Command Palette
Search for a command to run...
MHLA:トークンレベル多頭による線形アテンションの表現力の回復
MHLA:トークンレベル多頭による線形アテンションの表現力の回復
Kewei Zhang Ye Huang Yufan Deng Jincheng Yu Junsong Chen Huan Ling Enze Xie Daquan Zhou
概要
Transformerアーキテクチャは多くの分野で優位を占めているが、その二次的な自己注意(self-attention)計算量は大規模な応用における活用を制限している。線形注意(linear attention)は効率的な代替手段として注目されているが、その直接的な適用は性能の低下を引き起こすことが多く、既存の修正手法はしばしば追加モジュール(例:ディープワイズ可分畳み込み)を導入することで計算負荷を再び増加させ、元々の効率性の目的を損なう。本研究では、こうした手法における根本的な失敗要因を「グローバルな文脈の崩壊(global context collapse)」と特定する。すなわち、モデルが表現の多様性を失ってしまう現象である。これを解決するために、本研究ではトークン次元に沿ってヘッドを分割し、各ヘッド内で注意を計算することで表現の多様性を保持する「マルチヘッド線形注意(Multi-Head Linear Attention, MHLA)」を提案する。理論的にMHLAが線形の計算量を維持しつつ、softmax注意の表現力の大部分を回復できることを証明し、複数の分野における有効性を実証した。具体的には、ImageNet分類で3.6%の性能向上、自然言語処理(NLP)で6.3%の向上、画像生成で12.6%の改善、動画生成では41%の性能向上を、計算時間の制約が同一の条件下で達成した。
One-sentence Summary
The authors from Peking University and NVIDIA propose Multi-Head Linear Attention (MHLA), a linear-complexity attention mechanism that prevents global context collapse by preserving representational diversity through token-wise head division, outperforming softmax attention in image classification, NLP, image generation, and video generation while maintaining efficiency.
Key Contributions
-
Linear attention mechanisms offer a scalable alternative to quadratic self-attention in Transformers but often suffer from performance degradation due to global context collapse, where the model loses representational diversity by compressing all tokens into a single shared key-value summary, limiting query-specific context retrieval.
-
The proposed Multi-Head Linear Attention (MHLA) addresses this by partitioning tokens into non-overlapping heads along the token dimension, enabling query-dependent context selection through local key-value summaries and a query-conditioned mixing mechanism, while maintaining O(N) complexity without additional modules.
-
MHLA achieves state-of-the-art results across multiple domains: a 3.6% accuracy gain on ImageNet, 6.3% improvement on NLP, 12.6% boost in image generation, and a 41% enhancement in video generation, all under the same time complexity as baseline linear attention.
Introduction
The Transformer architecture's dominance in vision, language, and generative modeling is limited by its quadratic self-attention complexity, which hinders scalability to long sequences and high-resolution tasks. Linear attention offers a promising alternative with linear complexity, but prior approaches often degrade in performance due to a fundamental issue: global context collapse, where all tokens are compressed into a single shared key-value summary, reducing representational diversity and capping the rank of attention matrices. This leads to uniform attention distributions and poor query-specific context selection, especially as sequence length grows. Existing fixes rely on auxiliary modules like depthwise convolutions or gating mechanisms, which reintroduce computational overhead and fail to fully restore expressivity.
The authors propose Multi-Head Linear Attention (MHLA), a novel formulation that restores query-dependent diversity by partitioning tokens into non-overlapping heads along the token dimension, computing local key-value summaries, and enabling query-conditioned mixing over these summaries. This design preserves linear O(N) complexity while significantly increasing the rank of attention matrices, effectively recovering much of the expressive power of softmax attention. MHLA requires only standard GEMM operations, ensuring compatibility with streaming and stateful execution. Experiments show consistent gains across domains: 3.6% higher ImageNet accuracy, 6.3% improvement on NLP, 12.6% boost in image generation, and a 41% enhancement in video generation—without additional computational cost.
Method
The authors leverage a multi-head linear attention mechanism, termed Multi-Head Linear Attention (MHLA), to address the representational limitations of standard linear attention while preserving linear-time complexity. The framework begins by partitioning the input token sequence into M non-overlapping blocks, which are processed in parallel. For each block b, a local key-value summary Sb=∑j∈bKjVj⊤ and a normalizer zb=∑j∈bKj are computed, where Q=ϕ(Q) and K=ϕ(K) represent the feature-mapped queries and keys. This blockwise computation allows for efficient, parallel processing of the sequence.
