Command Palette
Search for a command to run...
表現自己符号化器を用いたテキストから画像への拡散Transformerのスケーリング
表現自己符号化器を用いたテキストから画像への拡散Transformerのスケーリング
Shengbang Tong Boyang Zheng Ziteng Wang Bingda Tang Nanye Ma Ellis Brown Jihan Yang Rob Fergus Yann LeCun Saining Xie
概要
表現自動符号化器(Representation Autoencoders: RAEs)は、ImageNetにおける拡散モデルにおいて、高次元の意味的潜在空間で学習を行うことにより、顕著な優位性を示している。本研究では、このフレームワークが大規模かつ自由形式のテキストから画像への生成(Text-to-Image: T2I)にスケーラブルであるかどうかを検証する。まず、SigLIP-2という固定された表現エンコーダ上で、Webデータ、合成データ、テキストレンダリングデータを用いてRAEのデコーダをImageNetを超えてスケーリングした。その結果、スケーリングにより一般化された忠実度が向上する一方で、テキストのような特定のドメインにおいては、データ構成のターゲティングが不可欠であることが明らかになった。次に、ImageNet向けに当初提案されたRAEの設計選択を厳密に検証した。分析の結果、スケーリングが進むにつれてフレームワークが単純化されることが判明した。特に、次元依存のノイズスケジューリングは依然として重要であるが、広い拡散ヘッドやノイズ増強デコードといったアーキテクチャ上の複雑さは、スケールが大きくなるとほとんど恩恵をもたらさないことが示された。この単純化されたフレームワークを基盤とし、パラメータ数が0.5Bから9.8Bに至る拡散トランスフォーマーのスケールにおいて、最先端のFLUX VAEと比較してRAEの性能を制御された条件下で評価した。結果として、すべてのモデルスケールにおいて、RAEは事前学習段階でVAEを一貫して上回った。さらに、高品質なデータセットにおけるファインチューニングにおいて、VAEベースのモデルは64エポックを過ぎると深刻な過学習を示したのに対し、RAEモデルは256エポックまで安定して学習を維持し、一貫して優れた性能を発揮した。すべての実験において、RAEを用いた拡散モデルはより速い収束速度と優れた生成品質を示し、大規模T2I生成の基盤として、VAEよりも単純かつ強力であることを確立した。さらに、視覚的認識と生成が共有された表現空間内で実行可能であるため、マルチモーダルモデルは生成された潜在変数に対して直接推論を行うことが可能となり、統合型モデルにおける新たな可能性が開かれた。
One-sentence Summary
Researchers from New York University propose Representation Autoencoders (RAEs) as a simpler, more scalable alternative to VAEs for text-to-image diffusion models, showing superior stability, faster convergence, and higher fidelity across model sizes by leveraging shared latent spaces for unified vision-language reasoning.
Key Contributions
- RAEs scale effectively to text-to-image generation by training decoders on diverse data including web, synthetic, and text-rendering sources, revealing that targeted data composition—not just scale—is critical for reconstructing fine text details.
- At billion-parameter scales, RAE simplifies diffusion design: dimension-dependent noise scheduling remains essential, but architectural complexities like wide diffusion heads and noise-augmented decoding offer negligible gains, enabling more efficient training.
- Across 0.5B to 9.8B parameter DiT models, RAEs outperform FLUX VAEs in pretraining speed and quality, avoid catastrophic overfitting during finetuning, and enable unified multimodal reasoning by operating in a shared semantic latent space.
Introduction
The authors leverage Representation Autoencoders (RAEs) to scale diffusion-based text-to-image generation beyond the controlled ImageNet setting, using high-dimensional semantic latents from frozen encoders like SigLIP-2. Prior work relied on VAEs that compress images into low-dimensional spaces, sacrificing semantic richness and often requiring complex architectural tweaks to scale—while still suffering from slow convergence and overfitting during finetuning. The authors show that RAEs eliminate the need for such complexity: at scale, only dimension-aware noise scheduling remains critical, while other design elements like wide diffusion heads offer diminishing returns. Their key contribution is demonstrating that RAEs consistently outperform state-of-the-art VAEs across model sizes (0.5B–9.8B parameters), converge faster, resist overfitting, and enable unified multimodal models by allowing both understanding and generation to operate in the same latent space—opening paths for latent-space reasoning and test-time scaling.
