Command Palette
Search for a command to run...
ArtHOI:動画事前知識に基づく 4 次元再構成による可動性を持つ人間 - 物体相互作用の合成
ArtHOI:動画事前知識に基づく 4 次元再構成による可動性を持つ人間 - 物体相互作用の合成
Zihao Huang Tianqi Liu Zhaoxi Chen Shaocong Xu Saining Zhang Lixing Xiao Zhiguo Cao Wei Li Hao Zhao Ziwei Liu
概要
3D/4D の教師信号を伴わずに、物理的に妥当な可動式人間 - 物体相互作用(HOI)を合成することは、依然として根本的な課題である。近年のゼロショット手法は、ビデオ拡散モデルを活用して人間 - 物体相互作用を合成するが、それらは主に剛体物体の操作に限定され、明示的な 4D 幾何学的推論を欠いている。このギャップを埋めるため、本研究では、単眼動画の事前知識に基づく 4D 再構成問題として可動式 HOI の合成を定式化する。すなわち、拡散モデルによって生成された動画のみを入力とし、3D 教師信号なしで完全な 4D 可動式シーンを再構成する。この再構成ベースのアプローチは、生成された 2D 動画を逆レンダリング問題の教師信号として扱い、接触、可動性、時間的一貫性を自然に満たす、幾何学的に整合性があり物理的に妥当な 4D シーンを復元する。本研究では、動画の事前知識に基づく 4D 再構成を通じて可動式人間 - 物体相互作用を合成する初のゼロショットフレームワーク「ArtHOI」を提案する。我々の主要な設計要素は以下の通りである。1)フローベースの部品セグメンテーション:光フローを幾何学的手がかりとして利用し、単眼動画における動的領域と静的領域を分離する。2)デカップル化された再構成パイプライン:単眼の曖昧性のもとでは、人体運動と物体の可動性の同時最適化が不安定となるため、まず物体の可動性を復元し、その後に復元された物体状態を条件として人体運動を合成する。ArtHOI は、動画ベースの生成と幾何学的知覚を備えた再構成を橋渡しし、意味的整合性と物理的妥当性の両方を兼ね備えた相互作用を生成する。多様な可動式シーン(例:冷蔵庫、キャビネット、電子レンジの開閉)における評価において、ArtHOI は接触精度、貫通の低減、可動性の忠実度において先行手法を大幅に上回り、再構成に裏打ちされた合成を通じて、剛体操作の枠組みを超えたゼロショット相互作用合成を実現する。
One-sentence Summary
Researchers from NTU S-Lab introduce ArtHOI, the first zero-shot framework synthesizing articulated human-object interactions by reformulating the task as a 4D reconstruction problem from monocular video priors. Unlike prior end-to-end generation methods limited to rigid objects, ArtHOI employs flow-based segmentation and a decoupled two-stage pipeline to recover physically plausible dynamics for complex articulated scenes like opening cabinets.
Key Contributions
- Existing zero-shot methods struggle to synthesize physically plausible interactions with articulated objects because they rely on rigid-body assumptions and lack explicit 4D geometric reasoning.
- ArtHOI introduces a novel two-stage reconstruction pipeline that treats monocular video generation as supervision for inverse rendering, using flow-based segmentation and decoupled optimization to recover articulated object dynamics and human motion without 3D supervision.
- Experiments on diverse scenarios like opening fridges and cabinets demonstrate that ArtHOI significantly outperforms prior approaches in contact accuracy, penetration reduction, and articulation fidelity.
Introduction
Synthesizing physically plausible human interactions with articulated objects, such as opening cabinets or doors, is critical for advancing robotics, virtual reality, and embodied AI. Prior zero-shot methods relying on video diffusion models struggle in this domain because they treat objects as rigid bodies and lack explicit 4D geometric reasoning, leading to physically implausible results and an inability to model complex part-wise kinematics. To address these limitations, the authors introduce ArtHOI, the first zero-shot framework that formulates articulated interaction synthesis as a 4D reconstruction problem from monocular video priors. Their approach leverages a decoupled pipeline that first recovers object articulation using optical flow cues and then synthesizes human motion conditioned on the reconstructed object states, ensuring geometric consistency and physical plausibility without requiring 3D supervision.
