Command Palette
Search for a command to run...
異種 Agent 協調強化学習
異種 Agent 協調強化学習
Zhixia Zhang Zixuan Huang Xin Xia Deqing Wang Fuzhen Zhuang Shuai Ma Ning Ding Yaodong Yang Jianxin Li Yikun Ban
概要
我々は、孤立したオンポリシー最適化の非効率性を解決する新たな学習パラダイムである「異種エージェント協調強化学習(Heterogeneous Agent Collaborative Reinforcement Learning: HACRL)」を導入する。HACRL は、独立した実行を可能にする協調最適化を実現する。具体的には、異種エージェントは訓練中に検証済みのロールアウトを共有して相互に性能を向上させる一方、推論時には独立して動作する。大規模言語モデル(LLM)に基づく多エージェント強化学習(MARL)とは異なり、HACRL は協調デプロイを必要とせず、オンポリシー/オフポリシー蒸留とは異なり、一方向的な教師から生徒への転移ではなく、異種エージェント間の双方向的な相互学習を可能にする。このパラダイムに基づき、原則的なロールアウト共有を通じてサンプル利用率とエージェント間知識転移を最大化する協調強化学習アルゴリズム「HACPO」を提案する。HACPO は、能力の差異や方策分布のシフトを緩和するため、不偏なアドバンテージ推定と最適化の正確性について理論的保証を有する 4 つの専用メカニズムを導入する。多様な異種モデルの組み合わせおよび推論ベンチマークにおける広範な実験により、HACPO は参加するすべてのエージェントの性能を一貫して向上させ、GSPO を平均 3.3 パーセント上回る性能を、ロールアウトコストの半分のみで達成することが示された。
One-sentence Summary
Researchers from Beihang University and collaborating institutes propose HACRL, a paradigm enabling heterogeneous agents to share verified rollouts for mutual improvement without coordinated deployment. Their algorithm, HACPO, introduces bidirectional learning mechanisms that outperform GSPO in reasoning benchmarks while halving rollout costs.
Key Contributions
- Heterogeneous Agent Collaborative Reinforcement Learning (HACRL) addresses the inefficiencies of isolated on-policy optimization by enabling heterogeneous agents to share verified rollouts during training while maintaining independent execution at inference time.
- The proposed HACPO algorithm implements this paradigm through four tailored mechanisms that mitigate capability discrepancies and policy distribution shifts to ensure unbiased advantage estimation and maximize sample utilization.
- Extensive experiments across diverse heterogeneous model combinations and reasoning benchmarks demonstrate that HACPO consistently improves all participating agents, outperforming GSPO by an average of 3.3% while using only half the rollout cost.
Introduction
Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard for training strong reasoning models, yet it suffers from high computational costs due to isolated on-policy sampling where each agent generates and discards its own trajectories. Prior approaches like Multi-Agent Reinforcement Learning require coordinated execution that is impractical for independent deployment, while knowledge distillation typically enforces a one-way transfer from a teacher to a student that limits bidirectional learning among heterogeneous models. The authors introduce Heterogeneous Agent Collaborative Reinforcement Learning (HACRL) and its algorithm HACPO to enable independent agents to share verified rollouts during training for mutual improvement. This framework maximizes sample efficiency by reusing trajectories across multiple agents and ensures unbiased optimization through four tailored mechanisms that address capability discrepancies and policy distribution shifts.
Method
The authors propose Heterogeneous Agent Collaborative Policy Optimization (HACPO), a novel framework designed to facilitate rollout sharing and knowledge transfer among heterogeneous Large Language Model (LLM) agents. Unlike traditional Multi-Agent Reinforcement Learning (MARL) which often relies on joint responses or Knowledge Distillation which follows a one-way path, HACRL enables independent execution with mutual learning through cross-agent rollout reuse.
