Command Palette
Search for a command to run...
VideoAuto-R1:一度の思考で済ませ、二度の回答を行うことで実現する動画自動推論
VideoAuto-R1:一度の思考で済ませ、二度の回答を行うことで実現する動画自動推論
概要
チェーン・オブ・シンキング(CoT)推論は、動画理解タスクにおけるマルチモーダル大規模言語モデルにとって強力なツールとして浮上している。しかし、直接回答を行う手法と比較した場合の必要性や利点については、まだ十分に検討されていない。本研究では、RL(強化学習)で訓練された動画モデルにおいて、CoTがより高い計算コストを伴いながらも、ステップバイステップの分析を生成するにもかかわらず、直接回答がしばしば同等あるいはそれ以上の性能を発揮することを実証する。この知見を受けて、我々は「必要に応じて推論を行う」戦略を採用する動画理解フレームワーク「VideoAuto-R1」を提案する。学習段階では、本手法は「一度の思考、二度の回答」のパラダイムに従う:モデルはまず初期回答を生成し、次に推論処理を行い、最後に見直された回答を出力する。両方の回答は、検証可能な報酬(verifiable rewards)を用いて教師信号として監督される。推論段階では、初期回答の信頼度スコアを基に、推論処理を実行するかどうかを判断する。動画QAおよびグランドイングベンチマークにおいて、VideoAuto-R1は顕著な効率向上を伴いながらも、最先端の精度を達成しており、平均応答長を約3.3倍短縮(例:149トークンから44トークンへ)している。さらに、知覚中心のタスクでは推論モードの起動率が低く、一方で推論を要するタスクでは高い起動率が観察された。これは、明示的な言語ベースの推論が一般的には有益であるものの、必ずしも常に必要ではないことを示唆している。
One-sentence Summary
Meta AI, KAUST, and Princeton University propose VideoAuto-R1, a video understanding framework that adopts a "thinking once, answering twice" paradigm, where models generate an initial answer followed by a reasoned review, both supervised via verifiable rewards. During inference, a confidence-based early-exit mechanism dynamically activates reasoning only when necessary, reducing average response length by 3.3x while achieving state-of-the-art accuracy on video QA and grounding benchmarks, demonstrating that explicit reasoning is beneficial but not always required.
Key Contributions
- Existing chain-of-thought (CoT) reasoning methods for video understanding often incur high computational costs without consistently improving accuracy, as RL-trained models frequently achieve comparable or better performance with direct answering, especially on perception-focused tasks.
- The paper introduces VideoAuto-R1, a "thinking once, answering twice" framework that trains models to generate an initial answer, followed by reasoning and a revised answer, both supervised with verifiable rewards, enabling efficient, adaptive reasoning without explicit think/no-think labels.
- On video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy while reducing average response length by ~3.3x (from 149 to 44 tokens), with inference-time early-exit based on confidence scores enabling dynamic activation of reasoning only when needed.
Introduction
The authors leverage recent advances in chain-of-thought (CoT) reasoning for multimodal large language models in video understanding, where explicit step-by-step reasoning has become standard. However, they identify a key limitation: for many video tasks—especially perception-oriented ones—CoT reasoning often provides minimal accuracy gains while significantly increasing computational cost and response length due to verbose, redundant explanations. Their analysis reveals that direct answering frequently matches or exceeds CoT performance, challenging the assumption that extended reasoning is universally beneficial. To address this, the authors propose VideoAuto-R1, a framework that adopts a "thinking once, answering twice" training paradigm: the model generates an initial answer, performs reasoning, and then outputs a refined answer, with both supervised via verifiable rewards. At inference, a confidence-based early-exit mechanism dynamically decides whether to terminate early (direct answer) or continue with reasoning, enabling adaptive, efficient inference. This approach achieves state-of-the-art accuracy across video QA and grounding benchmarks while reducing average response length by approximately 3.3x, demonstrating that reasoning should be applied only when necessary.
Dataset

- The dataset comprises text, image, and video modalities, drawn from multiple sources to support multimodal reasoning.
- Text-based reasoning is powered by DAPO-Math (Yu et al., 2025), image-based reasoning by ViRL (Wang et al., 2025a) and ThinkLite-Hard (Wang et al., 2025c), and video QA by Video-R1 (Feng et al., 2025), TVBench (Cores et al., 2024), STI-Bench (Li et al., 2025c), and MMR-VBench (Zhu et al., 2025).
