Command Palette
Search for a command to run...
LongCat-Flash-Thinking-2601 技術報告
LongCat-Flash-Thinking-2601 技術報告
概要
LongCat-Flash-Thinking-2601 を紹介します。これは、優れたエージェント型推論能力を備えた、5600億パラメータのオープンソースMixture-of-Experts(MoE)推論モデルです。LongCat-Flash-Thinking-2601 は、エージェント型検索、エージェント型ツール利用、およびツール統合型推論を含む、幅広いエージェント系ベンチマークにおいて、オープンソースモデルの中でも最先端の性能を達成しています。ベンチマーク上の優れた性能に加え、複雑なツール連携への強力な汎化能力と、ノイズの多い現実世界環境下でも堅牢な挙動を示す点でも優れています。この高度な能力は、ドメイン並列専門家学習とその後の統合を組み合わせた統一された学習フレームワークに由来しており、事前学習から事後学習に至るまで、データ構築、環境設計、アルゴリズム、インフラのエンドツーエンド共同設計が実現されています。特に、複雑なツール利用における強力な汎化能力は、環境スケーリングと原則に基づいたタスク構築に関する深層的な探索に起因しています。長尾分布・偏りのある生成および複数ターンのエージェント型対話処理を最適化し、20以上のドメインにまたがる10,000以上の環境で安定した学習を実現するため、安定的かつ効率的な大規模マルチ環境学習を可能にする非同期強化学習フレームワーク「DORA」を体系的に拡張しました。さらに、現実世界のタスクは本質的にノイズを含むことから、現実のノイズパターンを体系的に分析・分解し、その不完全性を学習プロセスに明示的に組み込むための対応する学習手順を設計しました。これにより、実世界応用における耐障害性が向上しました。さらに、複雑な推論タスクにおける性能を向上させるために、「Heavy Thinkingモード」を導入しました。このモードにより、並列的な思考を強化することで、テスト時における推論の深さと幅を同時に拡張し、効果的なテスト時スケーリングを実現しています。
One-sentence Summary
The Meituan LongCat Team introduces LongCat-Flash-Thinking-2601, a 560B MoE model excelling in agentic reasoning via unified domain-parallel training and noise-aware design, enabling robust tool use across 10K+ environments and enhanced performance through Heavy Thinking mode for real-world applications.
Key Contributions
- LongCat-Flash-Thinking-2601 introduces a unified training framework combining domain-parallel expert training and fusion, enabling state-of-the-art open-source performance on agentic benchmarks like BrowseComp (73.1%) and RWSearch (77.7%) through end-to-end co-design of data, environments, and infrastructure.
- The model leverages an extended asynchronous RL system, DORA, to stabilize training across over 10,000 environments spanning 20+ domains, while incorporating real-world noise patterns into training to improve robustness in noisy, out-of-distribution settings.
- It features a Heavy Thinking mode for test-time scaling that jointly expands reasoning depth and width via parallel thinking, enhancing complex reasoning performance without requiring additional training, and is released open-source to support future agentic system research.
Introduction
The authors leverage a 560-billion-parameter Mixture-of-Experts model to advance agentic reasoning — the ability to solve complex tasks through adaptive interaction with external environments, such as tools or search systems. Prior models struggle with long-horizon, multi-domain interactions and real-world noise, often lacking scalable training infrastructure or robustness to imperfect environments. Their main contribution is a unified training pipeline that combines domain-parallel expert training, automated multi-domain environment scaling, and noise-injection via curriculum-based RL to improve generalization. They also introduce a Heavy Thinking mode that boosts test-time performance by expanding reasoning depth and width in parallel, enabling state-of-the-art results on open-source agentic benchmarks.
Dataset

-
The authors use a dual-environment framework for agentic training: one for coding (executable code sandbox) and one for general tool use (domain-specific tool graphs), both designed to support scalable, reproducible, and diverse interaction patterns.
