Command Palette
Search for a command to run...
事後学習における教師あり微調整と強化学習の非分離性について
事後学習における教師あり微調整と強化学習の非分離性について
Xueyan Niu Bo Bai Wei Han Weixi Zhang
概要
大規模言語モデルの後学習において、教師あり微調整(SFT)と強化学習(RL)を繰り返し適用する手法が一般的に用いられている。これらの手法は異なる目的を持つ:SFTはモデル出力と専門家回答との間の交差エントロピー損失を最小化するのに対し、RLは人間の好みやルールベースの検証器から得られる報酬信号を最大化する。現代の推論モデルでは、SFTとRLの交互学習が広く採用されている。しかし、これらを分離可能かどうかについての理論的説明は存在しない。本研究では、いずれの順序でも分離が不可能であることを証明した。具体的には、(1) SFT→RLの順序では、SFTの最適性下でRLがSFTの損失を増加させ、(2) RL→SFTの順序では、SFTがRLが達成する報酬を低下させる。Qwen3-0.6Bを用いた実験により、予測された性能の低下が確認され、後学習段階においてSFTとRLを分離することは、従来の性能を損なうことなく行えないことが裏付けられた。
One-sentence Summary
The authors from Huawei's Central Research Institute propose that supervised fine-tuning (SFT) and reinforcement learning (RL) in post-training of large language models cannot be decoupled without performance degradation, as SFT undermines RL rewards and RL worsens SFT loss, with experiments on Qwen3-0.6B confirming this fundamental trade-off in alternating training pipelines.
Key Contributions
-
Post-training of large language models typically alternates supervised fine-tuning (SFT) and reinforcement learning (RL), but this work proves theoretically that these stages cannot be decoupled: SFT minimizes cross-entropy loss on expert responses, while RL maximizes reward signals, leading to conflicting objectives that prevent independent optimization.
-
Theoretical analysis shows that in the SFT-then-RL pipeline, RL training increases the SFT loss even when SFT is optimal, and in the RL-then-SFT pipeline, subsequent SFT reduces the reward achieved by the previously optimized RL model, demonstrating a fundamental incompatibility between the two stages.
-
Experiments on Qwen3-0.6B confirm both theoretical predictions: RL degrades SFT performance (increased cross-entropy loss), and SFT following RL leads to reward degradation, validating that SFT and RL must be treated as an integrated optimization process rather than separate steps.
Introduction
The authors investigate the interplay between supervised fine-tuning (SFT) and reinforcement learning (RL) in post-training large language models, a common practice in modern reasoning models like DeepSeek-R1 and Qwen3. While SFT aligns model outputs with expert responses by minimizing cross-entropy loss, RL optimizes for human preferences or rule-based rewards, often leading to conflicting objectives. Prior work has shown inconsistent empirical results, with some observing performance gains from alternating SFT and RL, while others report catastrophic forgetting or limited synergy. The key limitation is the lack of theoretical understanding of whether these stages can be decoupled without performance degradation. The authors prove that decoupling is fundamentally impossible: performing SFT after RL increases the SFT loss, and performing RL after SFT reduces the reward achieved. Experiments on Qwen3-0.6B validate these findings, showing that interleaving SFT and RL is necessary to preserve prior performance, highlighting a critical constraint in current LLM post-training pipelines.
Method
The authors investigate the interaction between supervised fine-tuning (SFT) and reinforcement learning (RL) in post-training pipelines for language models, focusing on the non-decoupling of these stages. The overall framework begins with a pretrained base model, which undergoes either SFT or RL as a post-training step, followed by the other, before reaching test-time computation. The two primary sequential strategies are SFT-then-RL and RL-then-SFT, which are analyzed to determine if the stages can be treated as independent optimizations.
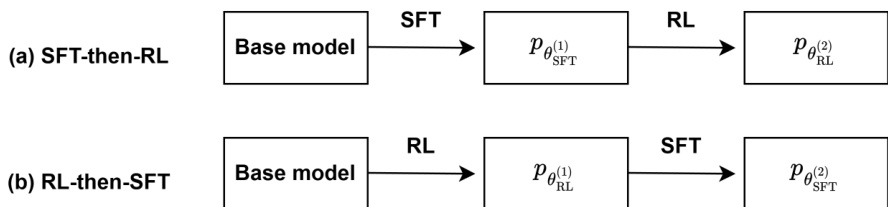
In the SFT stage, the pretrained model pθ is adapted to task-specific knowledge using labeled data DSFT. The objective is to minimize the negative log-likelihood, which is equivalent to the cross-entropy loss for next-token prediction. This is formalized as LSFT(pθ)=−∑(x,y)∈DSFT∑j=1∣y∣logpθ(yj∣x,y<j). The resulting model pθSFT is optimized to generate outputs y given a prompt x, and this process is effective for in-distribution tasks.
The RL stage, typically used for aligning models with human preferences, treats the language model as a policy pθ. It aims to maximize the expected reward rG(x,y) over the output distribution. When the ground truth reward is not available, a proxy reward model r(⋅,⋅) is trained on preference data DRL, which consists of prompt-response pairs with positive and negative responses. The policy is updated using a policy gradient objective, such as PPO, which maximizes the expected reward while regularizing against drift from a reference model πref. The objective is IRL(θ)=Ex∼pDRL,y∼pθ(⋅∣x)[r(x,y)]−βEx∼pDRL[DKL(pθ(⋅∣x)∥πref(⋅∣x))]. The closed-form solution for the updated policy is pθRL(2)(y∣x)=Zβ(x)1πref(y∣x)exp(r(x,y)/β).
The analysis reveals that the two stages are fundamentally coupled. In the SFT-then-RL pipeline, even if the SFT stage has converged, the subsequent RL phase inevitably degrades the SFT loss. This is because the RL update, which maximizes reward, shifts the model's output distribution away from the SFT-optimized distribution, leading to a non-trivial increase in the SFT loss. Conversely, in the RL-then-SFT pipeline, the SFT stage, which aims to fit the SFT data, can create a persistent performance gap that decreases the reward achieved by the RL stage. This is shown by the fact that any SFT update from an RL policy cannot increase the expected reward by more than a constant controlled by the distribution shift, and under stronger assumptions, it can lead to a measurable reward deficit. Therefore, the authors conclude that SFT and RL cannot be decoupled and should be treated as a single joint optimization problem.
Experiment
- SFT-then-RL experiment: Fine-tuning the Qwen3-0.6B model on a CoLA-style SFT dataset followed by GRPO-based RL leads to a sharp increase in cross-entropy loss, exceeding the base model’s loss, validating Theorem 3.1 on non-decoupling.
- RL-then-SFT experiment: Applying SFT after RL on the same dataset causes a significant drop in mean@1 reward from 0.385 (≈69.5% accuracy) to 0.343 (≈67.2% accuracy) under robust evaluation, confirming Theorem 4.1 and demonstrating performance degradation due to objective mismatch.
- Both pipelines show performance deterioration in the second stage, empirically validating the inherent coupling between SFT and RL, with results consistent across both orders of training.