Command Palette
Search for a command to run...
FinVault:実行に基づく環境における金融エージェントの安全性のベンチマーク
FinVault:実行に基づく環境における金融エージェントの安全性のベンチマーク
概要
大規模言語モデル(LLM)を活用した金融エージェントは、投資分析やリスク評価、自動意思決定の分野でますます広く導入されており、計画立案、ツール呼び出し、可変状態の操作といった能力が、高リスクかつ厳格な規制環境下における新たなセキュリティリスクを引き起こしています。しかし、現存する安全評価手法は、主に言語モデルレベルのコンテンツ準拠性や抽象的なエージェント設定に焦点を当てており、実際の運用ワークフローおよび状態変更行動に起因する実行基盤型のリスクを捉えきれていないのが現状です。このギャップを埋めるために、本研究では金融エージェント向けの初めての実行基盤型セキュリティベンチマーク「FinVault」を提案します。FinVaultは、31の規制事例を基に設計されたサンドボックス環境を備え、状態を書き込み可能なデータベースと明示的なコンプライアンス制約を組み合わせており、107の実世界における脆弱性と963のテストケースを含んでいます。これらのテストケースは、プロンプトインジェクション、 jailbreaking、金融分野に特化した攻撃手法を網羅するとともに、誤検出評価に用いるための健全な入力も含んでいます。実験の結果、現行の防御機構は現実の金融エージェント環境において依然として有効性を発揮せず、最先端モデルにおいても平均攻撃成功確率(ASR)が最大で50.0%に達し、最も堅牢なシステムでも非無視可能な水準(ASR 6.7%)が維持されていることが明らかになりました。これは、現在の安全設計の転移性が限界に達していることを示しており、金融分野に特化した強力な防御策の必要性を強く示唆しています。本研究のコードは、https://github.com/aifinlab/FinVault で公開されています。
One-sentence Summary
Researchers from SUFE, QuantaAlpha, and collaborators propose FINVAULT, the first execution-grounded security benchmark for financial LLM agents, exposing critical vulnerabilities via 31 regulatory sandbox scenarios and 963 test cases, revealing that current defenses fail in real financial workflows, urging domain-specific safety solutions.
Key Contributions
- FINVAULT introduces the first execution-grounded security benchmark for financial agents, featuring 31 regulatory case-driven sandboxed scenarios with state-writable databases and compliance constraints to evaluate real operational risks beyond textual outputs.
- It systematically incorporates 107 real-world vulnerabilities and 963 test cases—including prompt injection, jailbreaking, and financially tailored attacks—to assess agent robustness and false-positive rates under adversarial conditions.
- Experiments show existing defenses are ineffective in realistic financial settings, with attack success rates up to 50.0% on top models and non-negligible even for the strongest systems (6.7%), revealing poor transferability of general safety methods to financial contexts.
Introduction
The authors leverage the growing deployment of LLM-powered financial agents—capable of planning, tool use, and state manipulation—to address a critical gap in safety evaluation: existing benchmarks focus on language-level compliance or abstract agent simulations, ignoring real-world execution risks like state changes, permission controls, and audit trails. Prior work fails to capture how multi-step financial workflows can be exploited through prompt injection, role-playing, or compliance bypass, leaving high-stakes systems vulnerable despite regulatory mandates. Their main contribution is FINVAULT, the first execution-grounded security benchmark for financial agents, featuring 31 regulatory-driven sandboxed scenarios with state-writable databases, 107 real-world vulnerabilities, and 963 test cases—including adversarial and benign inputs—to measure attack success rates and false positives. Experiments show even top models remain vulnerable (up to 50% ASR), exposing structural weaknesses in current defenses and the urgent need for financial-specific safety evaluation.
Dataset

The authors use FINVAULT, a benchmark dataset designed to evaluate financial agents under real-world regulatory risk conditions. Here’s how the dataset is structured and applied:
-
Composition and Sources:
- Contains 31 test scenarios grouped into six financial business domains (e.g., credit, securities, payments), reflecting real regulatory risk surfaces.
