Command Palette
Search for a command to run...
マップを用いた思考:強化型並列マップ拡張エージェントによる地理局所化
マップを用いた思考:強化型並列マップ拡張エージェントによる地理局所化
Yuxiang Ji Yong Wang Ziyu Ma Yiming Hu Hailang Huang Xuecai Hu Guanhua Chen Liaoni Wu Xiangxiang Chu
概要
画像ジオローカライゼーションのタスクは、画像に含まれる視覚的手がかりを用いて、地球上のどこで撮影されたかを予測することを目的としています。従来の大規模な視覚言語モデル(LVLM)アプローチは、世界知識の活用、連鎖的思考(chain-of-thought)推論、エージェント機能を活用していますが、人間が日常的に用いる一般的な戦略である「地図の活用」には注目していません。本研究では、モデルに「地図を用いた思考(Thinking with Map)」の能力を付与し、これを「地図内エージェントループ(agent-in-the-map loop)」として定式化します。これに伴い、2段階の最適化スキームを提案します。第1段階ではエージェント型強化学習(agentic reinforcement learning, RL)を用い、モデルのエージェント機能を強化してサンプリング効率を向上させ、第2段階では並列的テスト時スケーリング(parallel test-time scaling, TTS)を導入し、最終予測の前に複数の候補経路を同時に探索可能にします。このTTSは、ジオローカライゼーションにおいて極めて重要です。本手法の有効性を最新かつ現実世界の画像データ上で評価するため、本研究では完全に実世界の画像から構成される包括的なジオローカライゼーション用学習・評価ベンチマーク「MAPBench」を新たに提案します。実験結果から、本手法は既存のオープンソースおよびクローズドソースモデルを多数の指標で上回り、特にGoogle Search/Mapを基盤としたGemini-3-Proと比較して、Acc@500m(500メートル以内の正解率)を8.0%から22.1%まで向上させました。
One-sentence Summary
The authors from Xiamen University, AMAP (Alibaba Group), and Southern University of Science and Technology propose a map-aware reasoning framework, Thinking with Map, which integrates agentic reinforcement learning and parallel test-time scaling into a looped agent-in-the-map architecture to enhance image geolocalization. By leveraging real-world map APIs and multi-path exploration, the method significantly improves location accuracy—achieving 22.1% Acc@500m, a substantial gain over Gemini-3-Pro with grounded search—demonstrating its effectiveness on in-the-wild images through the new MAPBench benchmark.
Key Contributions
-
The paper addresses the challenge of image geolocalization by introducing a novel "Thinking with Map" framework that equips large vision-language models with the ability to iteratively generate and verify location hypotheses using real-world map tools, mimicking human geolocation strategies that rely on map-based validation rather than pure internal reasoning.
-
It proposes a two-stage optimization approach combining agentic reinforcement learning to improve sampling efficiency and a parallel test-time scaling method with a verifier, leveraging the self-verifying nature of map-API outputs to explore multiple reasoning trajectories simultaneously and select the most causally consistent one.
-
The method is evaluated on MAPBench, a new benchmark of real-world Chinese urban street-view images, and outperforms existing open- and closed-source models, achieving a significant improvement in Acc@500m from 8.0% to 22.1% compared to Gemini-3-Pro with Google Search/Map grounding.
Introduction
The task of image geolocalization—determining the precise geographic location of an image—has evolved from traditional classification and retrieval methods to leveraging large vision-language models (LVLMs) with reasoning capabilities. However, existing LVLM-based approaches rely heavily on internal knowledge and chain-of-thought reasoning, often overlooking the real-world strategy humans use: interacting with maps to validate visual clues. This gap limits their accuracy and robustness, especially on ambiguous or in-the-wild images. The authors introduce a novel framework called Thinking with Map, which equips an LVLM with map-augmented agentic capabilities by enabling it to iteratively hypothesize and verify locations using map tools such as POI search, static map queries, and spatial validation. To enhance performance, they propose a two-stage optimization: agentic reinforcement learning to improve hypothesis generation, followed by parallel test-time scaling with a verifier that selects the most consistent trajectory from multiple explorations. This approach is evaluated on MAPBench, a new benchmark of real-world Chinese urban images, and outperforms both open- and closed-source models, including Gemini-3-Pro, particularly improving accuracy at 500 meters from 8.0% to 22.1%.
