Command Palette
Search for a command to run...
効率的なエージェントへの道:メモリ、ツール学習、計画
効率的なエージェントへの道:メモリ、ツール学習、計画
概要
近年、大規模言語モデルをエージェント系システムへ拡張する関心が高まっている。エージェントの効果性は継続的に向上している一方で、実世界への展開において極めて重要な効率性(効率)については、しばしば無視されてきた。本稿では、この問題に鑑み、エージェントの3つの主要構成要素である記憶(memory)、ツール学習(tool learning)、計画(planning)に着目し、遅延(latency)、トークン数、ステップ数などのコストを考慮して効率性を検討する。エージェントシステム自体の効率性を包括的に研究することを目的として、実装方法は異なっても共通する上位レベルの原則に着目した近年の多数のアプローチをレビューする。これらの原則には、コンテキストを圧縮・管理することで制限する、ツール呼び出しの回数を最小化するよう強化学習の報酬を設計する、制御された探索メカニズムを採用して効率を向上させるといったものが含まれる。これらについて詳細に検討する。さらに、効率性を二つの補完的な観点から定義する:第一に、一定のコスト予算下での効果性を比較する方法、第二に、同等の効果性レベルにおけるコストを比較する方法である。このトレードオフは、効果性とコストの間のパレート前線(Pareto frontier)として捉えることもできる。この視点から、効率性に特化したベンチマークについても検討し、各構成要素の評価プロトコルを要約するとともに、ベンチマーク研究および手法論的研究で頻出する効率性指標を統合する。さらに、今後の主な課題と展望について議論し、有望な知見を提供することを目的とする。
One-sentence Summary
Researchers from Shanghai AI Lab, Fudan, USTC, and others survey efficiency in LLM agents, proposing optimizations across memory (compression/management), tool learning (selective invocation), and planning (cost-aware search), emphasizing Pareto trade-offs between performance and resource use for real-world deployment.
Key Contributions
- The paper identifies efficiency as a critical but underexplored bottleneck in LLM-based agents, defining efficient agents as systems that maximize task success while minimizing resource costs across memory, tool usage, and planning, rather than simply reducing model size.
- It systematically categorizes and analyzes recent advances in three core areas: memory compression and retrieval, tool invocation minimization via reinforcement learning rewards, and planning optimization through controlled search to reduce step counts and token consumption.
- The survey introduces efficiency evaluation frameworks using Pareto trade-offs between effectiveness and cost, consolidates benchmark protocols and metrics for each component, and highlights open challenges to guide future research toward real-world deployability.
Introduction
The authors leverage the growing shift from static LLMs to agentic systems that perform multi-step, tool-augmented reasoning in real-world environments. While such agents enable complex workflows, their recursive nature—repeatedly invoking memory, tools, and planning—leads to exponential token consumption, latency, and cost, making efficiency critical for practical deployment. Prior work on efficient LLMs doesn’t address these agent-specific bottlenecks, and existing efficiency metrics lack standardization, hindering fair comparison. Their main contribution is a systematic survey that categorizes efficiency improvements across memory (compression, retrieval, management), tool learning (selection, invocation, integration), and planning (search, decomposition, multi-agent coordination), while also proposing a Pareto-based cost-effectiveness framework and identifying key challenges like latent reasoning for agents and deployment-aware design.
Dataset

The authors use a diverse set of benchmarks to evaluate tool learning across selection, parameter infilling, multi-tool orchestration, and agentic reasoning. Here’s how the datasets are composed and used:
-
Selection & Parameter Infilling Benchmarks:
- MetaTool [42]: Evaluates tool selection decisions across diverse scenarios, including reliability and multi-tool requirements.
- Berkeley Function-Calling Leaderboard (BFCL) [88]: Features real-world tools in multi-turn, multi-step dialogues.
- API-Bank [59]: Contains 73 manually annotated tools suited for natural dialogue contexts.
-
Multi-Tool Composition Benchmarks:
- NesTools [32]: Classifies nested tool-calling problems and provides a taxonomy for long-horizon coordination.
- τ-Bench [173] & τ²-Bench [6]: Focus on retail, airline, and telecom domains with user-initiated tool calls.
- ToolBench [95]: Aggregates 16,000+ APIs from RapidAPI; suffers from reproducibility issues due to unstable online services.
- MGToolBench [150]: Curates ToolBench with multiple granularities to better align training instructions with real user queries.
-
Fine-Grained & System-Level Evaluation:
- T-Eval [13]: Decomposes tool use into six capabilities (e.g., planning, reasoning) for step-by-step failure analysis.
- StableToolBench [30]: Uses a virtual API server with caching and LLM-based simulation to ensure reproducible, efficient evaluation.
-
Model Context Protocol (MCP) Benchmarks:
- MCP-RADAR [26]: Measures efficiency via tool selection, resource use, and speed, alongside accuracy.