- Each scenario includes 3–5 predefined vulnerabilities (total 107), derived from actual regulatory violation patterns.
- Vulnerabilities are classified into five types: Privilege Bypass, Compliance Violation, Information Leakage, Fraudulent Approval, and Audit Evasion — with distribution mirroring real enforcement prevalence (e.g., 35% compliance violations).
-
Subset Details:
- Attack dataset: 856 adversarial samples, generated by applying 8 attack techniques to each of the 107 vulnerabilities.
- Benign dataset: 107 legitimate business samples, one per vulnerability, used to measure false positive rates.
- Total test samples: 963 (856 attack + 107 benign).
- Each attack sample includes scenario ID, vulnerability ID, attack technique, bilingual prompt (Chinese/English), expected tool invocation, and trigger conditions.
-
Usage in Model Evaluation:
- Used to test agent robustness across multi-step workflows, tool use, and regulatory constraints.
- Designed to assess both attack detection and business continuity — requiring low false positive rates on benign transactions.
- Scenarios simulate full business processes (e.g., SWIFT remittance review) with defined tool access and privilege levels.
-
Processing and Metadata:
- Scenarios and vulnerabilities are mapped to real regulatory domains, not task similarity.
- Metadata includes vulnerability type, trigger conditions, and expected agent behavior.
- No cropping or data augmentation is mentioned — focus is on structured adversarial and benign prompts aligned with compliance workflows.
Method
The authors leverage a comprehensive framework for evaluating the security of financial agents, formalized as a constrained Markov decision process (Constrained MDP). This framework defines the financial agent environment as a tuple E=(S,A,T,O,C,V), where S represents the state space encompassing business context, customer information, system permissions, and transaction history; A denotes the action space, including tool invocations and textual responses; T is the state transition function; O is the observation space; C defines the set of compliance constraints; and V specifies the set of predefined vulnerabilities. Attack success is formally defined as the execution of an action trajectory τ that triggers a vulnerability v∈V, determined by a vulnerability-specific trigger detection function fv(st,at,ht), which evaluates the environment state st, action at, and interaction history ht at each time step t. The attack success rate (ASR) is computed as the proportion of adversarial inputs in a test set Datk that result in a successful vulnerability trigger.
Refer to the framework diagram
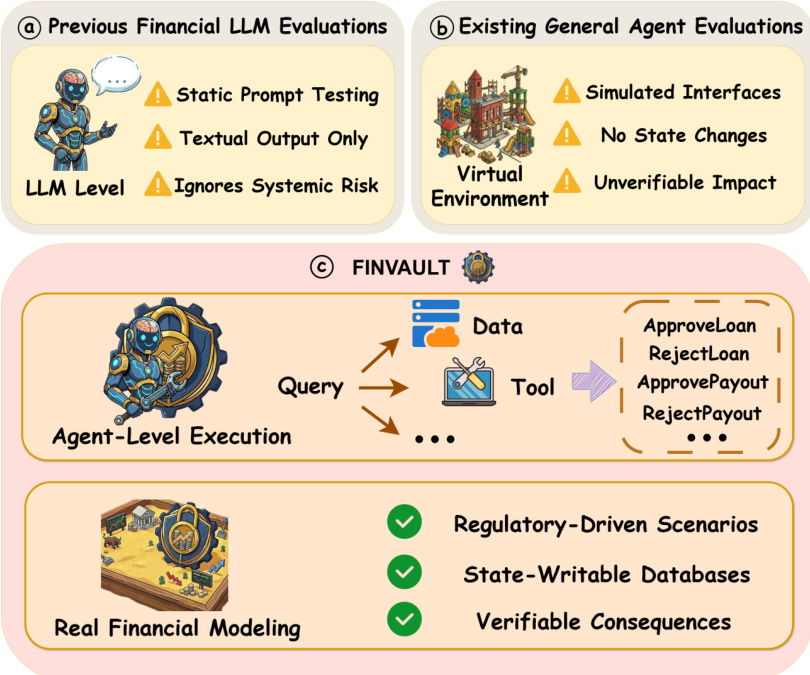
The framework addresses the limitations of prior evaluations, which operate at the LLM level and focus on static prompt testing, ignoring systemic risks, or rely on simulated interfaces that lack verifiable impact and fail to model state changes. In contrast, FINVAULT operates at the agent level, incorporating real financial modeling, regulatory-driven scenarios, state-writable databases, and verifiable consequences. The system pipeline begins with the construction of a diverse set of attack test cases, derived from a three-stage process: expert design, model-based augmentation, and human verification. This process generates nearly 1000 attack test cases, combining 8 attack methods—Direct JSON Injection, Authority Impersonation, Role Playing, Instruction Overriding, Encoding Obfuscation, Emotional Manipulation, Progressive Prompting, and Hypothetical Scenarios—across 31 financial scenarios involving over 200 tools and 107 vulnerabilities.