Dataset

- The dataset consists of MAPBench, a new geolocalization benchmark designed to address limitations in existing datasets, along with two supplementary global datasets: IMAGEO-2 and GeoBench.
- MAPBench includes 5,000 street-view or storefront images centered on unique Points of Interest (POIs), uniformly sampled across 20 cities in China to ensure broad geographic coverage and up-to-date content.
- Each image is sourced either from street-view or storefront photos, selected randomly per POI, ensuring freshness and avoiding outdated or obsolete POIs found in older benchmarks.
- The dataset is split into 2,500 training and 2,500 test samples, with the test set further categorized into easy and hard subsets based on zero-shot predictions from three base models: GPT-5, GPT-o3, and Qwen3-VL-235B-A22B.
- A test sample is labeled as easy if at least two models predict a location within 10km of the ground truth; otherwise, it is labeled as hard. This results in 599 easy and 1,901 hard test samples.
- The easy split evaluates the memorization and pre-trained world knowledge of base models, while the hard split specifically tests agentic reasoning and the ability to use external knowledge.
- IMAGEO-2, derived from crowd-sourced Google Map POI images, contains 2,929 filtered images; 2,027 are used for training and 902 for testing.
- GeoBench includes 512 normal photos (from the internet), 512 panoramas (via Mapillary API), and 108 satellite images (from Sentinel-2 Level-2A via Microsoft Planetary Computer), all used exclusively for testing.
- The paper uses MAPBench as the primary training and evaluation dataset, with IMAGEO-2 and GeoBench serving as additional test sets to assess generalization across diverse image types and global coverage.
- No image cropping is applied; all images are used in their original resolution. Metadata such as ground-truth coordinates and category labels are constructed from official POI databases and map APIs to ensure accuracy.