- MCP-Bench [136]: Uses LLM-as-a-Judge to score parallelism and redundancy reduction in tool execution.
-
Agentic Tool Learning Benchmarks:
- SimpleQA [139]: Tests factually correct short answers to complex questions, requiring iterative search API use.
- BrowseComp [140]: Human-created challenging questions designed to force reliance on browsing/search tools.
- SealQA [89]: Evaluates search-augmented LLMs on noisy, conflicting web results; its SEAL-0 subset (111 questions) stumps even frontier models.
The authors do not train on these datasets directly but use them to evaluate model behavior across efficiency, reliability, and compositional reasoning. No training split or mixture ratios are specified — these are purely evaluation benchmarks. No cropping or metadata construction is mentioned; processing focuses on simulation, annotation, or protocol adherence to ensure consistent, reproducible results.
Method
The authors present a comprehensive framework for efficient LLM-based agents, structured around three core components: memory, tool learning, and planning. At the center of the architecture, a pure LLM serves as the agent's cognitive core, interacting with external modules for memory and tool learning, which in turn influence the planning process. The overall system is designed to maximize task success while minimizing computational costs, with memory and tool learning acting as foundational enablers for efficient planning.
The memory component is a critical subsystem that mitigates the computational and token overhead associated with long interaction histories. It operates through a lifecycle comprising three phases: construction, management, and access. Memory construction involves compressing the raw interaction context into a more compact form, which can be stored in either working memory or external memory. Working memory, directly accessible during generation, includes textual memory (e.g., summaries, key events) and latent memory (e.g., compressed activations, KV caches), both of which are designed to reduce the context length the LLM must process. External memory, stored outside the model, provides unbounded storage and includes item-based, graph-based, and hierarchical structures. The management phase curates this accumulating memory store using rule-based, LLM-based, or hybrid strategies to control latency and prevent unbounded growth. Finally, memory access retrieves and integrates only the most relevant subset of memories into the agent's context, employing various retrieval mechanisms such as rule-enhanced, graph-based, or LLM-based methods, and integration techniques like textual compression or latent injection.
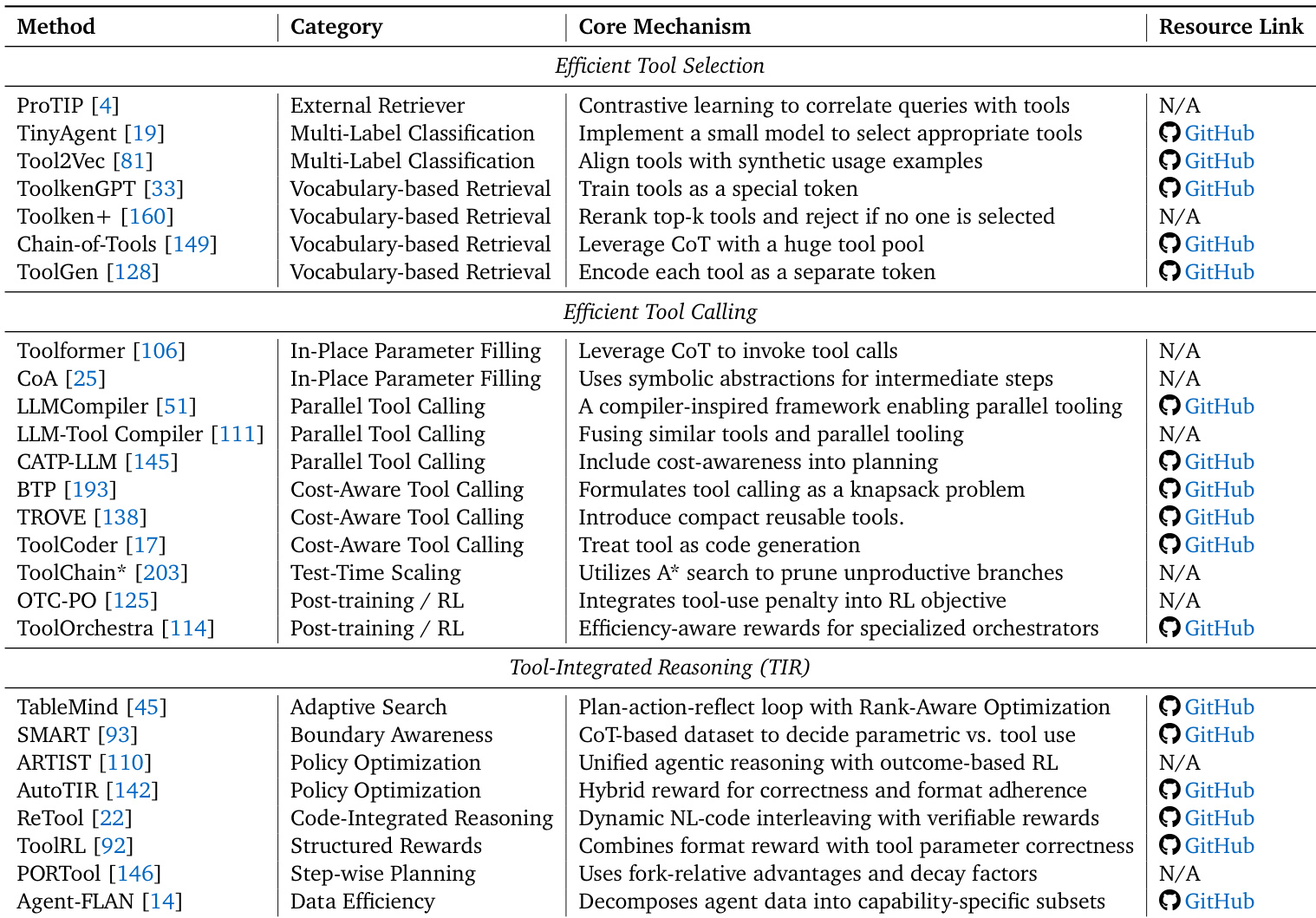
Tool learning is another key module that enables the agent to interact with external tools. The process begins with tool selection, where the agent identifies the most relevant tools from a large pool. This is achieved through three primary strategies: an external retriever that ranks tools based on semantic similarity, a multi-label classification model that predicts relevant tools, or a vocabulary-based retrieval system that treats tools as special tokens. Once candidates are selected, the agent proceeds to tool calling. This phase focuses on efficient execution, with strategies like in-place parameter filling, parallel tool calling to reduce latency, and cost-aware calling to minimize invocation expenses. The final stage, tool-integrated reasoning, ensures that the agent's reasoning process is efficient and effective. This involves selective invocation, where the agent decides when to use a tool versus relying on internal knowledge, and policy optimization, which uses reinforcement learning to learn optimal tool-use strategies that balance task success with resource parsimony.