-
For the code sandbox, they build a high-throughput system that standardizes terminal tools (search, file I/O, shell execution) and schedules thousands of concurrent sandboxes via asynchronous provisioning to eliminate startup overhead during training.
-
For tool-use environments, they construct over 20 domain-specific tool graphs (each with 60+ tools) using an automated pipeline that converts high-level domain specs into executable tool-database pairs, validated via unit tests and debugging agents (95% success rate).
-
Each environment begins with a sampled seed tool chain; it’s expanded via controlled BFS-style graph growth to preserve database consistency and executable correctness, avoiding cascading dependency failures.
-
Environments can be further complexified by adding new seed chains based on structural complexity, remaining node count, and solver difficulty — with a fallback to ensure at least 20 tools per environment.
-
Cold-start training data is sourced from real-world platforms (for coding/math) or synthesized (for search/tool-use), with strict filtering: executability checks, action-level pruning, and rubric-based validation.
-
For general thinking, they use a K-Center-Greedy selection with sliding-window perplexity to prioritize samples that expose reasoning gaps, downsampling 210K high-quality trajectories.
-
For agentic coding, trajectories are filtered for full executability, functional correctness, and long-horizon reasoning — with earlier steps compressed to retain context without length penalty.
-
For agentic search, synthetic trajectories enforce multi-step evidence gathering, explicit condition verification, and robustness against shortcuts; trivial cases are removed.
-
For agentic tool-use, they generate tasks across 33 domains with variable structure, length, and multiple valid solutions; turn-level loss masking excludes failed or malformed actions during training.
-
All synthesized tasks include three components: task description, user profile, and evaluation rubrics — validated via consistency checks to ensure reliable supervision and reject incomplete trajectories.