Method
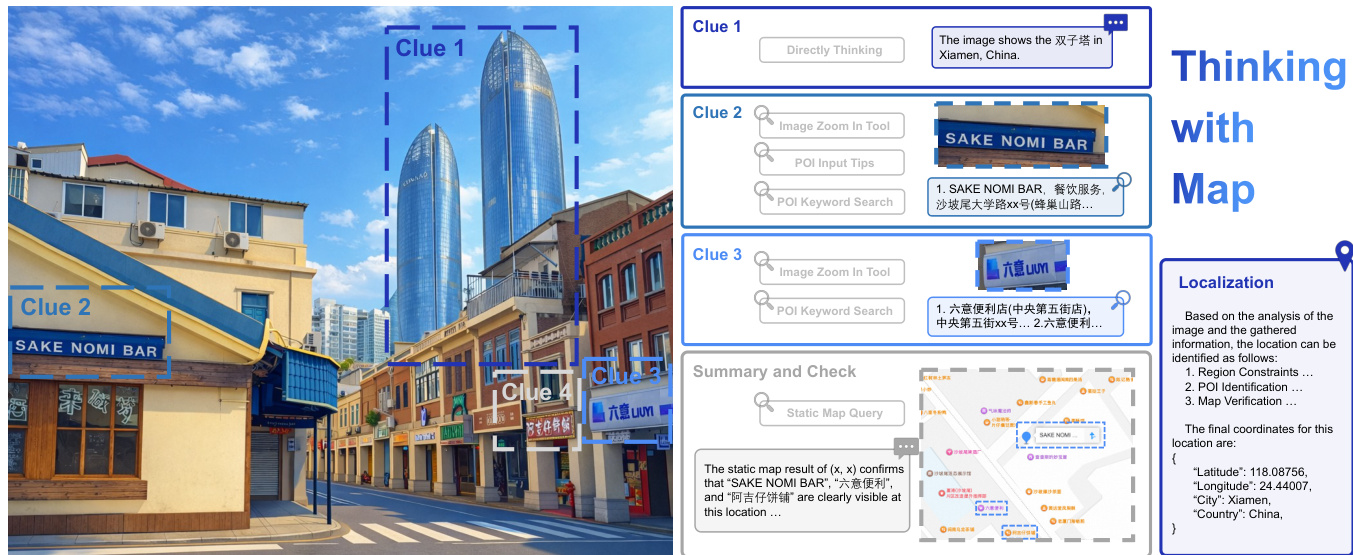
The authors leverage a map-augmented agent framework, termed Thinking with Map, to enhance geolocalization performance in large vision-language models (LVLMs). The core methodology is structured around an iterative agent-in-the-map loop, where the model engages in a process of hypothesis generation, map retrieval, cross-validation, and decision convergence. This framework is formalized as an interaction between a policy model πθ and a structured map environment Penv. Given a geolocalization query qimage,text, the policy model at each iteration t can either propose a new location hypothesis τt or verify existing hypotheses τ<t through tool-call actions αt to retrieve information from the map environment. The resulting map tool responses ot are treated as observations, and together with the history of prior interactions, form an evidence chain st. This evidence chain is used for cross-validation over structured information, and it also serves to update an implicit candidate pool Ct of potential locations, which is maintained throughout the interaction process until convergence or budget exhaustion. The policy model then selects the final answer from this candidate pool.
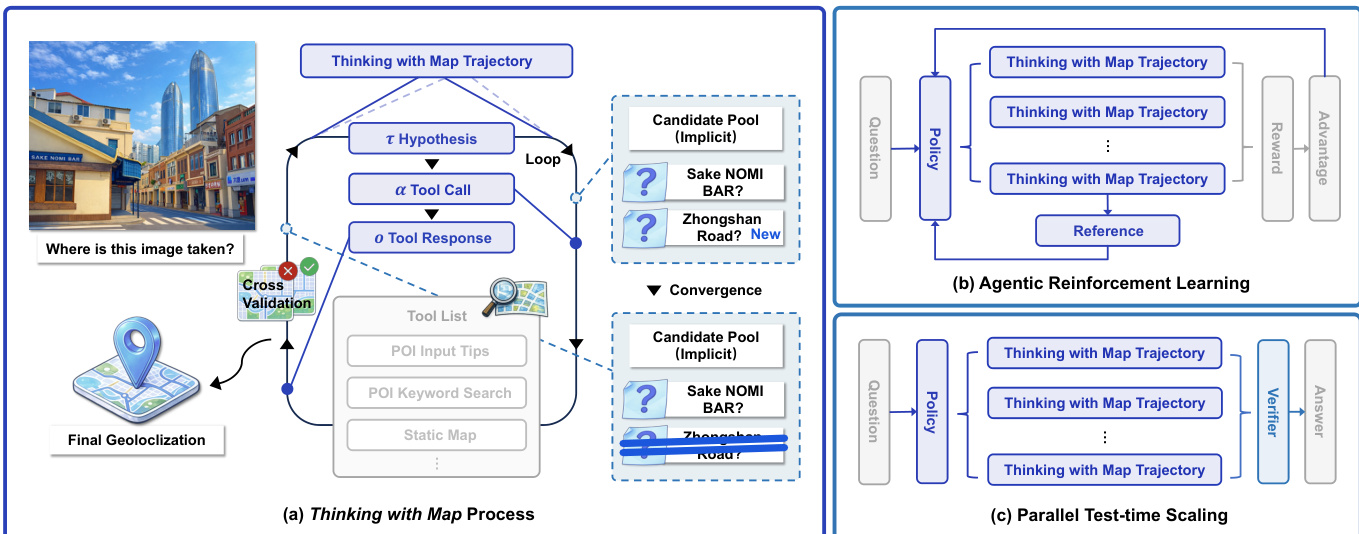
The framework incorporates a suite of map tools designed to mimic human reasoning, including POI search for obtaining location details, static and satellite maps for scene verification, and an image_zoom_tool for inspecting visual clues. To ensure global applicability, the system employs two types of map API providers. The overall process is illustrated in the framework diagram, which shows the agent's iterative loop of proposing hypotheses, calling tools, receiving responses, and updating the candidate pool, culminating in a final geolocalization.

