HyperAI
Command Palette
Search for a command to run...
YOLOE: すべてをリアルタイムで見る
1. チュートリアルの概要

YOLOEは、清華大学の研究チームが2025年に提唱した新しいリアルタイムビジョンモデルであり、「すべてをリアルタイムで見る」という目標の達成を目指しています。YOLOシリーズモデルのリアルタイム性と効率性を継承し、ゼロショット学習とマルチモーダルプロンプト機能を深く統合することで、テキスト、ビジョン、ヒントなしのシナリオなど、様々なシナリオにおける物体検出とセグメンテーションを可能にします。関連研究論文も公開されています。 YOLOE: リアルタイムで何でも見る 。
YOLO (You Only Look Once) は、2015 年の発売以来、物体検出と画像セグメンテーションのリーダーとして活躍しています。以下は、YOLO シリーズと関連チュートリアルの進化です。
- YOLOv2 (2016): バッチ正規化、アンカー ボックス、ディメンション クラスタリングを紹介します。
- YOLOv3 (2018): より効率的なバックボーン ネットワーク、マルチ アンカー、空間ピラミッド プーリングを使用します。
- YOLOv4 (2020): モザイクデータ拡張、アンカーフリー検出ヘッド、新しい損失関数を紹介します。 → チュートリアル:DeepSOCIALはYOLOv4をベースにした群衆距離監視とソートマルチターゲットトラッキングを実現
- YOLOv5 (2020): ハイパーパラメータの最適化、実験の追跡、自動エクスポート機能が追加されました。 → チュートリアル:YOLOv5_deepsort リアルタイムマルチターゲット追跡モデル
- YOLOv6 (2022): Meituanオープンソース、自律配送ロボットに広く使用されています。
- YOLOv7 (2022): COCOキーポイントデータセットのポーズ推定をサポートします。→チュートリアル:カスタム YOLOv7 モデルをトレーニングして使用する方法
- YOLOv8 (2023):Ultralyticsがリリースされ、あらゆるビジュアルAIタスクに対応しています。→チュートリアル:カスタムデータを使用した YOLOv8 のトレーニング
- YOLOv9 (2024): プログラム可能な勾配情報 (PGI) と一般化効率的なレイヤー集約ネットワーク (GELAN) の紹介。
