Command Palette
Search for a command to run...
PERSONAPLEX:フルデュプレックス会話型音声モデルにおけるボイスおよびロール制御
PERSONAPLEX:フルデュプレックス会話型音声モデルにおけるボイスおよびロール制御
Rajarshi Roy Jonathan Raiman Sang-gil Lee Teodor-Dumitru Ene Robert Kirby Sungwon Kim Jaehyeon Kim Bryan Catanzaro
概要
近年のデュプレックス音声モデルの進展により、自然で低遅延な音声対音声の対話が可能になった。しかし、従来のモデルは固定された役割と音声に限定されており、構造的で役割中心の現実世界の応用や個別化された対話のサポートに限界がある。本研究では、役割の条件付けをテキストプロンプトと組み合わせ、音声クローンを音声サンプルで実現するハイブリッドシステムプロンプトを導入した、デュプレックス会話型音声モデル「PersonaPlex」を提案する。PersonaPlexは、オープンソースの大規模言語モデル(LLM)および音声合成(TTS)モデルを用いて生成された、プロンプトとユーザー・エージェント間の対話データを含む大規模な合成データセット上で学習されている。実世界における役割条件付けの評価を可能にするために、従来の単一アシスタント役割に限られていた「Full-Duplex-Bench」ベンチマークを、複数の役割を想定したカスタマーサービスシナリオへ拡張した。実験の結果、PersonaPlexは強固な役割条件付け行動、音声条件付けされた音声生成、自然な会話応答性を実現し、最新のデュプレックス音声モデルおよびハイブリッド大規模言語モデルベースの音声システムと比較して、役割遵守性、発話者類似性、遅延、自然さの面で優れた性能を発揮した。
One-sentence Summary
NVIDIA researchers introduce PersonaPlex, a full-duplex conversational speech model that uses hybrid system prompts and voice cloning to enable dynamic role and voice control, outperforming state-of-the-art duplex and LLM-based speech systems in role adherence, speaker similarity, latency, and naturalness on extended multi-role customer service benchmarks.
Key Contributions
- PersonaPlex introduces a full-duplex speech-to-speech model that integrates hybrid system prompts for text-based role conditioning and audio-based voice cloning, enabling zero-shot voice adaptation and structured role-driven interactions in domains like customer service.
- It is trained on a large-scale synthetic dataset of paired prompts and conversations generated using open-source LLMs and TTS models, and evaluated on Service-Duplex-Bench—an extension of Full-Duplex-Bench that adds 350 multi-role customer service scenarios to the original 400-question benchmark.
- Experiments demonstrate that PersonaPlex surpasses state-of-the-art duplex and hybrid LLM-based speech systems in role adherence, speaker similarity, latency, and naturalness while maintaining real-time turn-taking and responsiveness.
Introduction
The authors leverage recent advances in duplex speech models to build PersonaPlex, a system that supports dynamic role switching and voice cloning during real-time, full-duplex conversations. Prior duplex models are limited to fixed roles and voices, making them unsuitable for structured applications like customer service or multi-character interactions, while cascaded ASR-LLM-TTS systems sacrifice paralinguistic nuance and responsiveness. PersonaPlex overcomes these limitations by integrating hybrid prompts—text for role conditioning and audio for voice cloning—into a unified, low-latency architecture trained on synthetic dialog data. The authors also extend the Full-Duplex-Bench benchmark to evaluate multi-role scenarios, showing that PersonaPlex outperforms existing systems in role adherence, voice similarity, and conversational naturalness without compromising latency.
Dataset