Method
The authors leverage a multi-stage training framework designed to scale agentic reasoning capabilities in large language models, beginning with a pre-training phase that extends the LongCat-Flash-Chat recipe to incorporate structured agentic data. This phase addresses the dual challenges of long-context modeling efficiency and the scarcity of real-world agentic trajectories. To manage long-context requirements, a staged mid-training procedure is employed, progressively increasing context lengths and allocating specific token budgets to 32K, 128K, and 256K stages. The model is exposed to moderate-scale agentic data to establish foundational behaviors before reinforcement learning. To overcome the scarcity of high-quality agentic trajectories, a hybrid data synthesis pipeline is constructed, drawing from both unstructured text and executable environments. Text-driven synthesis mines implicit procedural knowledge from large-scale corpora, converting abstract workflows into explicit multi-turn user-agent interactions through text filtering, tool extraction, and refinement. This process is further enhanced with decomposition-based augmentations, including tool decomposition, which iteratively hides parameters into the environment, and reasoning decomposition, which generates alternative action candidates to transform trajectories into multi-step decision-making processes. Environment-grounded synthesis ensures logical consistency by implementing lightweight Python environments for toolsets and modeling tool dependencies as a directed graph. Valid tool execution paths are sampled from this graph, and corresponding system prompts are reverse-synthesized and verified through code execution, guaranteeing the correctness of the generated trajectories. A dedicated planning-centric data augmentation strategy is also introduced to explicitly strengthen planning ability, transforming existing trajectories into structured decision-making processes through problem decomposition and candidate selection. 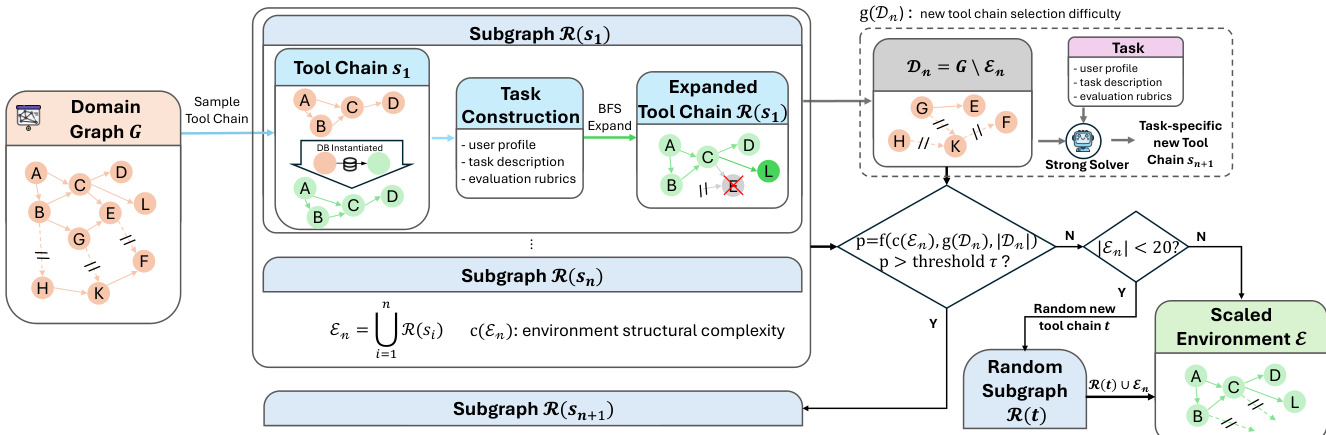