- YOLOv10(2024年): 清華大学によって開始され、エンドツーエンド ヘッダーを導入し、非最大抑制 (NMS) 要件を排除します。 → チュートリアル:YOLOv10 リアルタイムのエンドツーエンドのターゲット検出
- YOLOv11(2024): 検出、セグメンテーション、ポーズ推定、追跡、分類をサポートする Ultralytics の最新モデル。 → チュートリアル:YOLOv11 のワンクリック展開
- YOLOv12 🚀 新着(2025): スピードと精度の二重のピークと、アテンションメカニズムのパフォーマンス上の利点を組み合わせました。
コア機能
- 任意のテキストタイプ

2. マルチモーダルプロンプト:
- 視覚的な手がかり(ボックス/ドット/手描きの図形/参照画像)

- 完全自動サイレント検出 – シーンオブジェクトを自動的に識別

デモ環境: YOLOv8e/YOLOv11e シリーズ + RTX4090
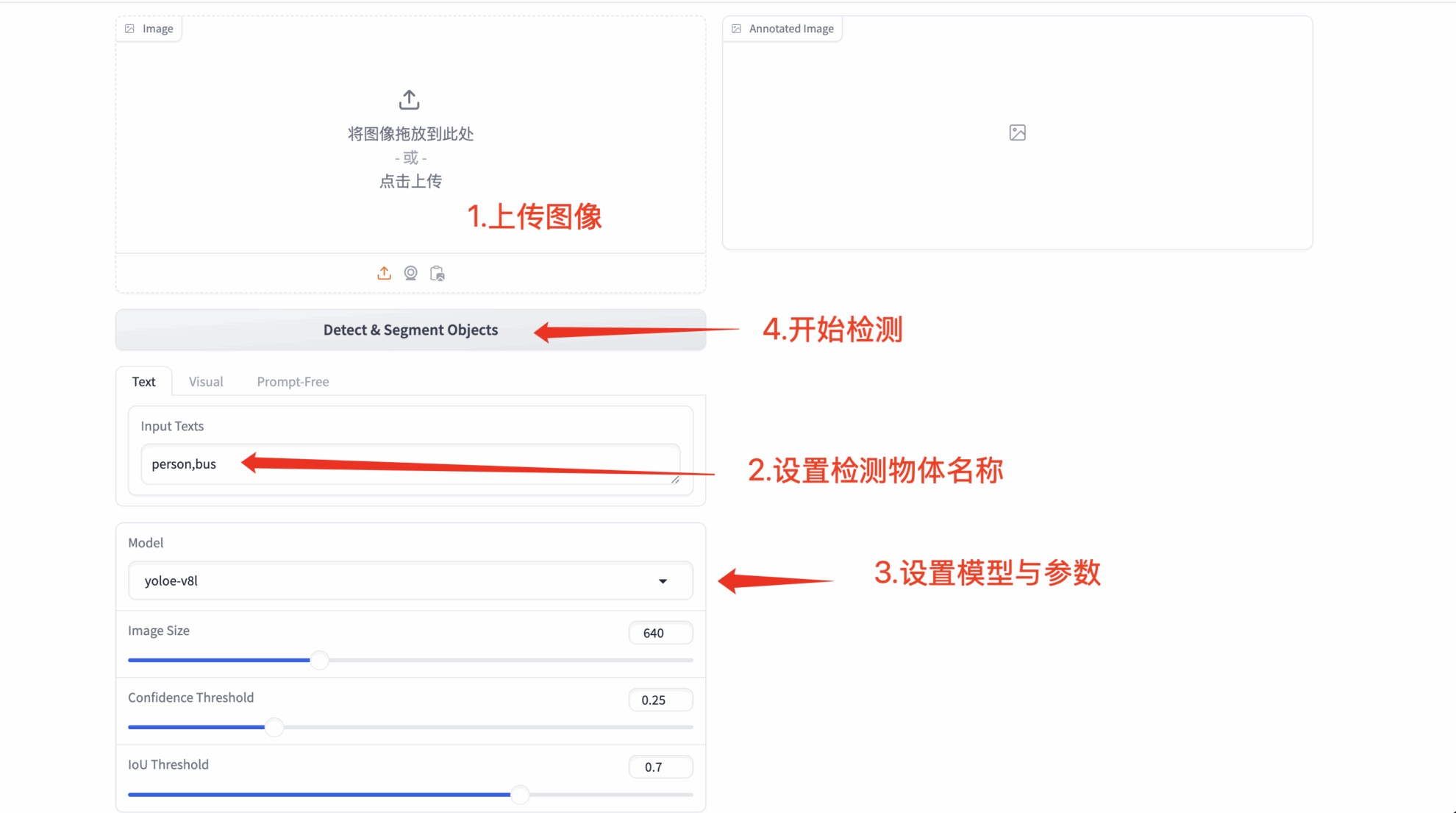
2. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。 1~2分ほど待ってからページを更新してください。