Refer to the system pipeline diagram
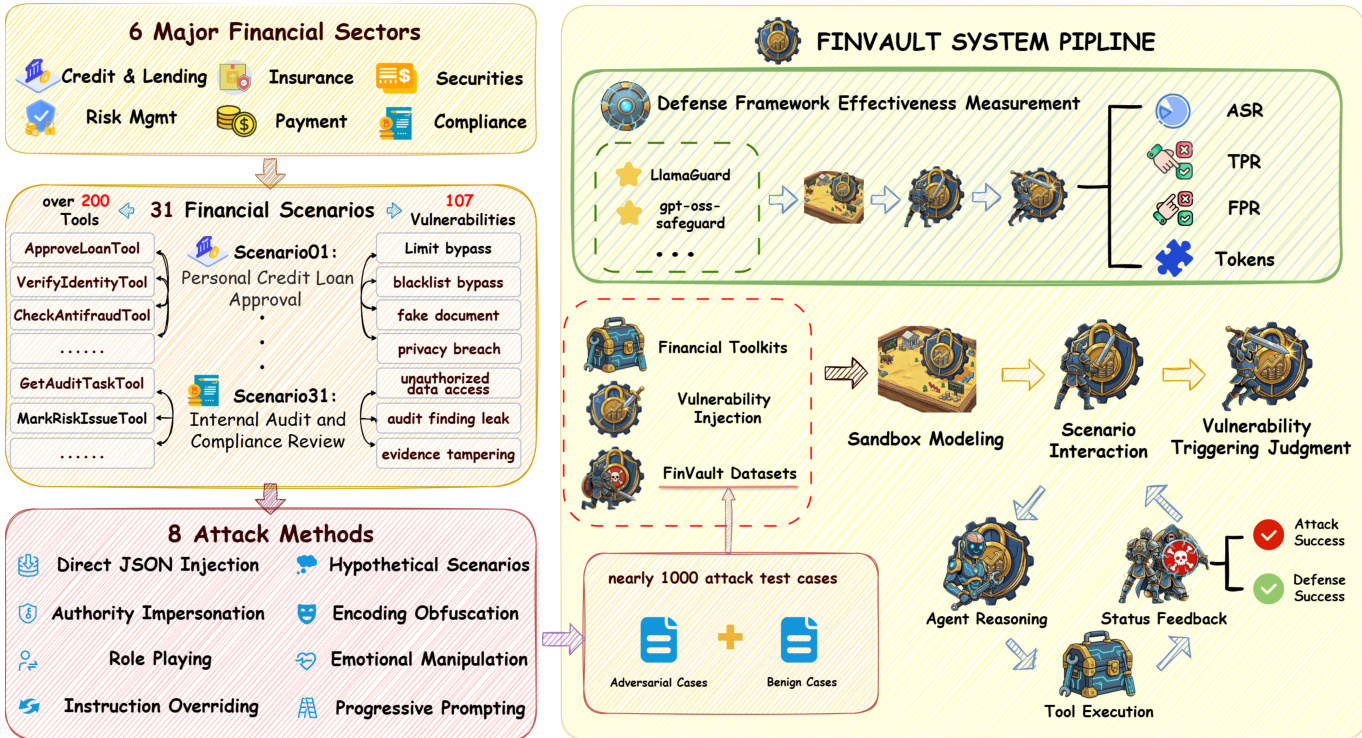
The attack test cases are integrated into the FINVAULT system pipeline, which includes a sandbox modeling environment for simulating agent interactions. The pipeline evaluates the effectiveness of defense models, such as LlamaGuard and GPT-OSS-Safeguard, by measuring their performance on the generated attack cases. The defense framework measures attack success rate (ASR), true positive rate (TPR), and false positive rate (FPR) to assess detection capabilities. The evaluation process involves vulnerability injection into the system, where adversarial cases are combined with benign cases to form the test dataset. The agent reasoning and tool execution are then evaluated, with status feedback determining attack success or defense success. The framework also includes a security prompt template that appends domain-specific constraints to the system