Following pre-training, the model undergoes a scalable reinforcement learning (RL) phase to elicit stronger reasoning capabilities. This phase is built upon a unified multi-domain post-training pipeline that first trains domain-specialized expert models under a shared framework and then consolidates them into a single general model. The RL framework is designed to handle the unique challenges of agentic training, including the need for scalable environment construction, high-quality cold-start data, and well-calibrated task sets, as well as the requirement for a dedicated infrastructure to support high-throughput, asynchronous, and long-tailed multi-turn rollouts. The authors extend their multi-version asynchronous training system, DORA, to support this setting. The core of the system is a producer-consumer architecture, as illustrated in the framework diagram, which consists of a RolloutManager, a SampleQueue, and a Trainer, running on different nodes and coordinating via Remote Procedure Call (RPC). This architecture enables a fully streaming asynchronous pipeline, removing batch barriers to minimize device idleness during multi-turn rollouts. To address the long-tailed generation problem, the system supports multi-version asynchronous training, where trajectories from different model versions are immediately enqueued upon completion, allowing the Trainer to initiate training as soon as conditions are met. 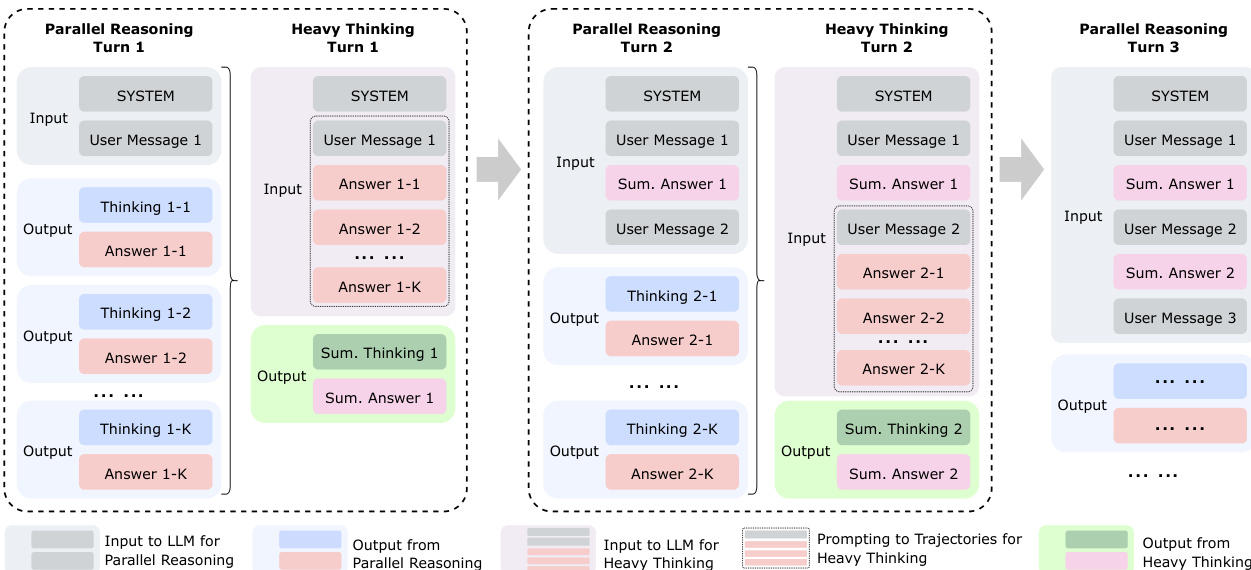
To scale to large-scale agentic training, the system decomposes the RolloutManager into a Lightweight-RolloutManager for global control and multiple RolloutControllers for managing virtual rollout groups in a data-parallel manner. This design, combined with an extension of the PyTorch RPC framework to provide CPU-idleness-aware remote function invocation, enables the efficient deployment of massive environments across thousands of accelerators. A key technique for efficient generation of large models like LongCat-Flash-Thinking-2601 is