Method
The authors leverage a representation-aware encoder (RAE) framework to enable unified text-to-image (T2I) generation and visual understanding within a shared high-dimensional latent space. The overall architecture consists of two primary stages: decoder training and unified model training. In the decoder training stage, a ViT-based decoder is trained to reconstruct images from semantic tokens produced by a frozen representation encoder. The encoder, specifically SigLIP-2 So400M with a patch size of 14, processes an input image x∈R3×224×224 to generate N=16×16 tokens, each with a channel dimension d=1152. The decoder is trained using a composite objective that combines ℓ1, LPIPS, adversarial, and Gram losses to ensure high-fidelity reconstruction. The training data comprises a diverse mix of web-scale, synthetic, and text-specific images, with the composition of the dataset significantly influencing reconstruction quality, particularly for text.
As shown in the figure below, the unified model training stage integrates the trained RAE decoder with a diffusion transformer and an autoregressive model. The autoregressive model, initialized with a pretrained language model (LLM), processes text prompts and a sequence of learnable query tokens to generate conditioning signals. These signals are projected into the DiT model's space via a 2-layer MLP connector. The DiT model, based on LightningDiT, learns to model the distribution of high-dimensional semantic representations directly, without operating in a compressed VAE space. During inference, the DiT generates features conditioned on the query tokens, which are then passed to the RAE decoder for rendering into pixel space.
The training of the diffusion transformer employs a flow matching objective, where the model predicts the velocity of the diffusion process. A critical component of this setup is the dimension-dependent noise schedule, which rescales the diffusion timestep based on the effective data dimension m=N×d. This adjustment is essential for convergence in high-dimensional latent spaces, as demonstrated by significant improvements in GenEval and DPG-Bench scores when the shift is applied. The unified model also supports visual instruction tuning, where a separate 2-layer MLP projector maps visual tokens into the LLM's embedding space, enabling direct interaction between the visual and textual modalities.
A key advantage of the RAE framework is its ability to perform test-time scaling directly in the latent space. This is achieved through Latent Test-Time Scaling (TTS), where the LLM acts as a verifier for its own generations. Two verifier metrics are employed: Prompt Confidence, which measures the token-level confidence of the prompt in the generated latents, and Answer Logits, which evaluates alignment between the generated image and the prompt using a "Yes/No" query. The best-of-N selection strategy applied to these verifiers yields consistent improvements in generation quality, demonstrating that the model can assess and enhance its outputs without rendering pixels. This shared representation enables the model to verify its own outputs in the semantic space, highlighting the framework's efficiency and coherence.
Experiment
- Noise-augmented decoding provides early training gains (before ~15k steps) but becomes negligible by 120k steps, acting as transient regularization.
- DiT^DH’s wide denoising head delivers +11.2 GenEval at 0.5B scale but saturates at 2.4B+ as backbone width naturally exceeds latent dimension; standard DiT suffices for large T2I models.
- RAE (SigLIP-2) consistently outperforms FLUX VAE across DiT scales (0.5B–9.8B) and LLM scales (1.5B–7B), with 4.0× faster convergence on GenEval and 4.6× on DPG-Bench.
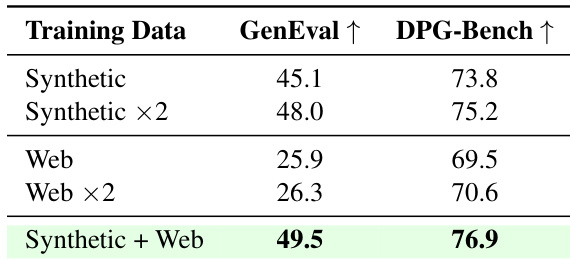
- Synthetic data + web data (49.5 GenEval) outperforms doubled synthetic (48.0), showing synergistic gains from complementary sources, not just volume.