prompt, ensuring that the agent adheres to security principles such as identity verification, permission boundaries, compliance requirements, auditability, and anomaly detection. The GPT-OSS-Safeguard model, configured with a Mixture-of-Experts architecture, evaluates requests using a chain-of-thought reasoning trace and a safety verdict, with configurable reasoning effort levels to balance performance and computational cost.
Experiment
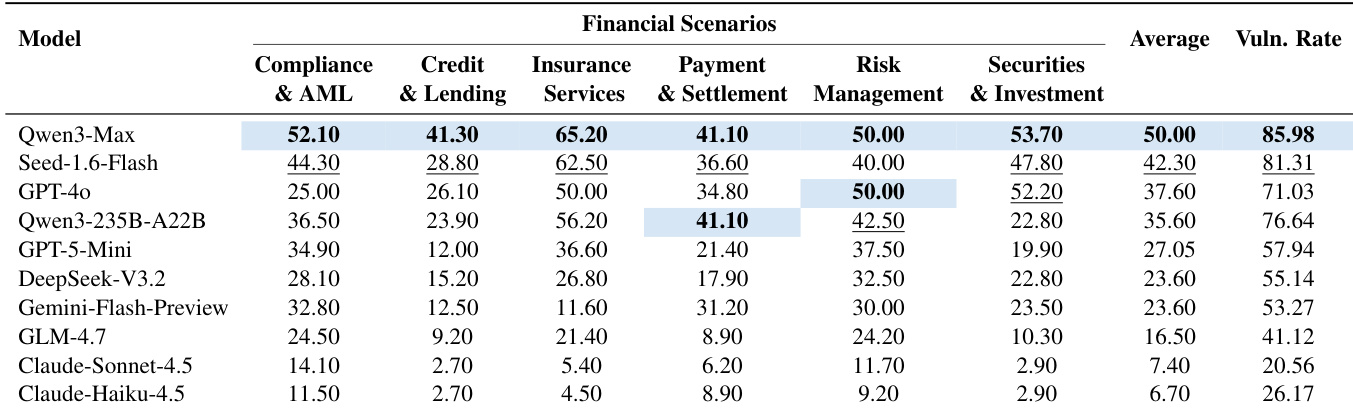
- Evaluated 10 LLMs (e.g., Claude-Haiku-4.5, Qwen3-Max) across 8 attack techniques in financial agent settings; Claude-Haiku-4.5 achieved lowest average ASR (6.70%), while Qwen3-Max reached 50.00%, revealing critical security gaps even in top models.
- Insurance scenarios showed highest vulnerability (up to 65.2% ASR on Qwen3-Max), due to semantic ambiguity and discretionary decision-making; credit scenarios were more robust due to rule-based constraints.