Prefill-Decode (PD) Disaggregation, which separates the prefetch and decode workloads into distinct device groups. This prevents the decode execution graph from being interrupted by prefetch workloads, maintaining high throughput during multi-turn rollouts. To mitigate the associated challenges of KV-cache transfer and recomputation, the system aggregates KV-cache blocks in chunks for asynchronous transmission and introduces a CPU-resident KV-cache that dynamically swaps blocks in and out as needed, eliminating recomputation overhead due to insufficient on-device memory. 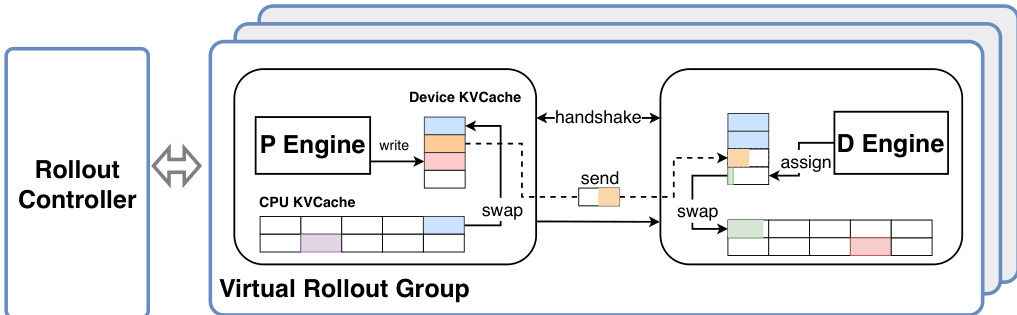
The RL training strategy is designed to be stable, efficient, and scalable. The authors adopt Group Sequence Policy Optimization (GSPO) as the training objective, which provides more stable sequence-level optimization for long-horizon agentic trajectories. A curriculum learning strategy is employed to progressively increase task difficulty along two axes: task difficulty, quantified by the model's pass rate, and capability requirement, such as basic tool invocation or multi-step planning. This allows the model to first acquire reusable skills before composing them to solve complex problems. Dynamic budget allocation is applied within each training batch to prioritize tasks that provide higher learning value, using a dynamic value function that estimates the value of a task based on the model's real-time training state. This strategy adapts to the model's evolving capabilities, ensuring that the most informative tasks are allocated more rollout budget. Self-verification is introduced as an auxiliary task, where the model evaluates its own on-policy trajectories, which accelerates optimization and improves generation performance. 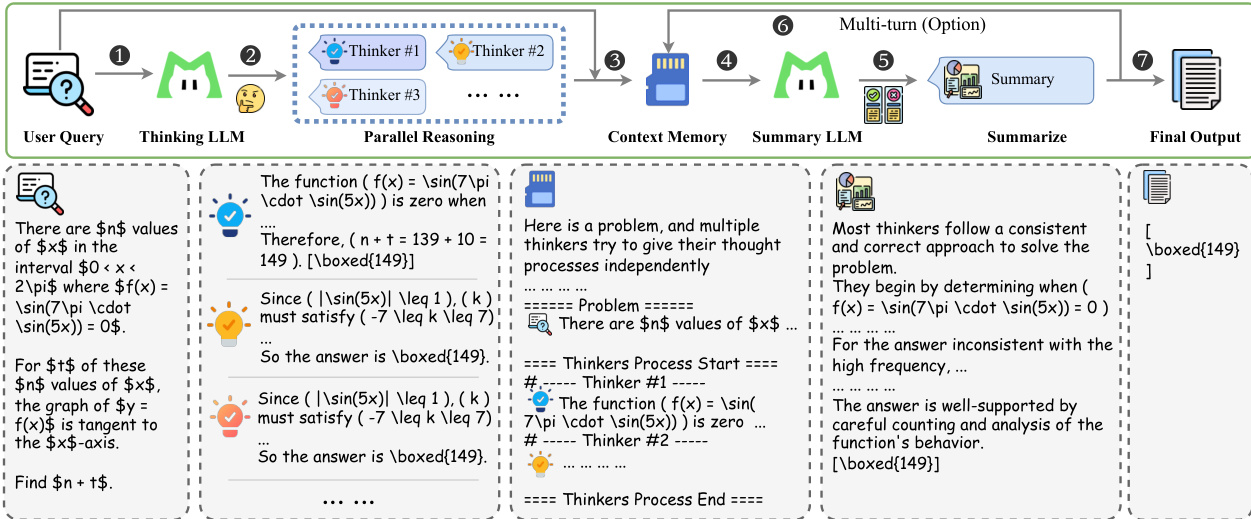
