Command Palette
Search for a command to run...
野生における潜在行動世界モデルの学習
野生における潜在行動世界モデルの学習
Quentin Garrido Tushar Nagarajan Basile Terver Nicolas Ballas Yann LeCun Michael Rabbat
概要
現実世界における推論および計画が可能なエージェントは、自らの行動がもたらす結果を予測する能力を備えている必要がある。世界モデルはこの能力を有しているが、多くの場合、行動ラベルを必要とし、スケールに応じたラベルの取得は複雑である。このため、動画から行動空間を学習できる潜在行動モデルの学習が促進されている。本研究では、単純なロボットシミュレーションやビデオゲーム、操作データに焦点を当てた従来の研究を拡張し、リアルな環境(in-the-wild)から得られる動画を用いた潜在行動世界モデルの学習という課題に取り組む。これにより、より豊かな行動を捉えることが可能となる一方で、動画の多様性に起因する課題、例えば環境ノイズや動画間での共通した身体性(embodiment)の欠如といった問題も生じる。これらの課題に対処するため、行動が満たすべき性質や関連するアーキテクチャの選択、評価方法について検討する。我々の結果から、連続的だが制約された潜在行動は、in-the-wild動画から得られる行動の複雑性を捉えることができ、従来の一般的なベクトル量子化(vector quantization)では達成できないことが明らかになった。例えば、人間が部屋に入ることなど、エージェントによる環境の変化が動画間で共有可能であることが確認された。これは、in-the-wild動画に特有の行動を学習する能力を示している。動画間で共通の身体性が存在しない状況下では、主にカメラに相対的な空間的に局在化した潜在行動の学習にとどまるが、既知の行動を潜在行動にマッピングするコントローラを学習可能である。これにより、潜在行動を汎用インターフェースとして利用し、行動条件付きのベースラインと同等の性能で世界モデルを用いた計画タスクを解決することが可能となった。本研究の分析と実験は、潜在行動モデルを現実世界へスケーリングするための一歩を示している。
One-sentence Summary
The authors from FAIR at Meta, Inria, and NYU propose a latent action world model trained solely on in-the-wild videos, demonstrating that continuous, constrained latent actions—unlike discrete vector quantization—effectively capture complex, transferable actions across diverse real-world scenes. By learning camera-relative, spatially localized actions without a common embodiment, their model enables a universal action interface, allowing planning performance comparable to action-labeled baselines despite training on unlabeled data.
Key Contributions
- This work addresses the challenge of learning latent action world models from in-the-wild videos, where action labels are absent and video content exhibits high diversity in embodiment, environment, and agent behavior, extending beyond controlled settings like robotics simulations or video games.
- The authors demonstrate that continuous, constrained latent actions—rather than discrete representations via vector quantization—better capture the rich, diverse, and transferable actions present in real-world videos, including changes caused by external agents like humans entering a scene.
- Experiments on large-scale in-the-wild datasets show that learned latent actions can be localized relative to the camera and used to train a controller that maps known actions to latent ones, enabling planning tasks with performance comparable to action-conditioned baselines.
Introduction
The authors address the challenge of enabling agents to reason and plan in real-world environments by learning world models that predict the consequences of actions. While traditional world models rely on labeled action data—often unavailable at scale—latent action models (LAMs) aim to infer action representations directly from unlabeled videos. Prior work has largely focused on controlled settings like video games or robotic manipulation, where actions are well-defined and embodiments are consistent, limiting generalization. In contrast, this work tackles the more complex and diverse domain of in-the-wild videos, which include varied agents, unpredictable events, and no shared embodiment. The key contribution is demonstrating that continuous, constrained latent actions—rather than discrete, quantized ones—can effectively capture rich, transferable action semantics from such videos, including changes caused by external agents like people entering a scene. Despite the lack of a common embodiment, the learned latent actions become spatially localized relative to the camera, and the authors show they can serve as a universal interface for planning by training a controller to map known actions to latent ones, achieving performance comparable to action-conditioned baselines. This advances the feasibility of scaling world models to real-world, unstructured video data.
Method
The authors leverage a latent action world model framework to predict future video frames by modeling the evolution of the world state conditioned on both past observations and a latent action variable. The core architecture, illustrated in the framework diagram, consists of a frame causal encoder fθ that processes video frames into representations st, a world model pψ that predicts the next frame st+1 given the past sequence s0:t and a latent action zt, and an inverse dynamics model gϕ that infers the latent action zt from a pair of consecutive frames st and st+1. The world model pψ is trained to minimize the prediction error L=∥st+1−pψ(s0:t,zt)∥1, where zt is obtained from the inverse dynamics model. This joint training process enables the model to learn a latent action space that captures the essential information for future prediction.