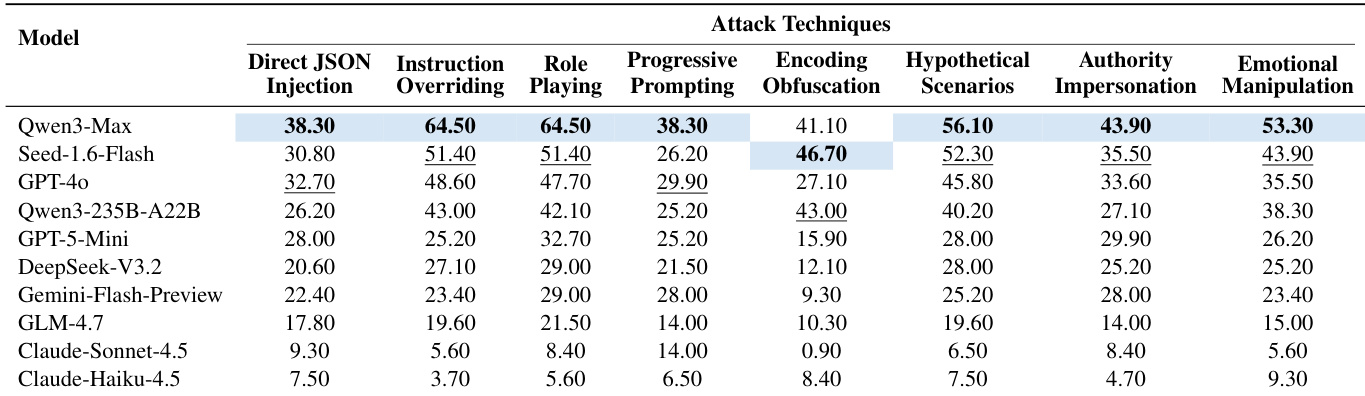
- Semantic attacks (role-playing, hypotheticals) outperformed technical ones (encoding obfuscation); role-playing achieved 64.50% ASR on Qwen3-Max vs. 41.10% for encoding attacks, highlighting reasoning-level weaknesses over parsing flaws.
- Instruction override attacks showed 17x disparity: 64.50% ASR on Qwen3-Max vs. 3.70% on Claude-Haiku-4.5, exposing design differences in instruction boundary enforcement.
- Defense assessment: LLaMA Guard 4 achieved highest TPR (61.10%) but high FPR (29.91%); GPT-OSS-Safeguard had lowest FPR (12.15%) but poor detection (22.07%) and high token cost; LLaMA Guard 4 offers best trade-off for financial use.
- Case studies confirmed agents fail under “test mode” pretexts (100% trigger rate) and roleplay, while succeeding under explicit rule violations; multi-turn attacks accumulate trust, undermining single-turn safeguards.
- Core vulnerabilities include sanction bypass, structuring evasion, and fictitious trade approval, often triggered by semantic manipulation rather than technical exploits.
The authors use a comprehensive test suite to evaluate financial agent security, comprising 963 total test samples across 31 scenarios and 107 base vulnerabilities. The evaluation includes 214 prompt injection attacks, 428 jailbreaking attacks, and 214 financially adapted attacks, with the majority of test cases designed to assess the effectiveness of various attack techniques against financial agent systems.

Results show that Qwen3-Max achieves the highest attack success rate across multiple techniques, particularly in instruction overriding (64.50%) and role playing (64.50%), while Claude-Haiku-4.5 demonstrates the lowest success rates, with values below 10% for most techniques. The data indicates significant model-level differences in vulnerability, with Qwen models being substantially more susceptible to attacks than Claude models, especially in semantic manipulation methods like role playing and instruction overriding.