In agentic scenarios, effective context management is critical. The authors design a hybrid context management strategy that combines summary-based and discard-based approaches. When the context window exceeds a predefined limit of 80K tokens, the model performs a summary-based compression, distilling historical tool call results into a concise summary. When the interaction exceeds the maximum number of turns, a discard-all reset is triggered, restarting generation with an initialized system and user prompt. This hybrid strategy dynamically switches between compression and reset based on context window and interaction turn constraints, achieving a favorable trade-off between retaining critical reasoning context and controlling computational overhead. For training with scaled environments, a multi-domain environment training strategy is adopted, jointly optimizing across diverse environments within each training batch. To maintain training stability and prevent domain imbalance, separate oversampling ratios are configured for different data types and domains, ensuring that challenging or low-throughput domains contribute sufficient samples without blocking the pipeline. 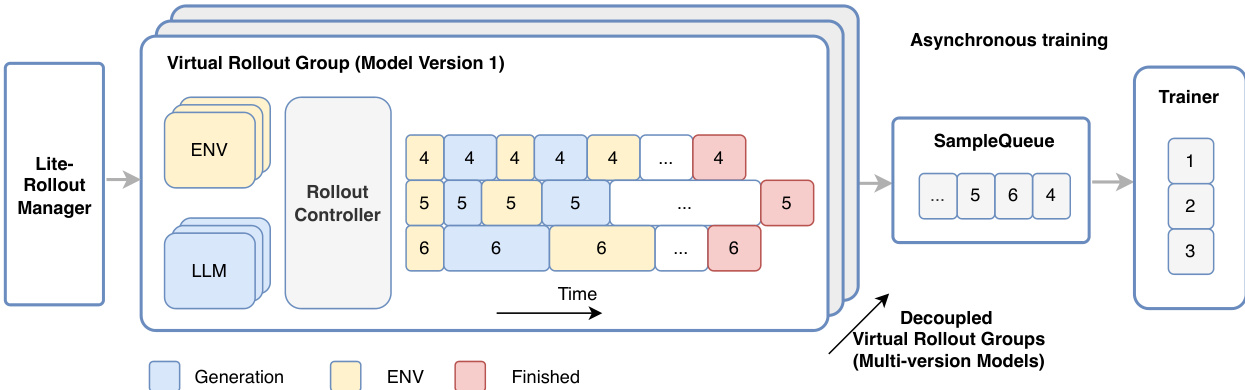
To improve robustness, the training process explicitly incorporates environmental imperfections, such as instruction noise and tool noise, using a curriculum-based strategy that progressively increases noise difficulty. This ensures the model learns resilient behaviors under non-ideal conditions. Finally, the authors propose a test-time scaling framework called heavy thinking, which decomposes computation into two stages: parallel reasoning and heavy thinking. In the first stage, a thinking model generates multiple candidate reasoning trajectories in parallel. In the second stage, a summary model conducts reflective reasoning over these trajectories to synthesize a final decision. This framework is supported by a context memory module to store message history and a specific prompt template to organize the parallel trajectories for the summary model. 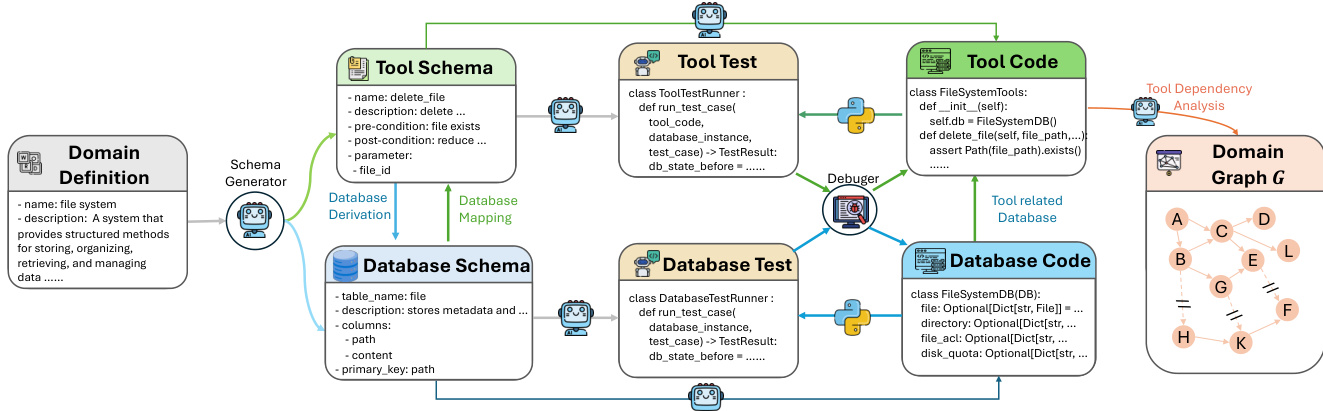
Experiment
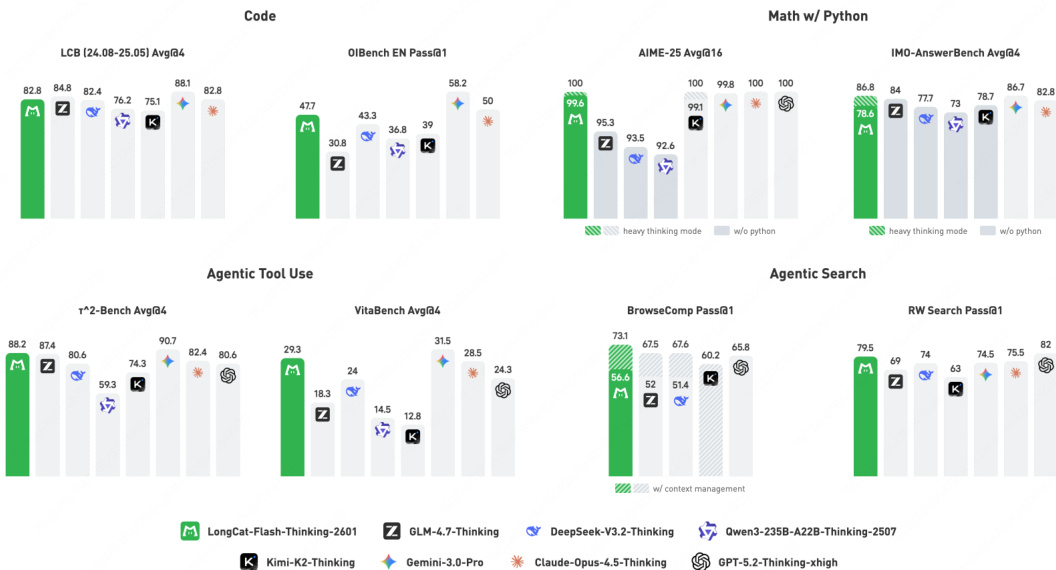
- Mathematical Reasoning: Achieved perfect score on AIME-2025, 86.8 on IMO-AnswerBench, and open-source SOTA on AMO-Bench (EN/zh), matching top closed-source models in heavy mode.