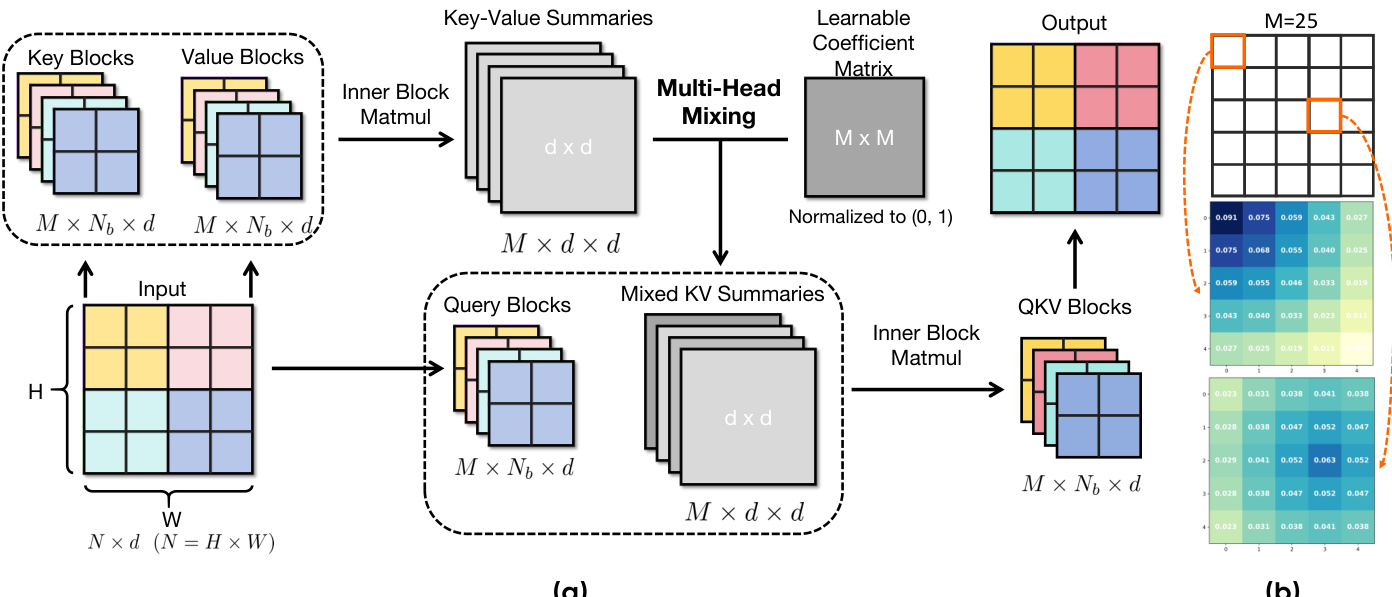
To restore query-conditioned selectivity, MHLA introduces a learnable coefficient matrix Mc∈RM×M, which governs a "Multi-Head Mixing" process. Each row mi of this matrix represents the learnable, nonnegative mixing coefficients for query block i, determining how it combines the M local key-value summaries into a query-specific mixed summary Si=∑b=1Mmi,bSb. This mechanism enables each query block to adaptively reweight the contributions of all other blocks, effectively creating a query-dependent global context. The output for a query vector q from block i is then computed as o=q⊤ziq⊤Si, where zi=∑b=1Mmi,bzb is the corresponding mixed normalizer.

The initialization of the coefficient matrix Mc is designed to favor locality, with initial coefficients mi,j(0)∝1−dist(i,j)/maxk(dist(i,k)), which promotes stable and faster convergence. This locality-biased initialization is visualized in the figure, where the coefficients are reshaped into a 2D grid to illustrate the spatial relationship between blocks. The final output is generated by performing an inner block matrix multiplication between the query blocks and the mixed key-value summaries, resulting in a final output tensor of size M×Nb×d. This two-stage process—block-level selection via the mixing coefficients followed by intra-block reweighting via the kernel inner product—reintroduces query-conditioned selectivity and per-token weighting, which are lost in global linear attention. The overall complexity of MHLA remains linear in the sequence length N, as the dominant operations are blockwise summary computation and linear combinations of M matrices of size d×d.
Experiment
- Main experiments validate that MHLA mitigates global context collapse in linear attention by preserving query-conditioned token-level diversity while maintaining linear-time complexity.
- On ImageNet-1K, MHLA achieves state-of-the-art accuracy in image classification across DeiT and VLT models, surpassing baselines with minimal parameter overhead.
- In class-to-image generation, MHLA matches or exceeds self-attention performance on DiT and DiG models, achieving up to 2.1× faster inference than FlashAttention at 512 resolution while improving FID scores.