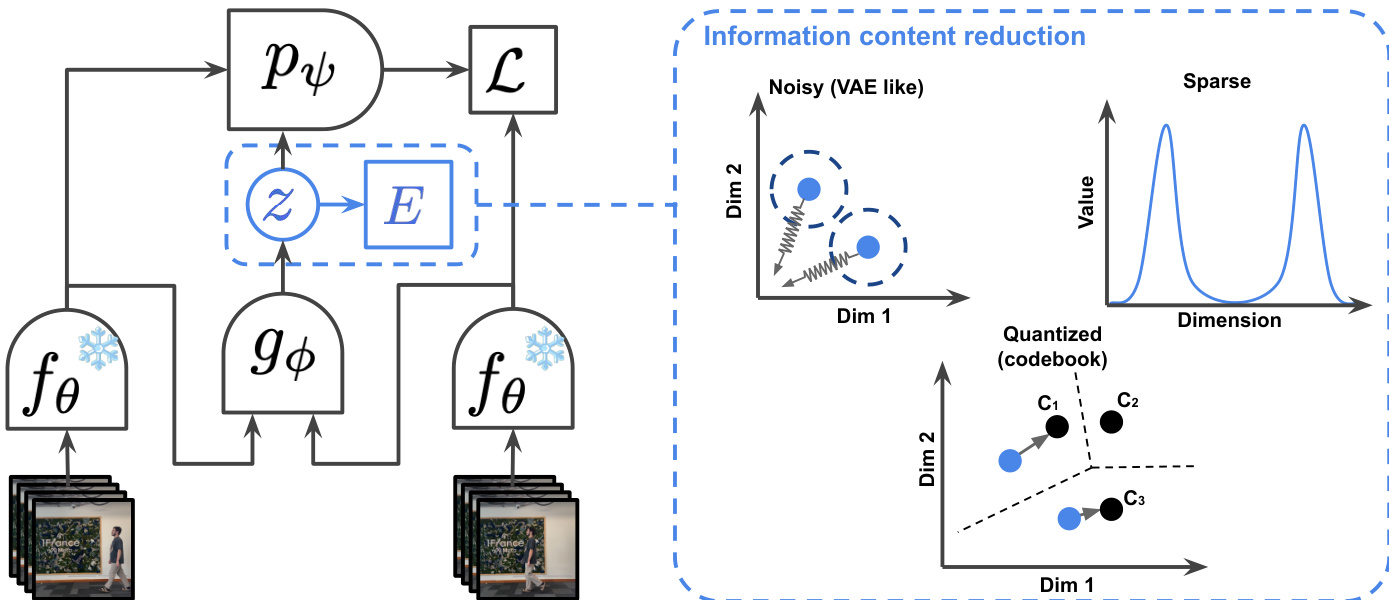
To ensure the latent action zt contains only the necessary information for prediction and avoids encoding extraneous noise or the entire future state, the authors employ three distinct information content reduction mechanisms. The first is sparsity, which constrains the latent actions to have a low L1 norm. This is achieved through a regularization term L(Z) that combines a Variance-Covariance-Mean (VCM) regularization with an energy function E(z) to promote sparsity while preventing trivial solutions. The second mechanism is noise addition, where the latent actions are regularized to follow a prior distribution, such as N(0,1), similar to a Variational Autoencoder (VAE). This is implemented via a KL divergence term that encourages the latent action distribution to match the prior. The third approach is discretization, which uses vector quantization to map continuous latent actions to a finite set of discrete codebook entries, effectively limiting the information capacity of the latent space. The framework diagram illustrates these three regularization strategies within the "Information content reduction" block.
The world model pψ is implemented as a Vision Transformer (ViT-L) with RoPE positional embeddings, and it is conditioned on the latent action zt using AdaLN-zero, which adapts the conditioning to be applied frame-wise. The latent actions zt are 128-dimensional continuous vectors by default. The model is trained using teacher forcing, where the ground truth next frame is used as input for the next prediction step during training. The training process involves optimizing the prediction loss L and the chosen latent action regularization simultaneously. The authors also train a frame causal video decoder to generate visualizations of the model's predictions, which is used for qualitative evaluation and perceptual metric computation.
