Command Palette
Search for a command to run...
Helios: 実時間長期動画生成モデル
Helios: 実時間長期動画生成モデル
Shenghai Yuan Yuanyang Yin Zongjian Li Xinwei Huang Xiao Yang Li Yuan
概要
本研究では、単一の NVIDIA H100 GPU 上で 19.5 FPS の処理速度を実現し、分単位の動画生成を支援しながら強力なベースラインと同等の品質を達成する、初の 140 億パラメータ規模の動画生成モデル「Helios」を提案する。本モデルは以下の 3 つの主要な次元において画期的な進歩を成し遂げている。(1) 自己強制(self-forcing)、エラーバンク(error-banks)、キーフレームサンプリングといった一般的なドリフト防止ヒューリスティックに依存することなく、長動画生成におけるドリフト現象に対して高い頑健性を示す。(2) KV キャッシュ、スパース/線形アテンション、量子化といった標準的な加速技術を用いることなく、リアルタイム生成を実現する。(3) 並列処理やシャーディングフレームワークなしでトレーニングを実施し、80 GB の GPU メモリ内に最大 4 つの 140 億パラメータモデルを収容しながら、画像拡散モデルに匹敵するバッチサイズでの学習を可能にする。具体的には、Helios は T2V(テキストから動画)、I2V(画像から動画)、V2V(動画から動画)タスクをネイティブにサポートする統一入力表現を備えた 140 億パラメータ規模の自己回帰拡散モデルである。長動画生成におけるドリフトを軽減するため、典型的な失敗モードを特徴付け、トレーニング中にドリフトを明示的にシミュレートするとともに、反復的動作の根源を排除する、簡潔かつ効果的なトレーニング戦略を提案する。効率性に関しては、歴史的およびノイズを含むコンテキストを大幅に圧縮し、サンプリングステップ数を削減することで、計算コストを 13 億パラメータ規模の動画生成モデルと同等、あるいはそれ以下に抑えている。さらに、推論とトレーニングの両方を加速し、メモリ消費を削減するインフラストラクチャレベルの最適化を導入している。広範な実験により、Helios が短動画および長動画の両方において先行手法を一貫して上回る性能を示すことが実証された。今後は、コミュニティのさらなる発展を支援するため、コード、ベースモデル、蒸留モデルの公開を予定している。
One-sentence Summary
Researchers from Peking University and ByteDance introduce Helios, a 14B autoregressive diffusion model that achieves real-time, minute-scale video generation without standard acceleration heuristics. By simulating drifting during training and compressing context, it outperforms prior methods while fitting multiple models on limited GPU memory.
Key Contributions
- Helios addresses the challenge of real-time, minute-scale video generation by eliminating common anti-drifting heuristics like self-forcing and error-banks through training strategies that explicitly simulate drifting and resolve repetitive motion at its source.
- The model achieves real-time speeds of 19.5 FPS on a single NVIDIA H100 GPU without standard acceleration techniques by compressing historical context and reformulating flow matching to reduce computational costs to levels comparable to 1.3B models.
- Extensive experiments show that Helios consistently outperforms prior methods on both short and long videos while enabling training without parallelism frameworks and fitting up to four 14B models within 80 GB of GPU memory.
Introduction
The demand for real-time, minute-scale video generation is critical for interactive applications like game engines, yet existing models struggle to balance speed, duration, and quality. Prior approaches often rely on small 1.3B models that lack the capacity for complex motion or depend on costly techniques like self-forcing and KV-cache to prevent temporal drifting and accelerate inference. The authors introduce Helios, a 14B autoregressive diffusion model that achieves 19.5 FPS on a single H100 GPU while supporting long-video generation without standard acceleration or anti-drifting heuristics. They address these challenges by explicitly simulating drifting during training to eliminate motion artifacts, compressing historical context to reduce computational load, and unifying text-to-video, image-to-video, and video-to-video tasks within a single efficient architecture.