- In video generation with 31,500-token sequences, MHLA outperforms vanilla linear attention and matches FlashAttention performance with 2.1× speedup, demonstrating robustness in ultra-long contexts.
- In natural language processing, MHLA achieves competitive perplexity and zero-shot accuracy on commonsense reasoning and MMLU, and leads in LongBench for long-context tasks, especially in Mult-Doc QA and summarization.
- Ablation studies confirm that MHLA’s locality-biased initialization and learnable mixing coefficients enhance performance, and that M ≤ √N ensures optimal efficiency and scalability.
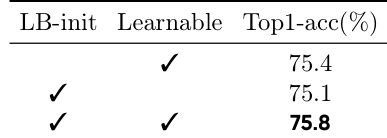
The authors evaluate the impact of their initialization strategy and learnable parameters in Multi-Head Mixing by comparing different variants on DeiT-T. Results show that using locality-biased initialization alone achieves strong performance, and adding learnable coefficients further improves accuracy, with the best performance achieved when both are used.
The authors compare MHLA with self-attention in DiT-XL/2 for class-to-image generation, showing that MHLA achieves lower FID and sFID scores while maintaining competitive IS and precision. When classifier-free guidance is applied, MHLA still performs comparably to self-attention, demonstrating its effectiveness in high-resolution image generation.

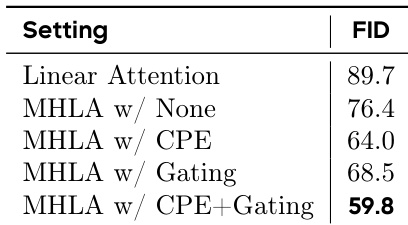
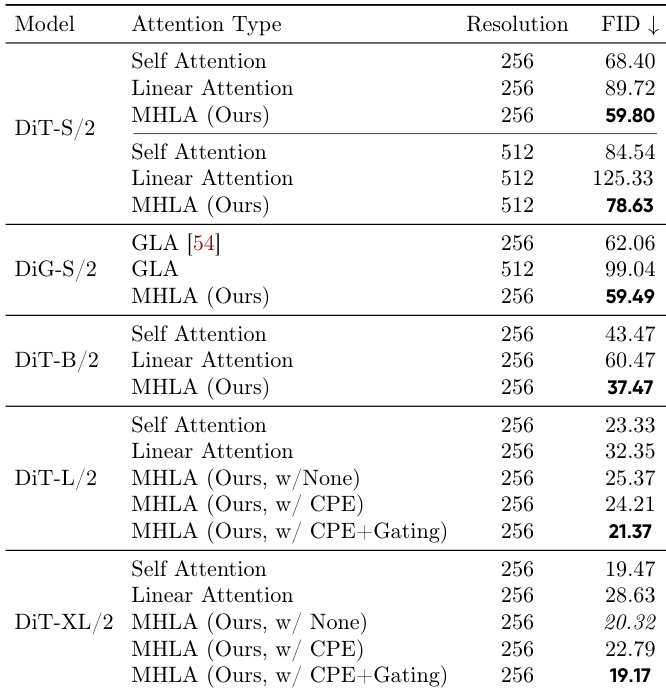
The authors evaluate the impact of additional modules on MHLA for class-to-image generation, showing that combining CPE and gating reduces the FID score to 59.8, outperforming all other variants. This indicates that the full MHLA configuration with both modules achieves the best generation quality.
The authors evaluate the proposed MHLA method on image generation tasks using DiT and DiG models, comparing it against self-attention and linear attention baselines. Results show that MHLA achieves the best FID scores across all model sizes and resolutions, consistently outperforming linear attention while maintaining high throughput, and matches or exceeds self-attention performance without relying on extra modules like CPE at larger scales.
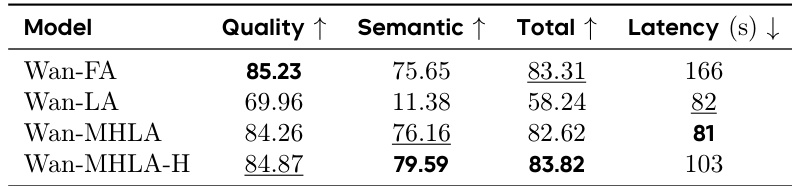
The authors evaluate MHLA in video generation by fine-tuning a pretrained Wan2.1-1.3B model, replacing its FlashAttention with MHLA. Results show that MHLA achieves substantially stronger performance than vanilla linear attention while maintaining the same latency, recovering performance comparable to the original model and delivering a 2.1× inference speedup.