2. YOLOE機能のデモンストレーション
1. テキストプロンプト検出
- 任意のテキストタイプ
- カスタムプロンプトワード: ユーザーが任意のテキストを入力できるようにします(認識結果は意味の複雑さに応じて異なる場合があります)

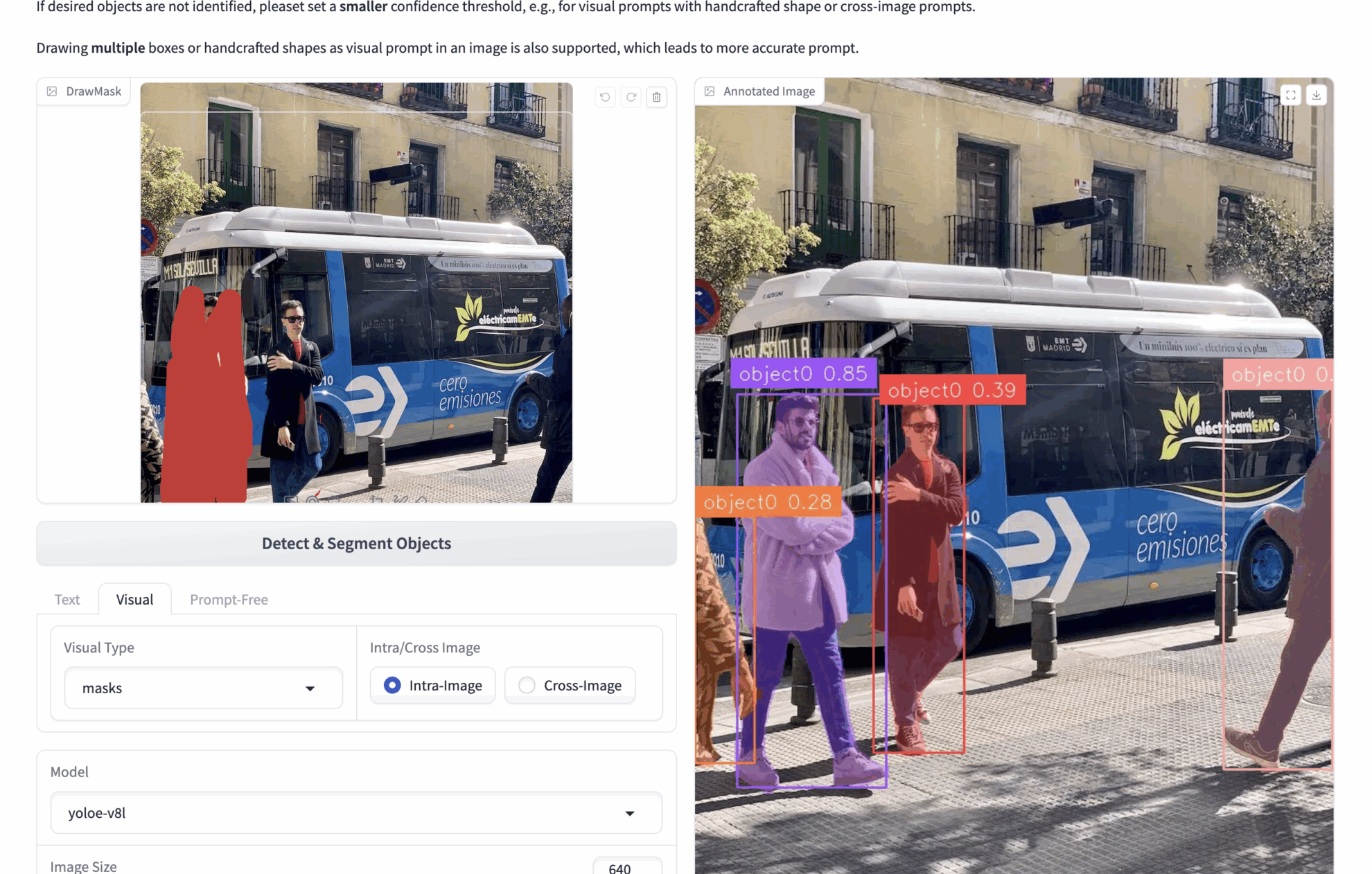
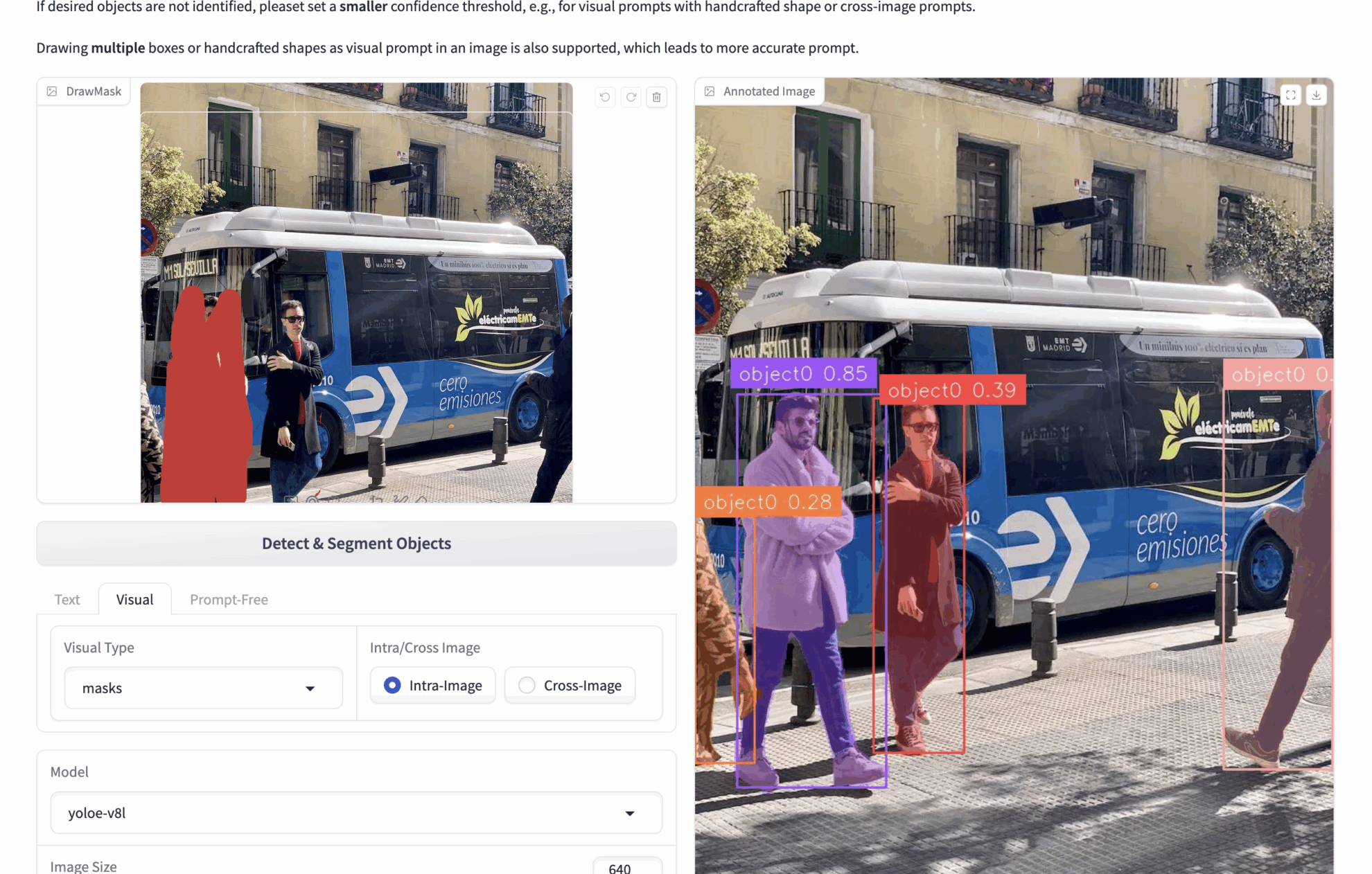
2. マルチモーダルな視覚的手がかり
- 🟦 ボックス選択検出 (bボックス)
bboxes: たとえば、多数の人物が写っている画像をアップロードし、画像内の人物を検出したい場合、bboxes を使用して 1 人の人物をフレームに収めることができます。推論中、モデルは bbox の内容に基づいて画像内のすべての人物を識別します。
より正確な視覚的な手がかりを得るために、複数の bbox を描画できます。 - ✏️ クリック/描画領域 (マスク)
マスク: たとえば、多数の人物が写っている画像をアップロードし、画像内の人物を検出したい場合は、マスクを使用して 1 人の人物を隠すことができます。推論中、モデルはマスクの内容に基づいて画像内のすべての人物を認識します。
