HyperAI
Command Palette
Search for a command to run...
MinerU ワンストップデータ抽出ツール
GPUコンピュートの無料配布
RTX 5090のコンピュートリソースがわずか20時間分 $1 (価値 $7)
モデル紹介

MinerU は、PDF を機械可読形式 (マークダウン、json など) に変換し、任意の形式に簡単に抽出できるツールです。 176 言語の正確な認識をサポートし、正確な言語タイプの識別を実行します。 画像、数式、表、脚注などを含む複雑なマルチモーダル PDF ドキュメントを、明確で分析しやすい Markdown 形式に変換するように特別に設計されています。さらに、MinerU は、広告などの気が散る情報を含む Web ページや電子書籍からの正式なコンテンツの迅速な解析と抽出もサポートしており、これにより AI コーパスの準備の効率が効果的に向上します。
主な機能
- ヘッダー、フッター、脚注、ページ番号、その他の要素を削除して、意味の一貫性を維持します。
- 複数の列に対して人間が読んだ順序でテキストを出力します。
- タイトル、段落、リストなど、元の文書の構造を保持します。
- 画像、写真のタイトル、表、表のタイトルを抽出
- 文書内の数式を自動的に識別し、数式をラテックスに変換します
- ドキュメント内の表を自動的に識別し、表をラテックスに変換します
- 文字化けした PDF を自動的に検出して OCR を有効にする
- CPU環境とGPU環境の両方をサポート
- Windows/Linux/Mac プラットフォームをサポート
推論ステップをデプロイする
このチュートリアルでは、モデルと環境をデプロイしました。チュートリアルのガイドラインに従って、推論ダイアログに大規模なモデルを直接使用できます。具体的なチュートリアルは次のとおりです。
1. モデル構成
リソースが構成されたら、コンテナを起動し、API アドレスで接続をクリックしてデモ インターフェイスに入ります。
2.インターフェースを開きます
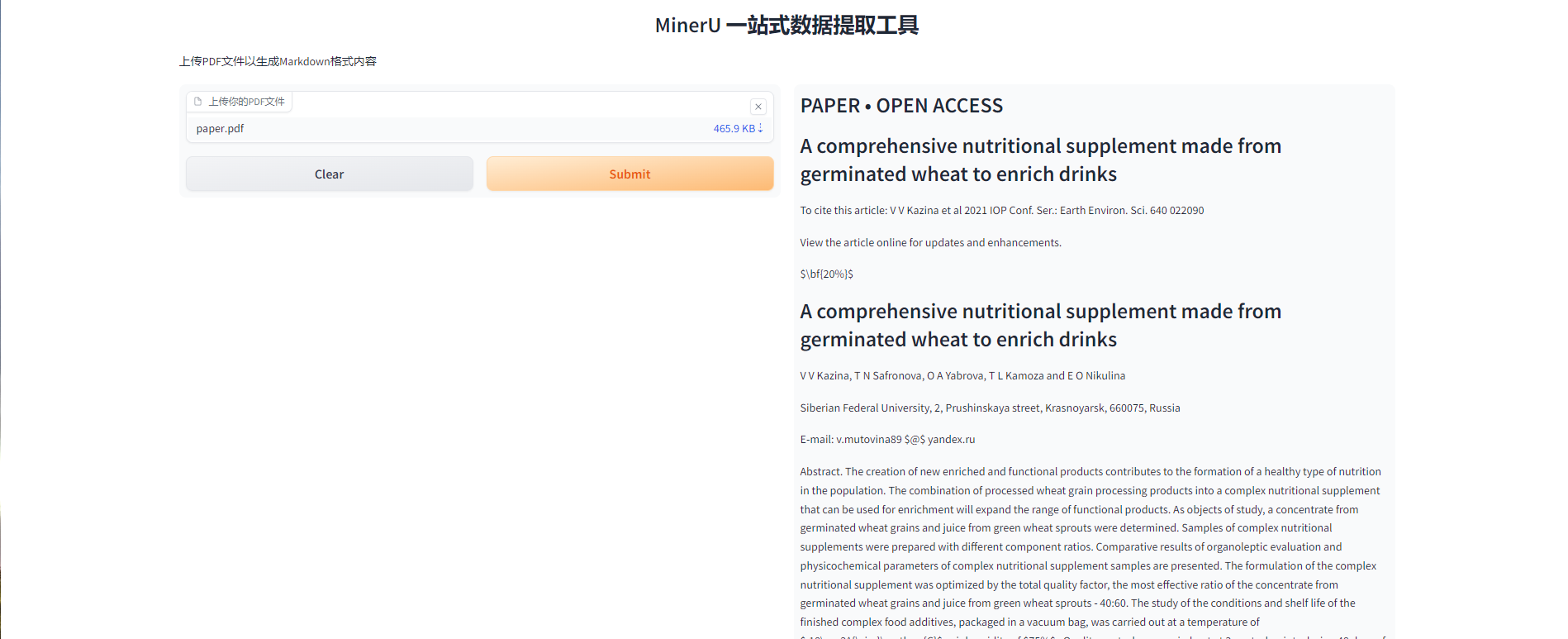
しばらくすると、モデルのインターフェイスが表示され、モデルを使用できるようになります。ユーザーは、抽出する必要がある PDF ファイルをアップロードし (5 MB を超えないよう注意してください)、送信ボタンをクリックしてモデルの抽出を開始します。ユーザーがモデルを体験できるように、サンプル ファイル Paper.pdf もグラデーション インターフェイスで提供されています。 (このファイルの解凍時間は約110秒です)
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。