Method
The authors propose Helios, an autoregressive video diffusion transformer designed to enable real-time long-video generation on a single GPU. The overall framework is depicted in the architecture diagram. The model treats long-video generation as a video continuation task by concatenating a historical context XHist and a noisy context XNoisy. This design facilitates Representation Control, allowing the system to unify Text-to-Video (T2V), Image-to-Video (I2V), and Video-to-Video (V2V) tasks. If the historical context is zero, the model performs T2V; if only the last frame is non-zero, it performs I2V; otherwise, it performs V2V. To handle the different statistics of the historical and noisy contexts, the authors introduce Guidance Attention within the DiT blocks. This mechanism explicitly separates the treatment of clean history and noisy future frames. In the self-attention layer, historical keys are modulated by amplification tokens to selectively strengthen their influence on the generation of future frames. In the cross-attention layer, semantic information from the text prompt is injected only into the noisy context to avoid redundancy, as the historical context has already incorporated these semantics.
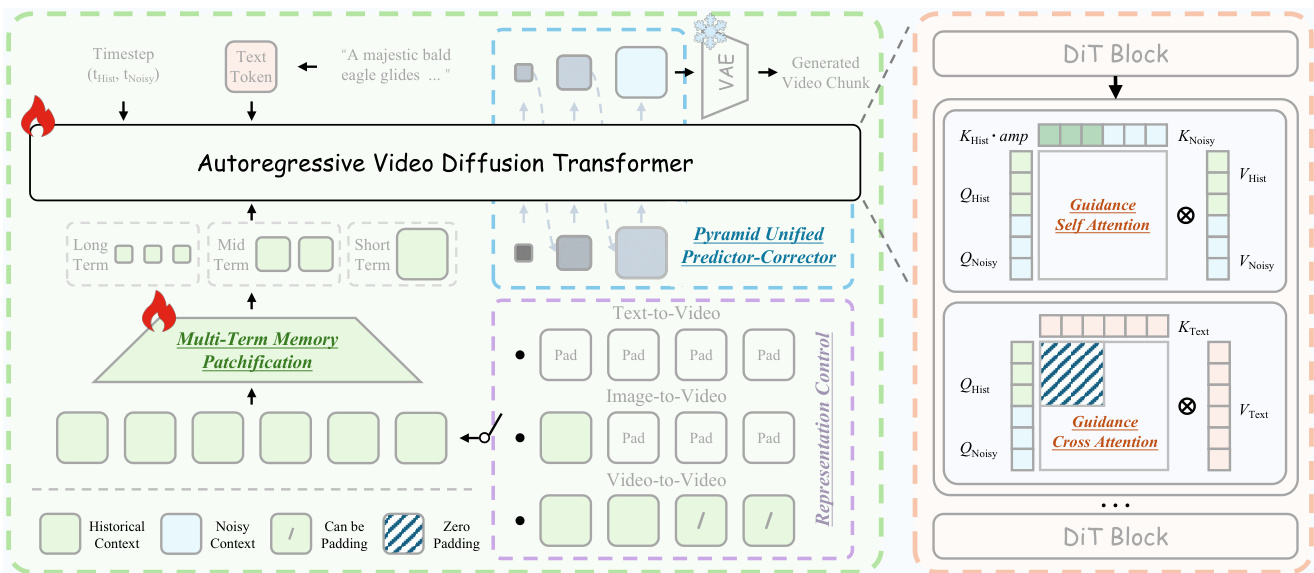
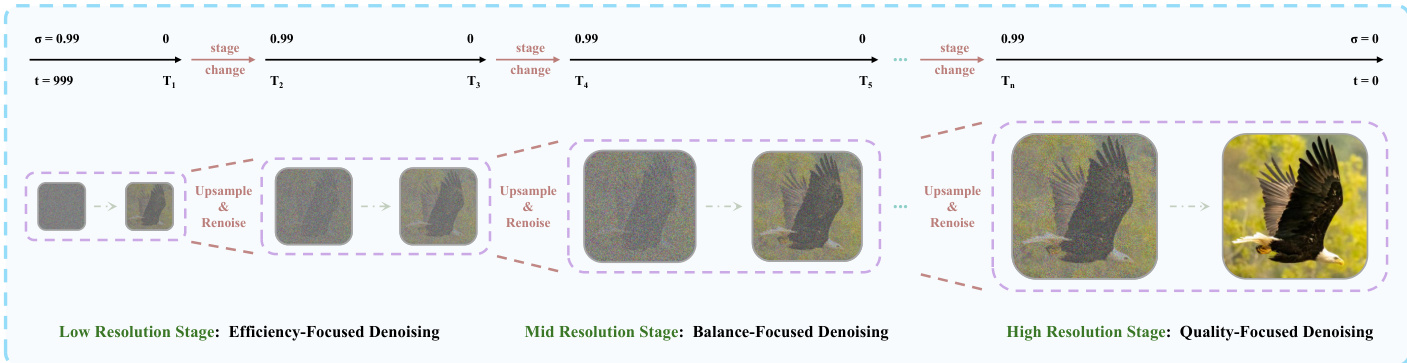
To reduce the computational overhead associated with large context windows, the authors employ Deep Compression Flow. This strategy involves two primary modules. First, Multi-Term Memory Patchification compresses the historical context by partitioning it into short, mid, and long-term windows. Independent convolution