より正確な視覚的な手がかりを得るために、複数のマスクを描画することができます。 - 🖼️ 参考画像の比較 (イントラ/クロス)
イントラ: 現在の画像に対して bbox またはマスクを操作し、現在の画像に対して推論を実行します。
Cross: 現在の画像で bbox またはマスクを操作し、他の画像を推測します。
コアコンセプト
| モデル | 機能説明 | アプリケーションシナリオ |
|---|---|---|
| 画像内 | 単一グラフ内でのオブジェクトの関係のモデリング | ローカルターゲットの正確な位置決め |
| クロスイメージ | 画像間の特徴マッチング | 類似オブジェクトの検索 |

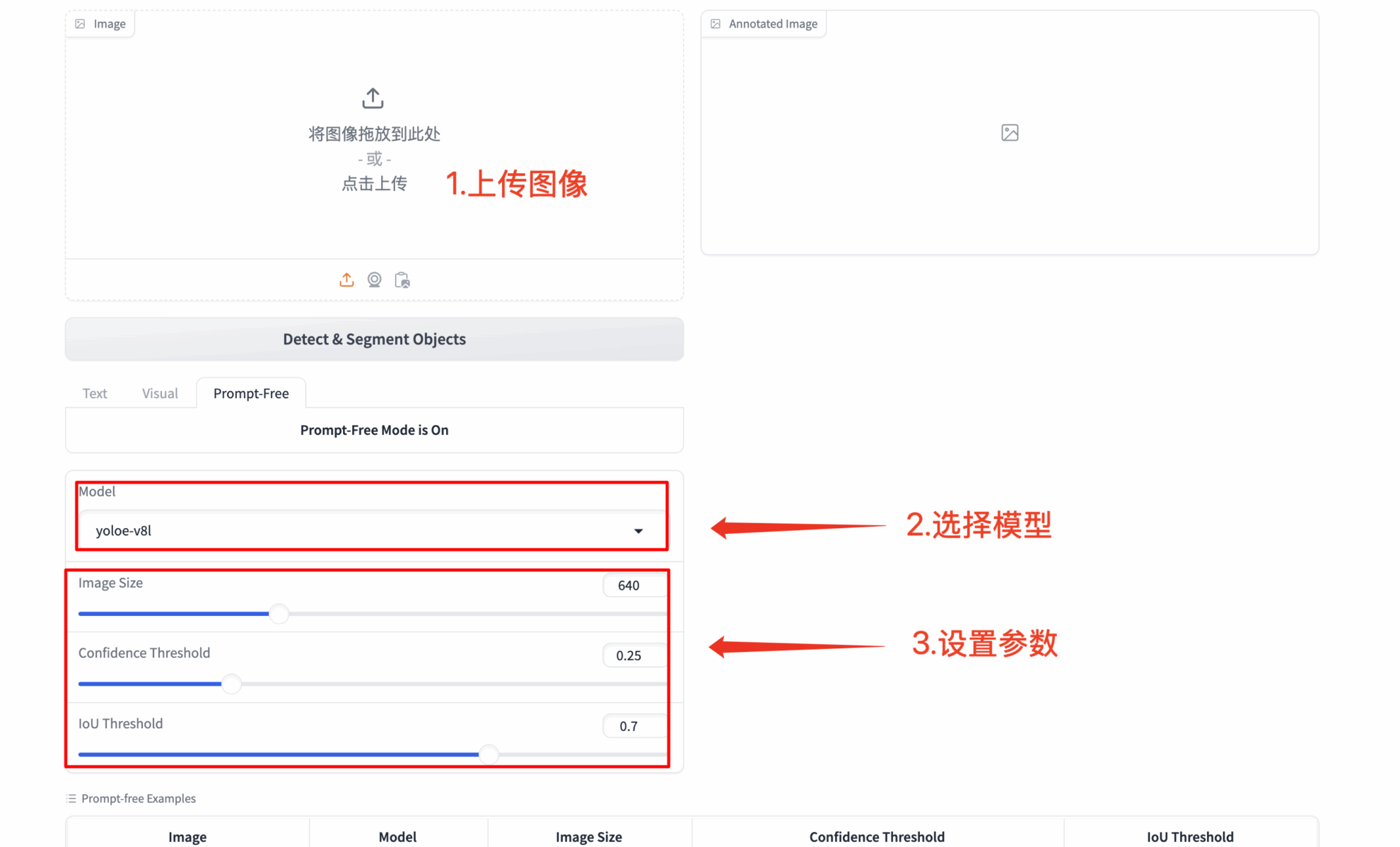
3. プロンプトなしで完全に自動検出
- 🔍 インテリジェントなシーン分析: 画像内の目立つオブジェクトをすべて自動的に識別します
- 🚀 ゼロ構成の起動: プロンプト入力なしで動作します

交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。