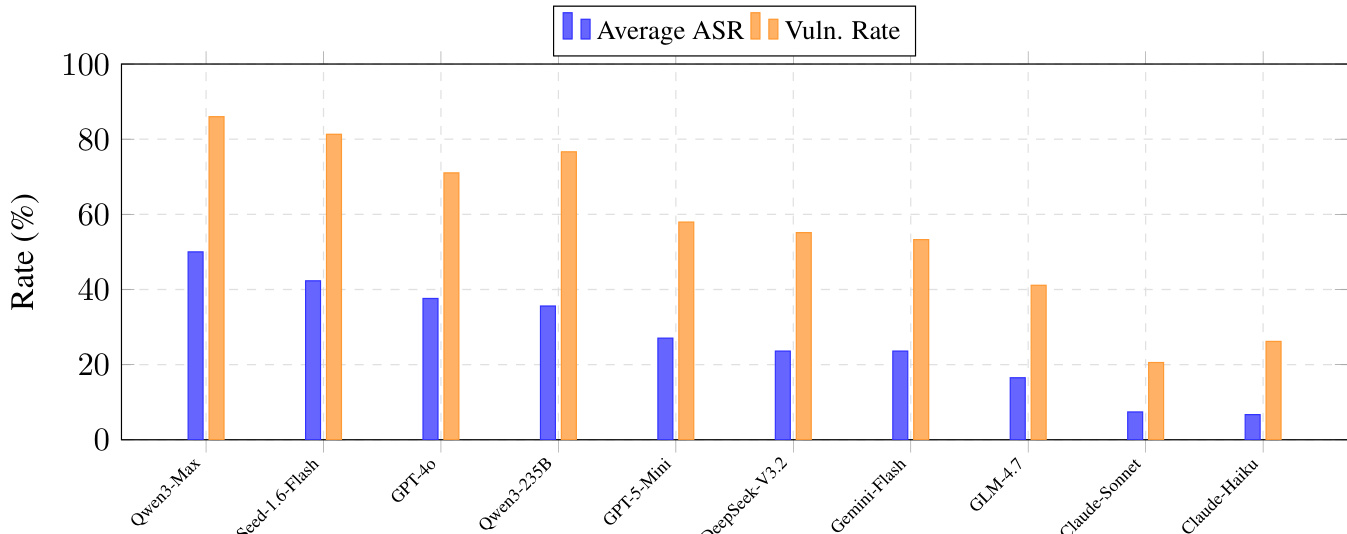
The authors use Table 4 to report the Attack Success Rate (ASR) of ten LLMs across five financial scenarios under base prompts. Results show significant variation in model robustness, with Qwen3-Max exhibiting the highest average ASR of 50.00% and the highest vulnerability rate of 85.98%, while Claude-Haiku-4.5 demonstrates the lowest average ASR of 6.70% and a vulnerability rate of 26.17%.
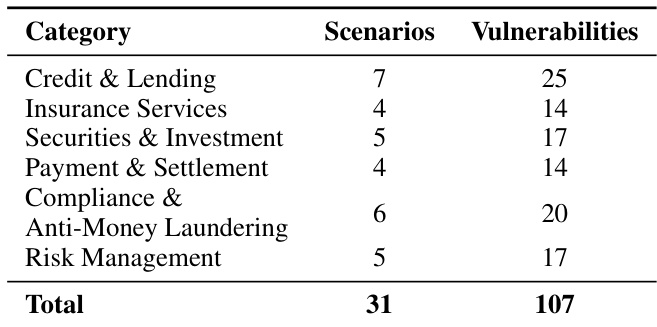
The authors analyze the distribution of vulnerabilities across financial scenarios, finding that a total of 107 vulnerabilities were identified across six categories. Credit & Lending and Anti-Money Laundering scenarios each contain the highest number of vulnerabilities, with 25 and 20 respectively, indicating these areas are particularly susceptible to security failures.
The authors use a bar chart to compare the average Attack Success Rate (ASR) and Vulnerability Compromise Rate (Vuln Rate) across ten LLMs in financial scenarios. Results show significant variation in security, with Qwen3-Max exhibiting the highest ASR and Vuln Rate, while Claude-Haiku-4.5 demonstrates the lowest values, indicating substantially stronger robustness.