Method
The authors address the problem of synthesizing physically plausible articulated human-object interactions from monocular video priors by formulating it as a 4D reconstruction problem. To resolve the ambiguity between human movement and object articulation under weak 2D supervision, they employ a decoupled two-stage reconstruction framework. As illustrated in the framework diagram, the pipeline takes a monocular video and reconstructs a full 4D articulated scene using 3D Gaussians. The architecture separates the optimization into Stage I, which recovers object articulation with kinematic constraints, and Stage II, which refines human motion conditioned on the reconstructed geometry.
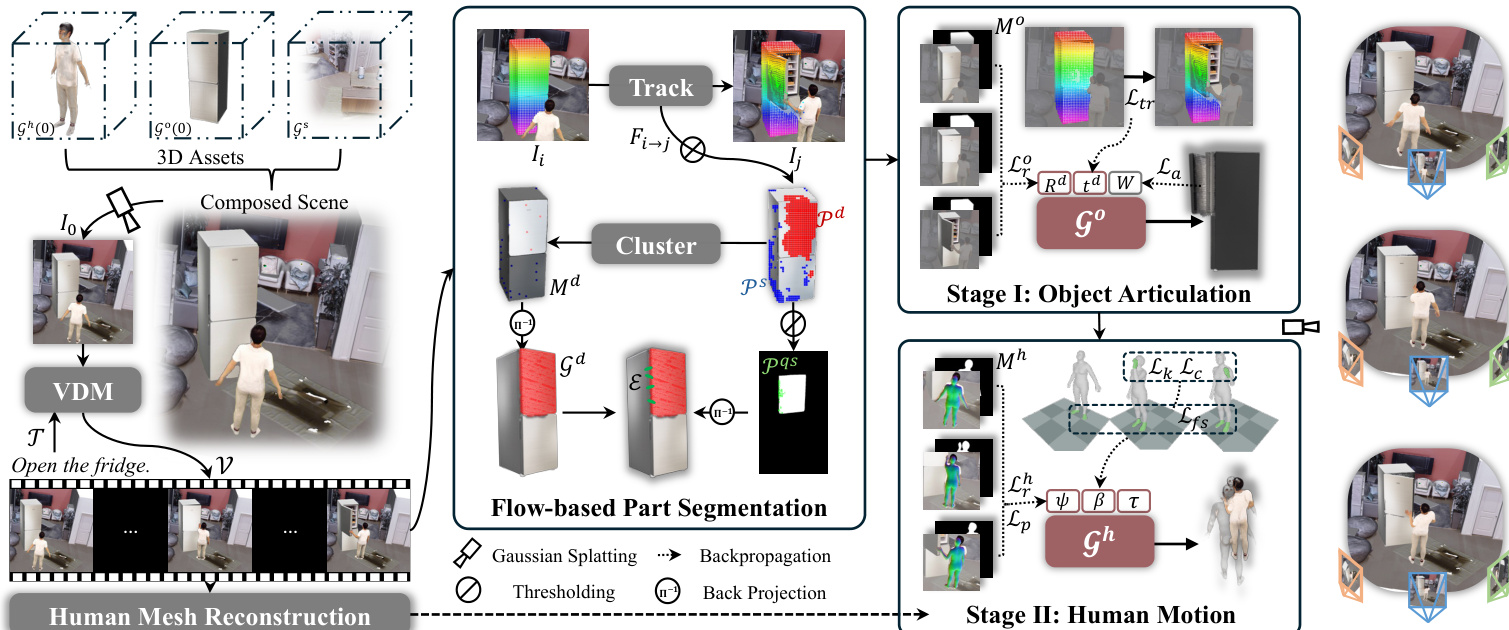
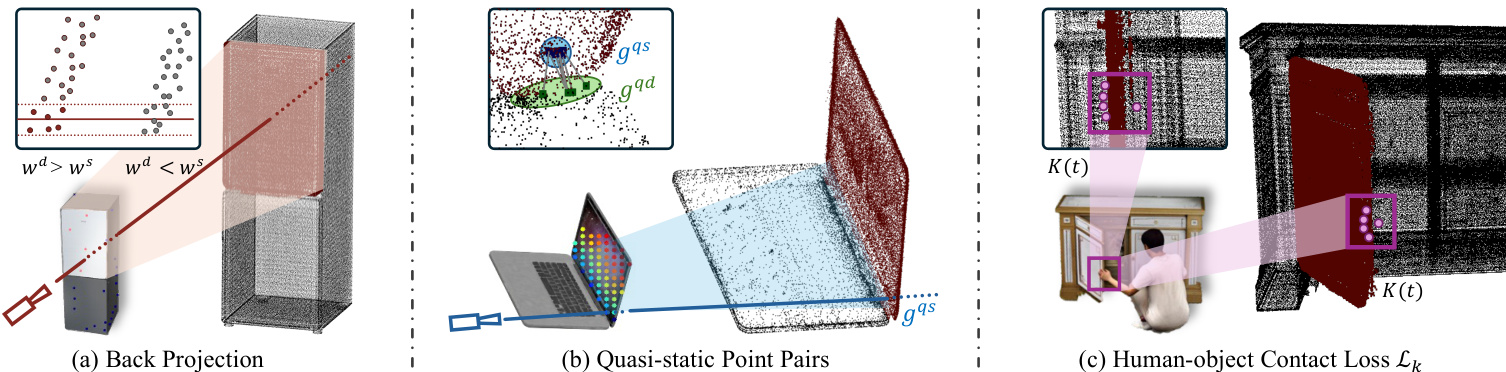
To enable kinematic modeling, the system first identifies which object regions are articulated through a flow-based part segmentation pipeline. This module combines point tracking, SAM-guided masks, and back projection to 3D. The system tracks dense 2D trajectories to classify points as dynamic or static, then uses the Segment Anything Model to produce binary masks. These masks are transferred to the 3D Gaussian representation via back projection, where pixel influences are accumulated to assign Gaussians to dynamic or static sets. To enforce rigid-body constraints, quasi-static point pairs are identified at the articulation boundary to link dynamic and static regions. The key components for this articulated interaction under monocular supervision are detailed in the figure below, which depicts back projection mapping masks to 3D, quasi-static point pairs linking regions, and the contact loss mechanism.
In Stage I, the system reconstructs object articulation by optimizing SE(3) transformations Td(t) for the dynamic parts while keeping static parts fixed. The optimization objective integrates a reconstruction loss to match the video prior, a tracking loss to align with point trajectories, and an articulation loss to maintain connectivity between binding pairs. The total loss is formulated as:
{Rd,td}minLro+λaLa+λsLs+λtrLtr.The articulation loss La penalizes changes in distance between binding pairs (gd,gs)∈E, ensuring the object parts move as a rigid body. This stage establishes a geometrically consistent 4D object scaffold.