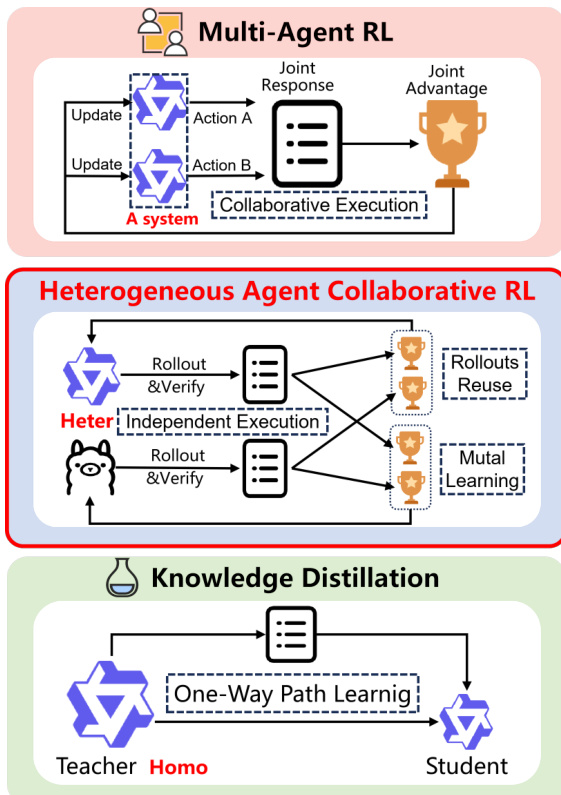
The core objective of HACRL is to optimize each agent k by maximizing a joint objective that combines self-generated experiences (Jhomo) and cross-agent information (Jhete). This formulation allows agents to benefit from the diverse capabilities of their peers while managing the challenges introduced by heterogeneity.
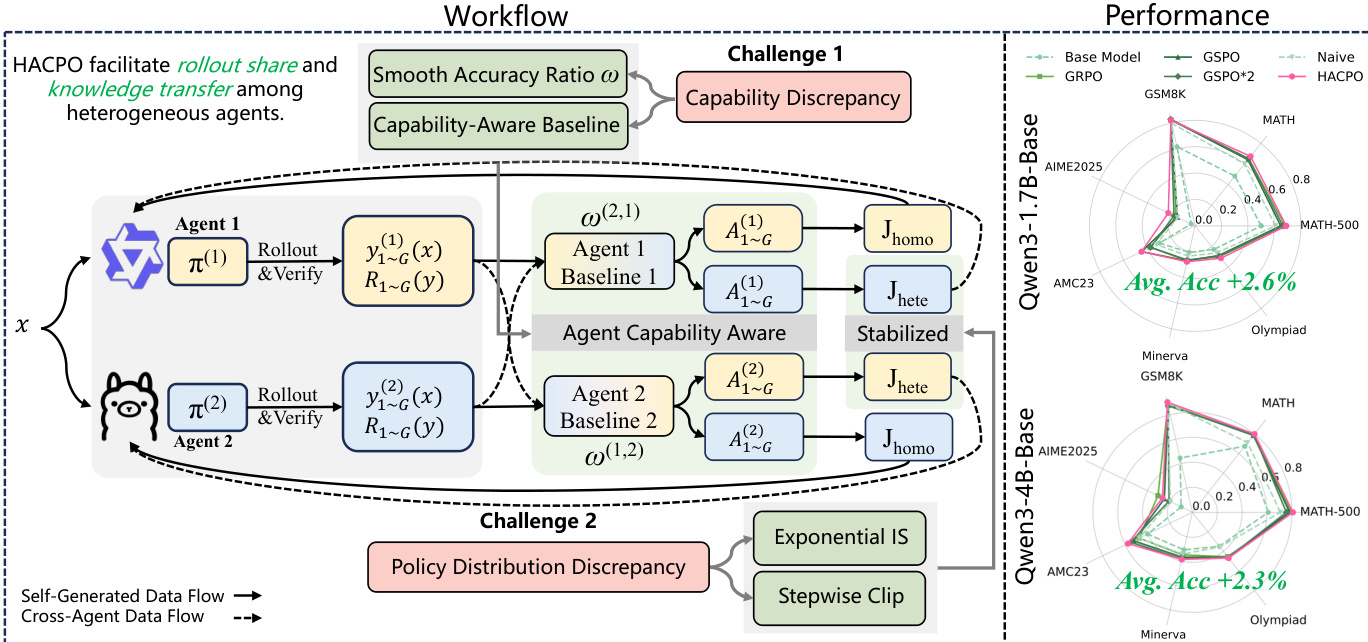
As illustrated in the workflow diagram, the training process involves two primary challenges: capability discrepancy and policy distribution discrepancy. To address these, HACPO incorporates four tailored modifications.