The authors use a synthetic dataset composed of dialog transcripts and generated speech to train and evaluate their model. Here’s how the data is structured and processed:
-
Dataset Composition & Sources
- Dialog transcripts are generated using Qwen-3-32B and GPT-OSS-120B.
- Two main scenario types: Service Scenarios (e.g., restaurant, bank) and Question-Answering Assistant Scenarios (teacher role with topic variations).
- Voice samples come from VoxCeleb, Libriheavy, LibriTTS, CommonAccent, and Fisher (26,296 samples total; 2,630 reserved for testing speaker similarity).
- For the released checkpoint, real conversational data from Fisher English corpus (7,303 conversations, 1,217 hours) is added to improve natural backchanneling and emotional responses.
-
Key Subset Details
- Service Scenarios:
- Hierarchically sampled by domain → scenario → transcript.
- Role context provided per agent (e.g., name, company, SSN, plan options).
- Training scenarios are distinct from evaluation ones in Service-Duplex-Bench.
- Question-Answering Scenarios:
- Two-turn dialogs with fixed role: “wise and friendly teacher.”
- Topics vary; second questions may involve topic change or follow-up.
- Service-Duplex-Bench (Evaluation):
- 50 unique service scenarios, each with 7 single-turn questions.
- Tests capabilities like proper noun recall, context adherence, and handling rude customers.
- Example context includes agent name, company, SSN, and available plans.
- Service Scenarios:
-
How the Data Is Used
- Training split includes synthetic dialogs + Fisher corpus (for released checkpoint).
- Mixture ratios not specified, but synthetic dialogs dominate; Fisher data supplements for realism.
- Prompts for Fisher data vary in detail: minimal, topic-specific, or highly detailed (generated via GPT-OSS-120B).
- For released model, all synthetic voices are generated via TortoiseTTS (privacy-preserving), pitch/formant augmented with Praat.
- ChatterboxTTS replaces Dia for unified speech generation, improving speaker similarity to 0.65.
-
Processing & Cropping Details
- Service dialog audio uses Dia TTS for joint two-speaker generation (timing, interruptions, room tone).
- QA dialog audio uses Chatterbox TTS per turn, then stitched with silence padding (or negative silence for barge-in simulation).
- No explicit cropping mentioned, but turn stitching simulates natural or interrupted speech flow.
- Metadata includes role context, speaker identity, and scenario grounding for each dialog.
Method
The authors leverage PersonaPlex, a duplex-style multimodal architecture inspired by Moshi, to process three parallel input streams: user audio, agent text, and agent audio. This design enables simultaneous role conditioning and voice control through a novel Hybrid System Prompt, which is temporally structured to guide both semantic and acoustic behavior of the agent. Refer to the framework diagram for a visual breakdown of the input channels and processing stages.
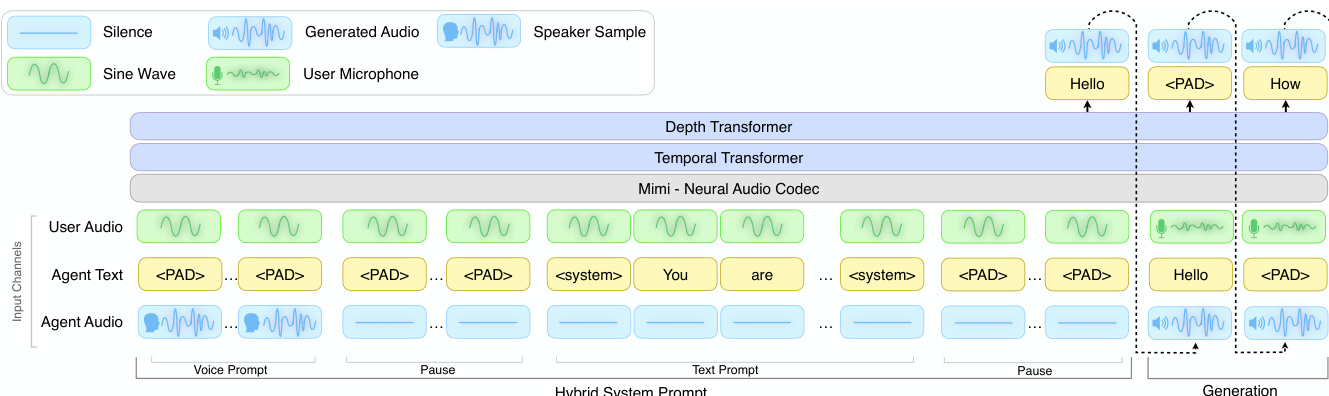
The Hybrid System Prompt is composed of two concatenated segments: a text prompt segment and a voice prompt segment. In the text prompt segment, scenario-specific text tokens are injected into the agent text channel while the agent audio channel remains silent, enforcing role conditioning. In the voice prompt segment, a short speech sample is provided via the agent audio channel, with the agent text channel padded to maintain alignment—this enables zero-shot voice cloning by conditioning subsequent agent utterances to match the supplied voice. To ensure stable conditioning during training, the user audio channel is replaced with a 440 Hz sine wave during the prompt phase, and custom delimiters demarcate the boundary between the Hybrid System Prompt and the dialogue generation phase.
The model employs a Mimi neural audio codec for audio tokenization, followed by a Temporal Transformer and a Depth Transformer to process the multimodal sequence. During training, loss backpropagation is masked for the system prompt tokens to prevent overfitting to prompt structure. To address token imbalance, the authors down-weight the loss on non-semantic audio tokens by a factor of 0.02 and on padded text tokens by 0.3, aligning with the Moshi training objective. The order of the voice and text prompt segments is flexible; in practice, the voice prompt precedes the text prompt to allow prefilling during inference when voice cloning is not required, thereby reducing latency.
Experiment
PersonaPlex, trained on 1840 hours of customer service and 410 hours of QA dialogs using a hybrid prompt system and fine-tuned from Moshi weights, achieves state-of-the-art performance in dialog naturalness and voice cloning, as validated by human DMOS scores and WavLM-TDNN speaker similarity metrics. On Full-Duplex-Bench, it excels in human-like interactivity, while on Service-Duplex-Bench, it matches or exceeds all models except Gemini Live in role adherence, demonstrating strong instruction following. Dataset scaling experiments show synthetic data boosts voice cloning and role adherence, with performance improving steadily on Service-Duplex-Bench as data increases. The released checkpoint maintains competitive naturalness and enhances conversational dynamics like backchanneling and pause handling.
The authors evaluate PersonaPlex using varying dataset sizes and compare against a Moshi baseline. Results show that increasing dataset size improves performance on both Full-Duplex-Bench and Service-Duplex-Bench, with 100% data yielding the highest scores. The Moshi baseline, trained without synthetic data, performs significantly worse across all metrics. Performance improves with larger dataset sizes on both benchmarks 100% dataset size achieves highest GPT-4o scores: 4.21 and 4.48 Moshi baseline (0% synthetic data) scores lowest: 0.10 SSIM and 1.75 GPT-4o