To improve the agent's performance from pass@N to pass@K, the authors apply agentic reinforcement learning (RL) to the base model. They adopt the Group Relative Policy Optimization (GRPO) algorithm, which optimizes the policy by maximizing the advantages of a group of agent trajectories generated for each query. The policy is updated based on the relative performance of these trajectories, with a KL divergence penalty to prevent large deviations from the reference policy. The reward function is designed for continuous distance evaluation, using a piecewise discrete scheme that assigns higher rewards for more accurate predictions, reflecting different localization granularities. The model is prompted to output answers in a fixed JSON format, enabling structured parsing for the reward function.
To further enhance performance and achieve pass@1, the authors implement a parallel test-time scaling approach. This method leverages the fact that the agent's trajectories contain self-verifiable information. Given a query and the reinforced policy, the model samples N independent Thinking with Map trajectories in parallel. These trajectories are then fed into a separate LVLM-based verifier, which summarizes the evidence and selects the most plausible prediction as the final answer. This verifier pipeline aggregates the results from multiple parallel reasoning paths, effectively transferring the performance gains from pass@K to pass@1.
Experiment
- Evaluates Thinking with Map against closed-source models (GPT-o3, GPT-5, Gemini-3-Pro) and open-source models (Qwen3-VL-235B-A22B, GLOBE, GeoVista) on MAPBench, GeoBench, and IMAGEO-2-test.
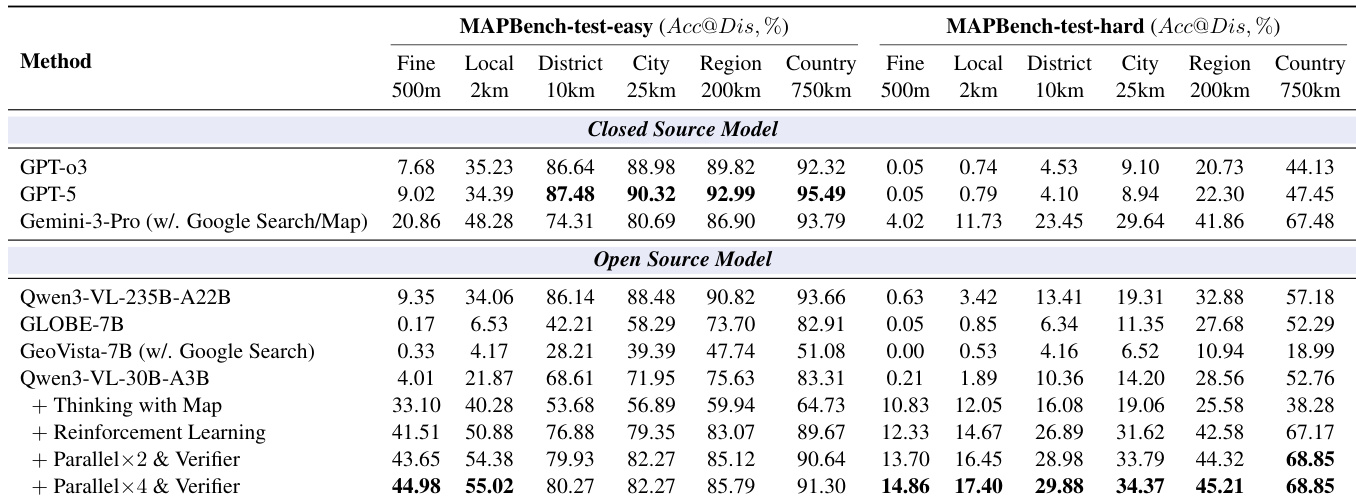
- Achieves state-of-the-art performance, with Acc@500m of 14.86% on MAPBench-test-hard, surpassing Gemini-3-Pro (4.02%), and 57.94% on GeoBench and 20.53% on IMAGEO-2-test, outperforming prior methods.