Agent-Capability-Aware Advantage Estimation Standard group-relative advantage estimation relies solely on self-generated rewards, which is suboptimal in heterogeneous settings. HACPO introduces a capability-adjusted baseline μ^t(k) that leverages rewards from all agents, reweighted by their relative capabilities. The advantage for a response yt,i(k) is defined as:
At,i(k)=σt,jointR(yt,i(k))−μ^t(k)where σt,joint is the standard deviation of rewards across all agents. The baseline μ^t(k) is computed using a capability ratio ωt(k,j):
μ^t(k)=nG1j=1∑ni=1∑Gωt(k,j)R(yt,i(j))Here, ωt(k,j) represents the smoothed performance ratio between agent k and agent j, ensuring that the baseline is properly calibrated across agents with different strengths.
Model Capabilities Discrepancy Coefficient To further handle capability gaps, the framework applies the capability ratio directly to the advantage when updating an agent using cross-agent samples. When agent k learns from a response generated by agent j, the effective advantage is scaled:
A~t,i(k)=ωt(j,k)At,i(j)This mechanism encourages aggressive learning from stronger agents while adopting a conservative update strategy for samples from weaker agents.
Exponential Importance Sampling To correct for distributional mismatches between the policy generating the sample and the policy being updated, HACPO employs sequence-level importance sampling. For a response yt,i(j) generated by agent j and used to update agent k, the importance ratio is:
st,i(k,j)=πθold(j)(yt,i(j))πθt(k)(yt,i(j))∣yt,i(j)∣1Given that inter-agent policy discrepancies can be large, the authors introduce a non-gradient exponential reweighting to mitigate aggressive updates:
s~t,i(k,j)=st,i(k,j)⋅(sg[st,i(k,j)])αwhere α≥0 controls the degree of conservativeness.
Stepwise Clipping Finally, to stabilize training and prevent cross-agent rollouts from dominating the gradient updates, HACPO utilizes an asymmetric clipping scheme. Unlike standard symmetric clipping, the upper bound for cross-agent importance ratios is strictly limited to 1.0:
st.i(k,j)∈[1.0−δ,1.0]Additionally, a stepwise clipping strategy is applied within each training step. As the number of parameter updates k increases, the lower bound tightens:
clip(st,i(k,j))=clip(st,i(k,j),1−δ+k⋅δstep,1.0)This ensures that cross-agent responses are subject to increasingly stricter constraints as the training step progresses, maintaining stability in the heterogeneous collaborative policy optimization process.
Experiment
- Experiments across three heterogeneity settings (state, size, and model architecture) validate that HACPO outperforms single-agent baselines and naive multi-agent approaches by enabling bidirectional knowledge exchange between agents of varying capabilities.
- Qualitative analysis confirms that stronger models benefit from the complementary exploration signals and informative errors of weaker agents, while weaker models gain from the guidance of stronger peers, proving that learning is not purely unidirectional.
- Ablation studies demonstrate that agent-capability-aware advantage estimation and gradient modulation are essential for correcting systematic biases and balancing learning rates between heterogeneous agents.
- The necessity of stepwise clipping is established as a critical mechanism for stabilizing training, preventing the severe instability caused by unpredictable importance sampling values in cross-agent responses.
- Results across diverse model combinations, including different architectures and tokenizers, confirm the robustness and generalizability of the proposed method in extracting transferable knowledge from heterogeneous rollouts.