kernels are applied to each part, with the compression ratio increasing for temporally distant frames to maintain a constant token budget regardless of video length. Second, the Pyramid Unified Predictor Corrector reduces redundancy in the noisy context. As shown in the figure below, the generation process is divided into multiple stages with increasing spatial resolutions. The model begins with low-resolution denoising to efficiently establish global structure and progressively transitions to full resolution to refine fine-grained details. This coarse-to-fine schedule significantly reduces the number of processed tokens during the early sampling steps.
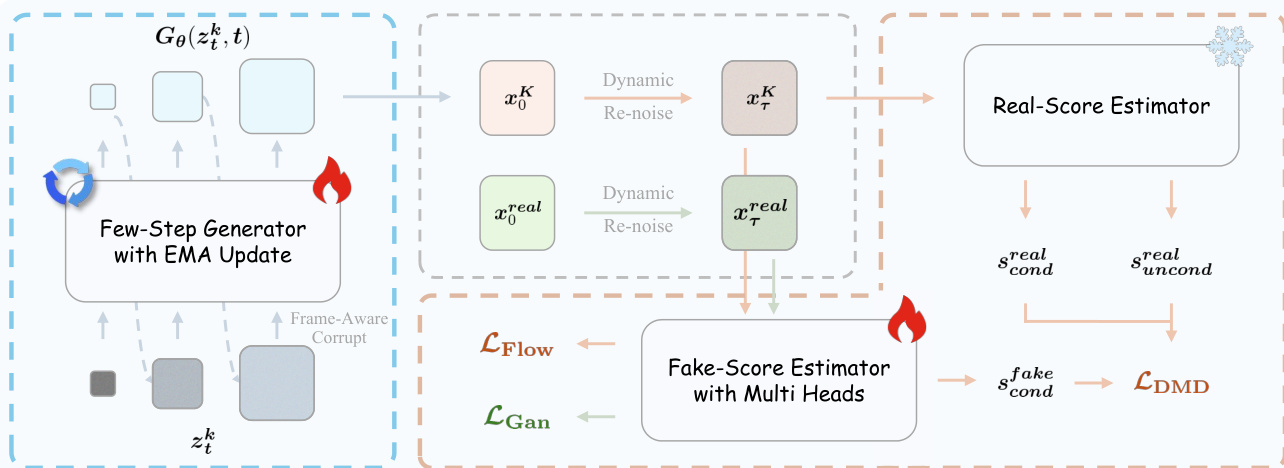
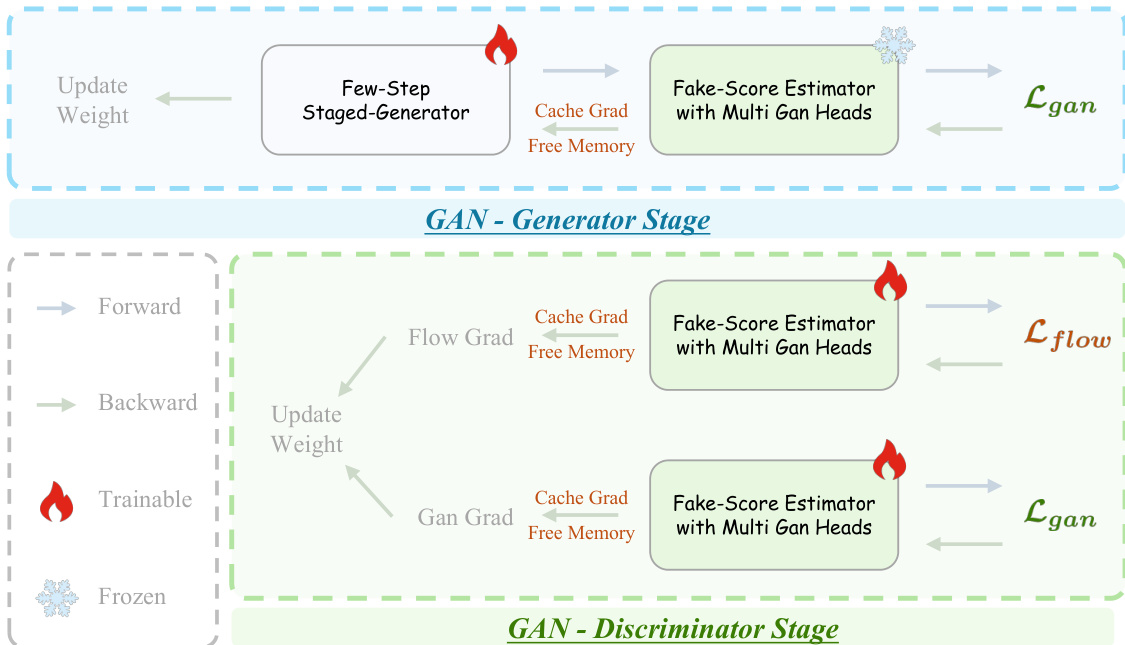
The training process utilizes Adversarial Hierarchical Distillation to distill a multi-step teacher model into a few-step student generator. The pipeline is illustrated in the distillation framework diagram. The system employs a Few-Step Generator with EMA Update and two score estimators: a Real-Score Estimator and a Fake-Score Estimator with Multi Heads. The generator is optimized using a distribution-matching loss (LDMD) derived from the difference between real and fake scores, alongside a flow-matching loss (LFlow) and a GAN loss (LGan). To address the memory constraints of training large models, the authors implement specific optimization strategies during the GAN stages. The training stages are detailed in the memory optimization diagram, which highlights the use of Cache Grad. By caching the discriminator gradients with respect to inputs, the system decouples backpropagation from the forward pass, allowing intermediate activations to be freed early. This approach substantially reduces peak memory usage, enabling the training of 14B parameter models on limited hardware.
Experiment
- Helios generates high-quality, coherent minute-scale videos without relying on common anti-drifting strategies or standard acceleration techniques, achieving real-time inference speeds on a single GPU.
- Comparative experiments demonstrate that Helios outperforms existing distilled and base models in visual fidelity, text alignment, and naturalness while maintaining superior motion smoothness and avoiding temporal jitter.
- Long-video evaluations confirm that Helios significantly reduces content drifting and preserves scene identity over hundreds of frames, surpassing baseline methods in both throughput and consistency.
- User studies validate that Helios is consistently preferred over prior real-time video generation models for both short and long-duration clips.
- Ablation studies reveal that key components such as Guidance Attention, First Frame Anchor, and Frame-Aware Corrupt are essential for preventing semantic accumulation, maintaining color consistency, and mitigating error propagation in long sequences.
- Architectural choices like Multi-Term Memory Patchification and Pyramid Unified Predictor Corrector enable scalable memory usage and doubled throughput without compromising video quality.
- Training strategies including Coarse-to-Fine Learning and Adversarial Post-Training are critical for stable convergence and enhancing perceptual realism beyond the limits of pure distillation.