- Agentic Search: Set SOTA on BrowseComp (73.1) and BrowseComp-ZH (77.7) with context management; scored 79.5 on RWSearch, second only to GPT-5.2-Thinking.
- Agentic Tool-Use: Achieved open-source SOTA on τ²-Bench, VitaBench, and Random Complex Tasks, showing strong noise robustness and generalization.
- General QA: Scored 25.2 on HLE text-only subset and 85.2 on GPQA-Diamond (heavy mode), nearing open-source SOTA.
- Coding: Ranked top open-source on OIBench, second on OJBench, competitive on LiveCodeBench and SWE-bench Verified; outperformed GLM-4.7 with 45k vs 57k tokens per problem.
- Context Management: Optimal performance on BrowseComp at 80K token summary threshold (66.58% Pass@1).
Results show that LongCat-Flash-Thinking-2601 achieves state-of-the-art performance on mathematical reasoning benchmarks, including a perfect score on AIME-25 and a leading score on IMO-AnswerBench, while also demonstrating strong capabilities in agentic search, tool use, general QA, and coding across multiple benchmarks. The model consistently outperforms or matches leading open-source and closed-source models, particularly in tool-integrated reasoning and agentic tasks, with competitive results on both standard and noise-augmented benchmarks.

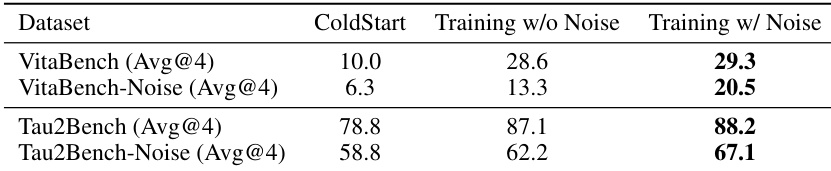
Results show that training with noise improves performance on both VitaBench and τ²-Bench, with the best results achieved when training includes noise, particularly on τ²-Bench where the score increases from 78.8 to 88.2. The performance on noise-augmented versions of the benchmarks also improves, indicating enhanced robustness.
The authors use a comprehensive set of benchmarks to evaluate LongCat-Flash-Thinking-2601 across mathematical reasoning, agentic search, tool use, general reasoning, and coding. Results show that LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on most tasks, particularly excelling in mathematical reasoning and agentic search, while also demonstrating strong generalization and robustness in tool-integrated reasoning.