The authors evaluate PersonaPlex against several baseline models using human-rated DMOS scores and speaker similarity metrics. Results show PersonaPlex achieves the highest DMOS on both Full-Duplex-Bench and Service-Duplex-Bench, and the highest speaker similarity score. This indicates superior conversational naturalness and voice cloning capability compared to other models. PersonaPlex scores highest in DMOS for both Full-Duplex-Bench and Service-Duplex-Bench PersonaPlex achieves 0.57 speaker similarity, significantly outperforming all other models Gemini and Qwen-2.5-Omni show moderate DMOS but near-zero speaker similarity

The authors evaluate the naturalness of the released PersonaPlex model using human-rated DMOS scores on the Full-Duplex-Bench. PersonaPlex achieves the highest score among tested models, indicating superior perceived conversational naturalness. The evaluation includes comparisons against Gemini, Qwen-2.5-Omni, Freeze-Omni, and Moshi. PersonaPlex (Released) scores highest at 2.95 ± 0.25 DMOS Outperforms Gemini (2.80) and Qwen-2.5-Omni (2.81) in naturalness Moshi baseline scores lowest at 2.44 ± 0.21 DMOS

The authors evaluate multiple models on a GPT-4o task, reporting scores across seven subtasks and a mean. PersonaPlex achieves a mean score of 4.48, trailing only Gemini at 4.73, while Moshi and Qwen-2.5-Omni score significantly lower. PersonaPlex ranks second overall with a mean score of 4.48 Gemini leads with the highest mean score of 4.73 Moshi and Qwen-2.5-Omni show substantially lower performance

The released PersonaPlex checkpoint is evaluated on multiple conversational dynamics including pause handling, backchannel frequency, turn taking, and user interruption response. Results show low turn overlap rates and latency, high backchannel frequency, and strong user interruption handling. These metrics indicate improved conversational fluidity and responsiveness compared to prior baselines. Low turn overlap rates in pause and turn taking indicate precise timing control High backchannel frequency suggests improved conversational engagement Strong user interruption handling with low latency supports natural dialog flow

PersonaPlex is evaluated across multiple benchmarks using human ratings and automated metrics, demonstrating consistent superiority over baselines including Moshi, Gemini, and Qwen-2.5-Omni. On Full-Duplex-Bench and Service-Duplex-Bench, it achieves the highest DMOS scores and speaker similarity (0.57), indicating stronger conversational naturalness and voice cloning. With 100% dataset size, it attains peak GPT-4o scores of 4.21 and 4.48, significantly outperforming the Moshi baseline (0.10 SSIM, 1.75 GPT-4o). The released model also excels in conversational dynamics, showing low turn overlap, high backchannel frequency, and responsive interruption handling, while ranking second in GPT-4o task performance with a mean score of 4.48.