- Demonstrates that map tools significantly enhance fine-grained localization (Acc@500m increases from 1.12% to 16.16%), while potentially harming coarse-grained accuracy due to noisy inputs.
- Reinforcement learning training improves pass@K accuracy across all granularities, reduces variance, and enables better pass@K from pass@N, though Best@500m shows limited improvement.
- Parallel TTS with a 30B verifier yields performance gains that scale with the number of parallel samples, and verifier model capacity becomes critical at higher parallelism.
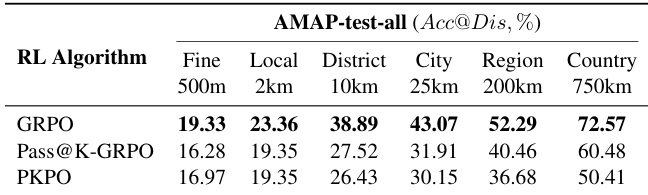
- GRPO outperforms Pass@K-GRPO and PKPO in RL training, confirming its effectiveness for agentic geolocation.
The authors use a comprehensive evaluation framework to compare their Thinking with Map method against both closed- and open-source models on geolocation tasks. Results show that Thinking with Map achieves the highest accuracy across multiple granularities, particularly excelling in fine-grained localization with 57.94% accuracy at 500m on IMAGEO-2-test and 57.94% at 500m on GeoBench, outperforming all other models including the best closed-source model Gemini-3-Pro.
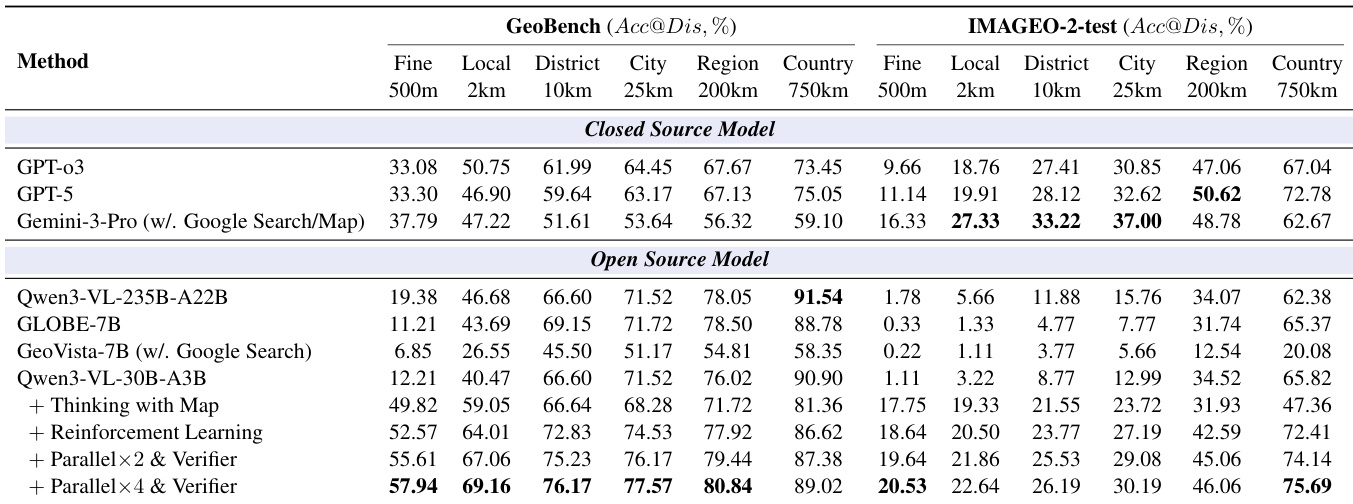
The authors compare their Thinking with Map method against multiple open- and closed-source models on several benchmarks, including GeoBench and IMAGEO-Bench, using accuracy at different distance granularities as the evaluation metric. Results show that Thinking with Map achieves the highest performance across most metrics, particularly excelling in fine-grained localization (Acc@500m) compared to all other models.