In Stage II, the human motion is refined conditioned on the fixed object geometry. The authors derive 3D contact keypoints by identifying frames where the human mask overlaps the object silhouette but the object mask is absent, indicating occlusion by the human hand. These 2D regions are lifted to 3D using the depth of the nearest dynamic object Gaussians. The human parameters (SMPL-X) are then optimized to minimize a kinematic loss that pulls hand joints toward these 3D targets, alongside reconstruction, prior, foot sliding, and collision losses. The kinematic loss is defined as:
Lk=t=1∑Tj∈Kt∑∥Jj(θ(t))−Kj(t)∥22,where Kj(t) represents the derived 3D contact targets. This ensures physically plausible interactions without requiring multi-view input.
Experiment
- Comprehensive experiments on zero-shot articulated human-object interaction synthesis validate that the proposed method achieves superior geometric consistency, physical plausibility, and temporal coherence compared to state-of-the-art baselines.
- Interaction quality evaluations demonstrate that the approach generates more realistic foot contact, higher hand-object contact rates, and lower physical penetration than existing methods, while maintaining competitive motion smoothness.
- Articulated object dynamics tests confirm the framework's ability to accurately recover joint rotations from monocular video, significantly outperforming specialized methods designed for articulated object estimation.
- Experiments on rigid objects show that the reconstruction-informed synthesis generalizes effectively, producing better contact accuracy and physical plausibility than methods relying on depth priors or video diffusion alone.
- A user study with diverse participants reveals a strong preference for the proposed method over all baselines, particularly regarding the realism of interactions and the quality of contact.
- Ablation studies verify that the two-stage decoupled optimization, articulation regularization, and kinematic loss are critical components, as their removal leads to unstable convergence, geometric drift, and misaligned human-object contact.