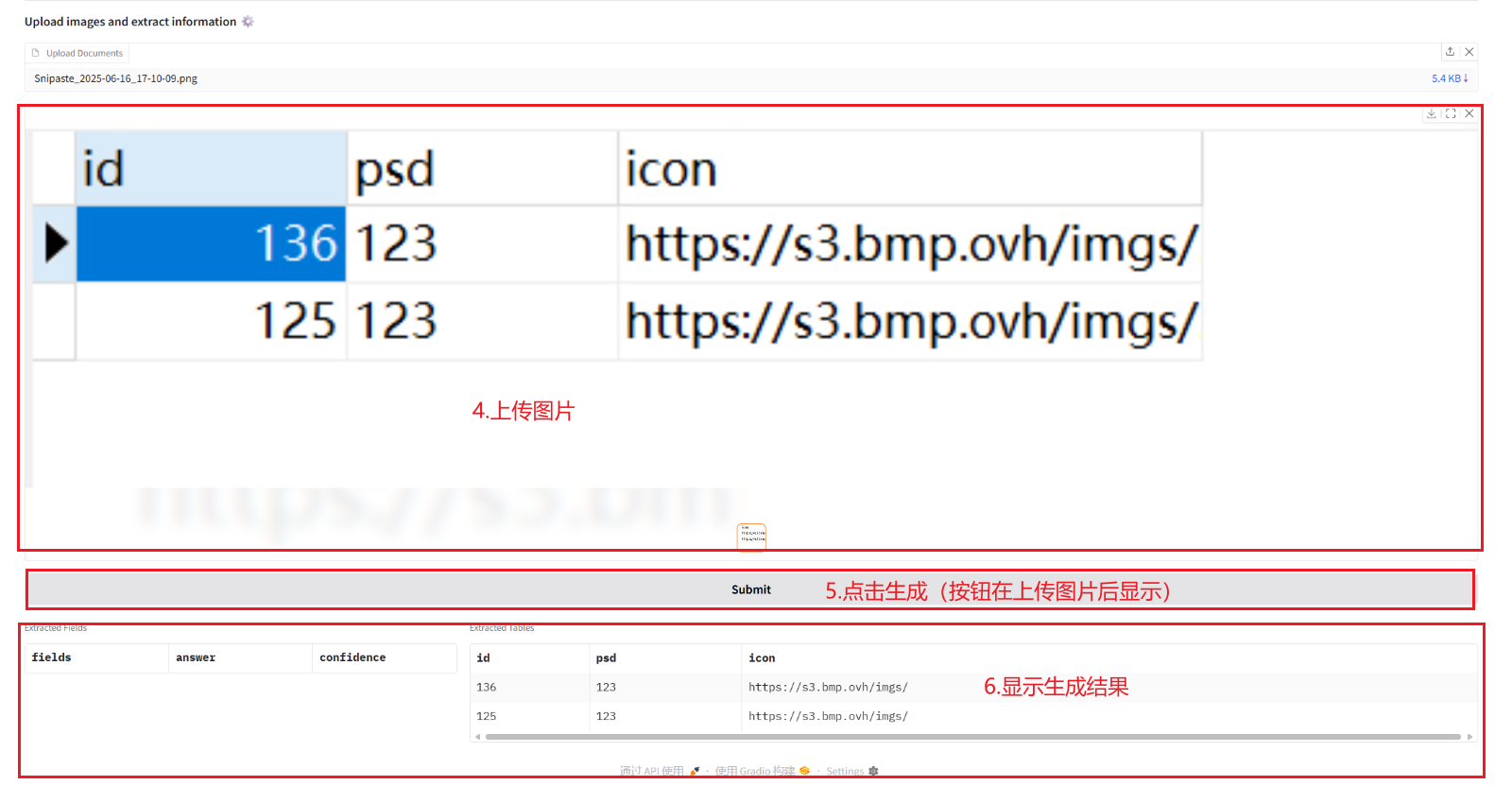
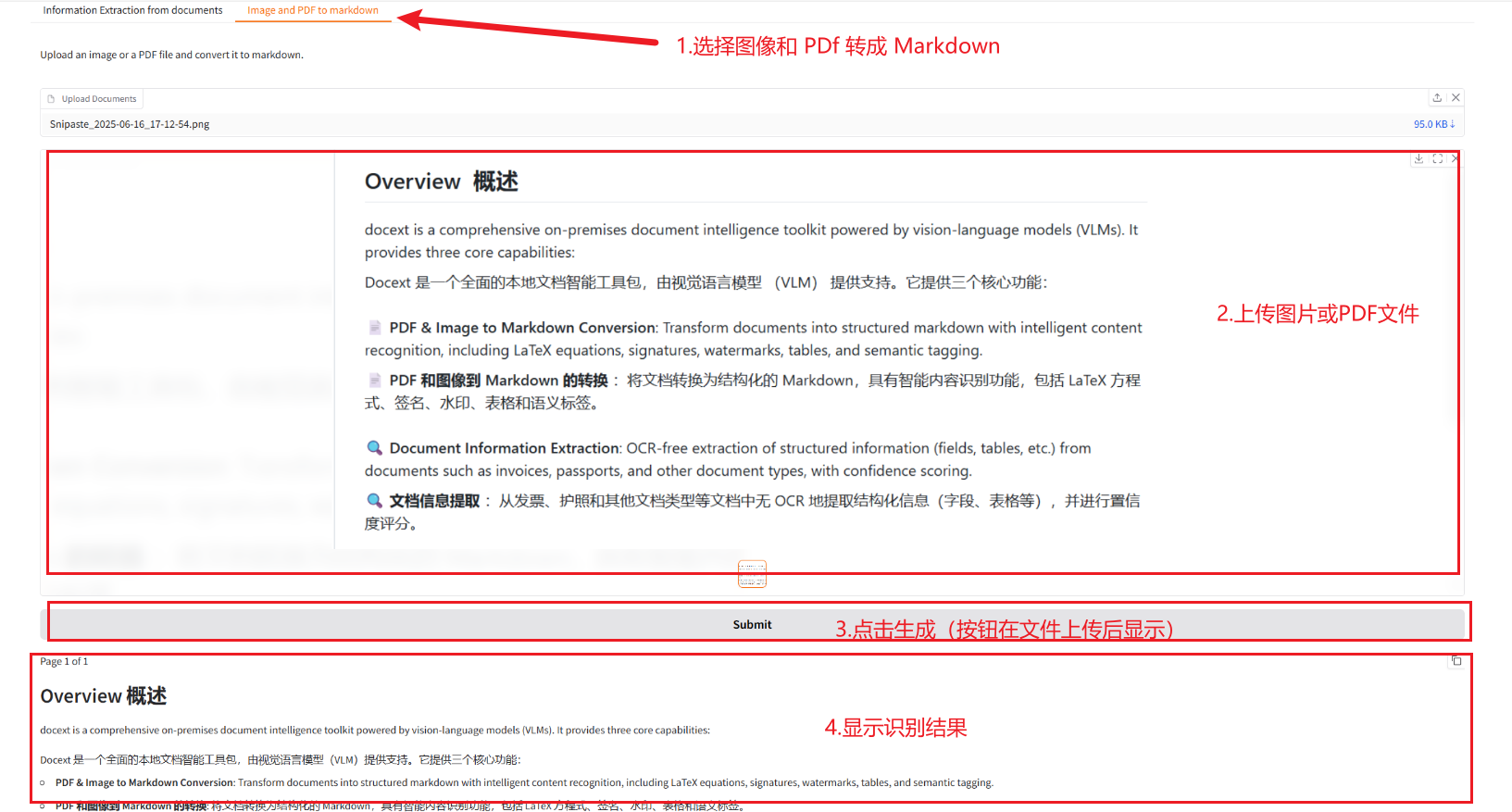
2.2 画像とPDFをMarkdownに変換する
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。