- RAE-based models resist overfitting during finetuning: VAE loss collapses after 64 epochs, while RAE loss stabilizes; RAE maintains performance even at 512 epochs.
- RAE’s advantage holds under DiT-only finetuning and across all model sizes, with performance gap widening at larger scales (e.g., 79.4 vs 78.2 GenEval at 9.8B).
- OpenSSL ViT-L as RAE encoder slightly underperforms SigLIP-2 but still exceeds FLUX VAE, confirming RAE’s robustness to encoder choice.
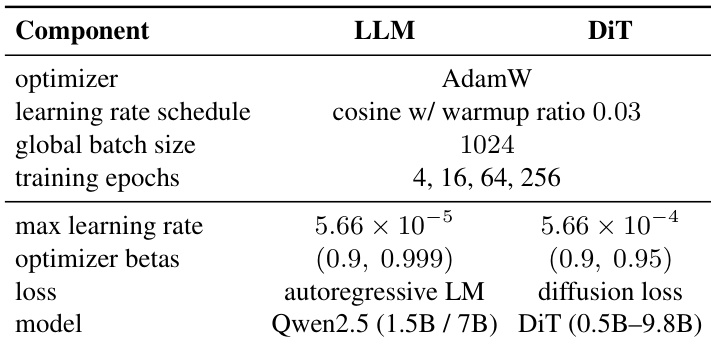
The authors use a consistent training setup for both LLM and DiT components, with the LLM trained using AdamW and a cosine learning rate schedule, while the DiT uses a diffusion loss and a higher learning rate. Training is conducted for 4, 16, 64, and 256 epochs with a global batch size of 1024, and the models include Qwen2.5 1.5B and 7B LLMs paired with DiT variants ranging from 0.5B to 9.8B parameters.
The authors compare the impact of shift augmentation in the latent space during text-to-image diffusion training. Results show that applying shift augmentation significantly improves performance, increasing GenEval from 23.6 to 49.6 and DPG-Bench from 54.8 to 76.8, indicating that shift augmentation enhances both generation quality and alignment with human preferences.

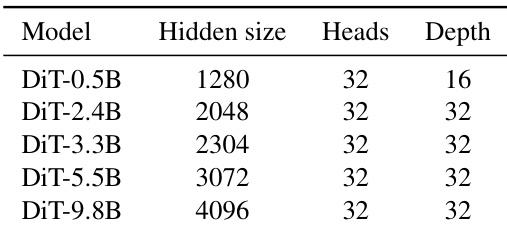
The authors compare DiT variants of different scales, showing that as the model size increases, the hidden size grows significantly while the number of heads and depth remain constant. This indicates that scaling DiT models primarily involves increasing the hidden dimension rather than altering the architecture's depth or attention heads.
Results show that combining synthetic and web data yields the highest performance, with a GenEval score of 49.5 and a DPG-Bench score of 76.9, outperforming either data type alone or doubled synthetic data. This indicates synergistic benefits from complementary data sources rather than increased volume.
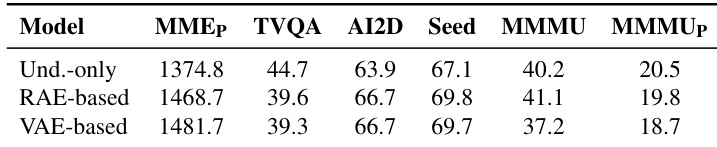
The authors compare the performance of RAE-based and VAE-based models on several evaluation metrics, showing that the RAE-based model outperforms the VAE-based model across all tasks, with the exception of TVQA where the VAE-based model achieves a slightly higher score. The RAE-based model also demonstrates greater stability during finetuning, maintaining performance over longer training periods while the VAE-based model overfits rapidly.