The authors use Table 8 to evaluate the impact of different verifier models on geolocation accuracy, comparing Qwen3-VL-30B-A3B, Qwen3-VL-235B-A22B, and GPT-5 as verifiers with 2 and 4 parallel samples. Results show that increasing the number of parallel samples improves accuracy across most granularities, and GPT-5 consistently outperforms the Qwen3-VL models, especially at higher parallelism levels.
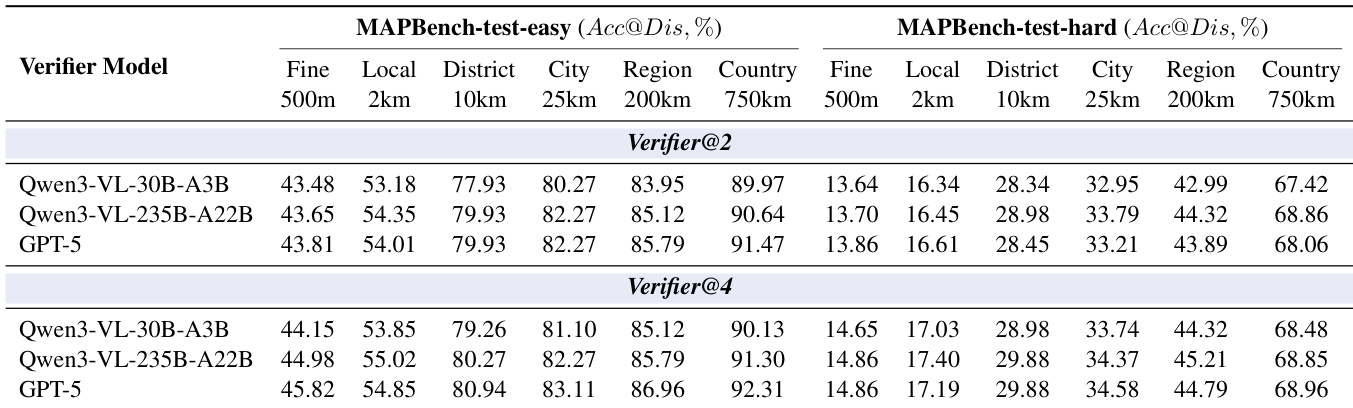
The authors use a comprehensive evaluation framework to compare their Thinking with Map method against closed- and open-source models on geolocation tasks, with results showing that their approach achieves the highest accuracy across multiple granularities, particularly excelling in fine-grained localization on both MAPBench-test-easy and MAPBench-test-hard. Results show that the method outperforms even the best closed-source models, such as Gemini-3-Pro, especially at the 500m level, and that reinforcement learning and parallel verification significantly enhance performance, with the best results achieved using a 4× parallel sampling strategy.
The authors compare different RL algorithms for their Thinking with Map method, evaluating performance on the AMAP-test-all benchmark across multiple localization granularities. Results show that GRPO achieves the highest accuracy across all levels, with the best performance at fine-grained localization (19.33% at 500m) and consistently outperforming Pass@K-GRPO and PKPO.