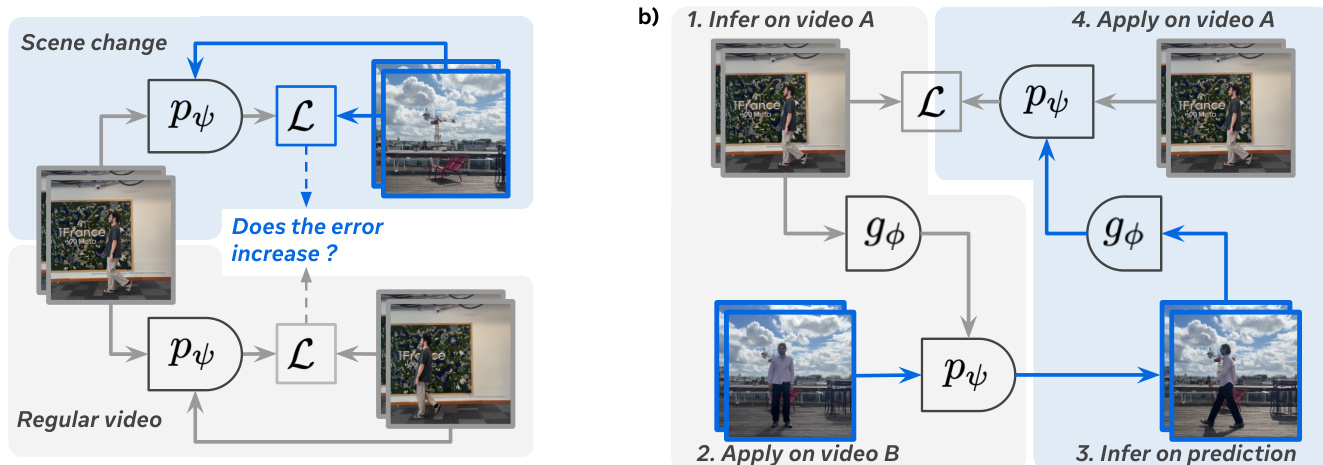
The learned latent action space can be used as an interpretable interface for planning. The authors train a lightweight controller module, which can be an MLP or a cross-attention based adapter, to map real-world actions (and optionally past representations) to the learned latent actions. This controller is trained with an L2 loss to predict the latent action produced by the inverse dynamics model. Once trained, the controller can be used to generate action sequences for planning tasks. The process involves inferring the latent action from the current state and goal, and then using the world model to predict the resulting future states. The controller training process is illustrated in the diagram, showing how the controller learns to map known actions to the latent action space, with past representations helping to disambiguate the action's effect based on the current camera perspective.
Experiment
- Conducted experiments on regulating latent action information content in in-the-wild videos, showing that sparse and noisy continuous latent actions adapt better to complex, diverse actions than discrete or quantized ones.
- Demonstrated that latent actions encode spatially-localized, camera-relative transformations without requiring a common embodiment, enabling effective transfer of motion between objects (e.g., human to ball) and across videos.
- Validated that latent actions do not leak future frame information, as prediction error more than doubles under artificial scene cuts, confirming they capture meaningful, non-cheating representations.
- Showed high cycle consistency in latent action transfer across videos (Kinetics and RECON), with minimal increase in prediction error, indicating robust and reusable action representations.
- Achieved planning performance on robotic manipulation (DROID) and navigation (RECON) tasks comparable to models trained on domain-specific, action-labeled data, using only a small controller trained on natural videos.
- On DROID and RECON datasets, the latent action world model achieved planning performance within 0.06–0.05 L1 error, matching or approaching baselines trained with explicit action labels.
- Found that optimal performance arises from a balanced latent action capacity—too high capacity reduces transferability and generality, while too low limits expressiveness.
- Scaling experiments showed improved inverse dynamics model performance with larger models, longer training, and more data, with training time yielding the clearest gains in downstream planning.
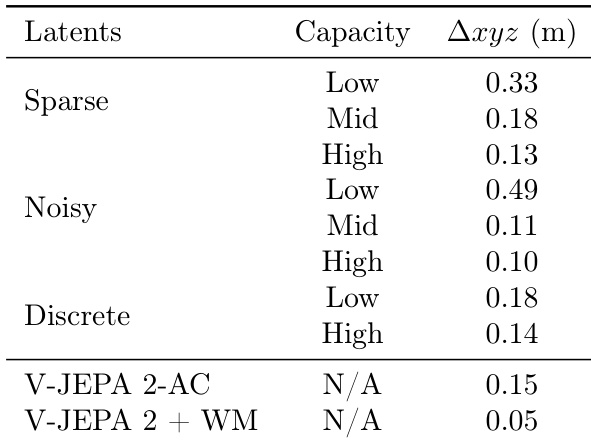
The authors evaluate the planning performance of latent action models with varying capacities on robotic manipulation tasks, measuring the error in cumulative displacement. Results show that models with high capacity latent actions achieve lower error, with the V-JEPA 2 + WM model achieving the best performance at 0.05 meters.