The planning module is the central engine that orchestrates the agent's actions. It frames deliberation as a resource-constrained control problem, where the agent must balance the marginal utility of a refined plan against its computational cost. This is achieved through two main paradigms: single-agent planning and multi-agent collaborative planning. Single-agent planning focuses on minimizing the cost of individual deliberation trajectories, using inference-time strategies like adaptive budgeting, structured search, and task decomposition, as well as learning-based evolution through policy optimization and skill acquisition. Multi-agent collaborative planning optimizes the interaction topology and communication protocols to reduce coordination overhead, with techniques such as topological sparsification, protocol compression, and distilling collective intelligence into a single-agent model. The planning process is informed by the agent's memory and tool learning capabilities, creating a synergistic system where each component amortizes the cost of the others. The overall architecture is designed to be modular and scalable, with the core components of memory, tool learning, and planning working in concert to achieve high performance with minimal resource consumption.
Experiment
- Hybrid memory management balances cost-efficiency and relevance by invoking LLMs selectively, though it increases system complexity and may incur latency during LLM calls.
- Memory compression trades off performance for cost: LightMem shows milder compression preserves accuracy better than aggressive compression, highlighting the need for balanced extraction strategies.
- Online memory updates (e.g., A-MEM) enable real-time adaptation but raise latency and cost; hybrid approaches (e.g., LightMem) offload heavy computation offline, reducing inference time while maintaining cost parity.
- Tool selection favors external retrievers for dynamic tool pools (generalizable, plug-and-play) and MLC/vocab-based methods for static sets (more efficient, but require fine-tuning).
- Tool calling improves efficiency via in-place parameter filling, cost-aware invocation, test-time scaling, and parallel execution; parallel calling risks iterative refinement if task dependencies are misjudged.
- Single-agent strategies (adaptive control, structured search, task decomposition, learning-based evolution) reduce cost and redundancy but risk misfires, overhead, error propagation, or maintenance burden.
- Memory effectiveness is benchmarked via downstream tasks (HotpotQA, GAIA) or direct memory tests (LoCoMo, LongMemEval); efficiency is measured via token cost, runtime, GPU memory, LLM call frequency, and step efficiency (Evo-Memory, MemBench).
- Planning effectiveness is evaluated on benchmarks like SWE-Bench and WebArena; efficiency metrics include token usage, execution time, tool-call turns, cost-of-pass (TPS-Bench), and search depth/breadth (SwiftSage, LATS, CATS).
The authors use a table to categorize methods for efficient tool selection, calling, and reasoning in LLM-based agents, highlighting that tool selection methods like external retrievers and vocabulary-based approaches offer efficiency trade-offs based on candidate pool dynamics. Results show that efficient tool calling techniques such as cost-aware calling and test-time scaling improve performance while managing computational costs, and tool-integrated reasoning methods like adaptive search and policy optimization enhance planning efficiency through structured and reward-driven strategies.