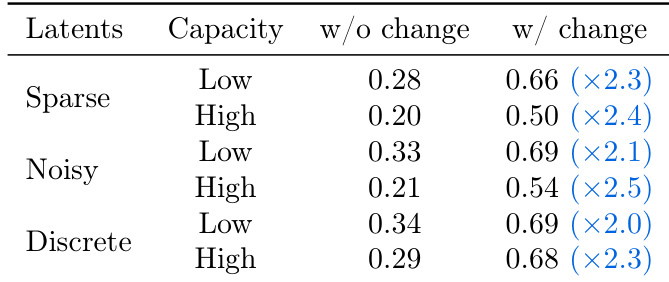
The authors evaluate the transferability of latent actions across different regularization methods and capacities, measuring prediction error increases when actions inferred on one video are applied to another. Results show that sparse and noisy latent actions achieve lower prediction errors with higher capacity, while discrete latent actions perform worse, particularly at high capacity, indicating that continuous latent actions are more effective for transfer.
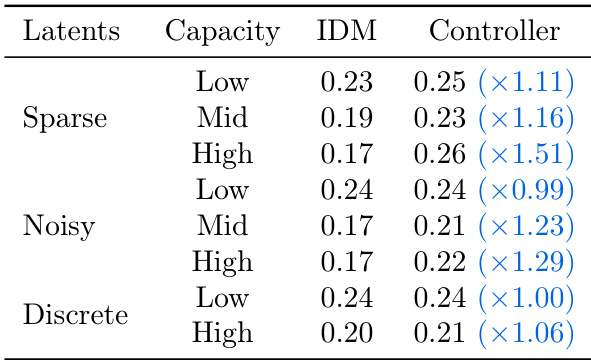
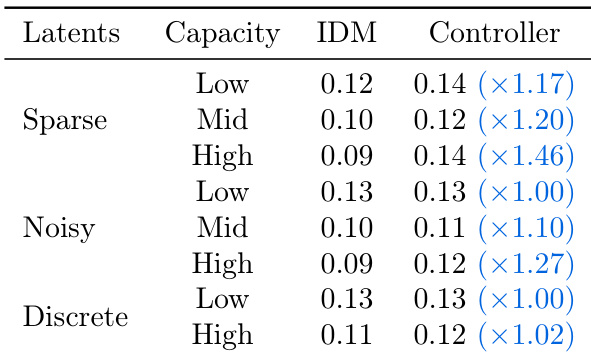
The authors compare different latent action regularization methods and their impact on prediction and control performance. Results show that sparse and noisy latent actions achieve lower prediction errors in the inverse dynamics model (IDM) and maintain consistent performance when used for control, while discrete latent actions perform worse in both settings. The best control performance is achieved with mid-capacity sparse and noisy latents, indicating a balance between action complexity and identifiability.
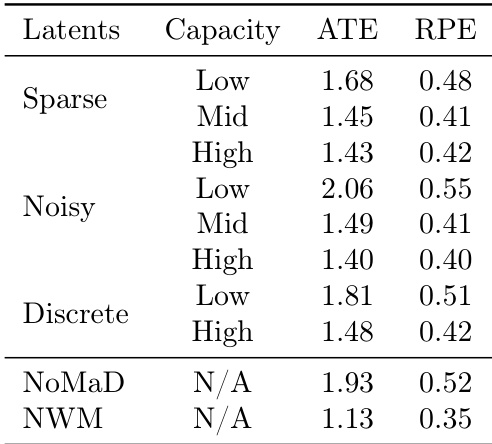
The authors evaluate the performance of different latent action regularizations on planning tasks using ATE and RPE metrics. Results show that noisy latent actions with high capacity achieve the lowest ATE and RPE values, outperforming sparse and discrete actions, while the NoMaD and NWM baselines perform worse or are not applicable.
The authors compare different latent action regularization methods, finding that sparse and noisy latent actions achieve lower prediction errors in both inverse dynamics model (IDM) and controller tasks compared to discrete ones. While higher capacity generally improves performance, the best results are achieved with moderate capacity, indicating a trade-off between action complexity and transferability.