- To strengthen temporal grounding and grounding-based QA, the authors include Charades-STA (Gao et al., 2017), ActivityNet (Fabian et al., 2015), Time-R1 (Wang et al., 2025d), and NExT-GQA (Xiao et al., 2024).
- All test samples from evaluation benchmarks are manually excluded to prevent data leakage, resulting in an initial pool of approximately 137K samples.
- A filtering pipeline is applied to refine the dataset: invalid ground-truth samples are removed using math-verify for math problems and rule-based checks for QA.
- For each remaining QA sample, 8 responses are generated using the base model Qwen2.5-VL-7B-Instruct with high temperature.
- A smaller LLM, Qwen3-30B-A3B-Instruct, evaluates each response and labels it as correct or incorrect.
- Samples where all 8 responses are correct (too easy) or all are incorrect (too hard) are discarded, as they offer limited value for GRPO-based reinforcement learning.
- This difficulty-based filtering is applied only to QA tasks; temporal grounding samples are retained in full to address the base model’s grounding limitations.
- After filtering, the final training set contains 83K samples, as detailed in Table 10.
- The data is used in training with a mixture of modalities and tasks, with the filtered 83K samples forming the core training split.
- No cropping is applied to images or videos; metadata is constructed based on task type, modality, and source to support training and evaluation.
Method
The authors leverage a novel framework, VideoAuto-R1, designed to enable video reasoning models to reason only when necessary, thereby improving both efficiency and training stability. The overall architecture, illustrated in the framework diagram, consists of a policy model that generates responses conditioned on a question, followed by a reinforcement learning (RL) training loop and a confidence-based early-exit mechanism at inference. The framework operates under the principle that reasoning should be a post-hoc verification process rather than a mandatory initial step.
During training, the model is trained using Group Relative Policy Optimization (GRPO), a recent RL method that replaces a learned critic with group-normalized, rule-based rewards. As shown in the framework diagram, the policy model samples G candidate outputs for a given prompt q. Each output oi is evaluated by a reward function that computes a verifiable reward ri, such as answer accuracy or format correctness. These rewards are then normalized using the group-wise mean μ and standard deviation σ to obtain relative advantages Ai. The training objective is a clipped objective function that maximizes the expected advantage while regularizing the policy against a reference policy via a KL penalty. This training process is applied to a dual-answer output format, where each response consists of an initial answer, a reasoning rationale, and a reviewed answer.
The training data is carefully curated to enhance long-chain reasoning capabilities. It includes high-quality text and image sources covering math and scientific problems, as well as video QA and temporal grounding data. Notably, the training process is conducted directly with reinforcement learning, bypassing a cold-start supervised fine-tuning (SFT) stage, which is often expensive and can degrade performance. The model is trained on a dataset of 83K samples, with the primary goal of learning to generate a concise initial answer and a more accurate reviewed answer.
The output format for training is strictly defined as a1 <think> r </think> a2, where a1 and a2 are short, verifiable answers and r is a free-form rationale. This format is enforced by a carefully designed system prompt, enabling the model to generate both direct and CoT outputs in a single generation without requiring a cold-start SFT. To handle complex problems where an initial answer is infeasible, a fallback string, "Let's analyze the problem step by step," is provided. When the model outputs this string, it is forced to continue to the reasoning and final answer generation.
The reward function is designed to supervise both the initial and reviewed answers. The total reward is a weighted sum of the task reward for the first answer Rtask(1)(a1), the task reward for the second answer Rtask(2)(a2), a format correctness reward Rfmt, and a fallback bonus Rfallback. The weights w1 and w2 are set such that w2>w1, prioritizing the correctness of the reviewed answer. The fallback bonus is a binary reward that is only given when the model correctly uses the fallback string and produces a correct final answer, encouraging honest deferral for difficult problems.
At inference, the model employs a confidence-based early-exit mechanism to determine whether to proceed with reasoning. After generating the initial answer a1, the model computes a length-normalized confidence score s(a1) based on the log probabilities of the tokens in a1. If this score exceeds a predefined threshold τ, the model terminates decoding and returns a1. Otherwise, it continues to generate the rationale and the reviewed answer a2. This mechanism allows for controllable trade-offs between accuracy and efficiency, as the threshold τ can be tuned to balance the two. The inference strategy is summarized in Algorithm 1, which outlines the steps of generating the initial answer, computing its confidence, and deciding whether to exit early or continue reasoning. The framework diagram illustrates this process, showing that the model first generates an initial answer, then computes its confidence, and finally decides whether to exit early or continue to the thinking and reviewed answer stages.
Experiment
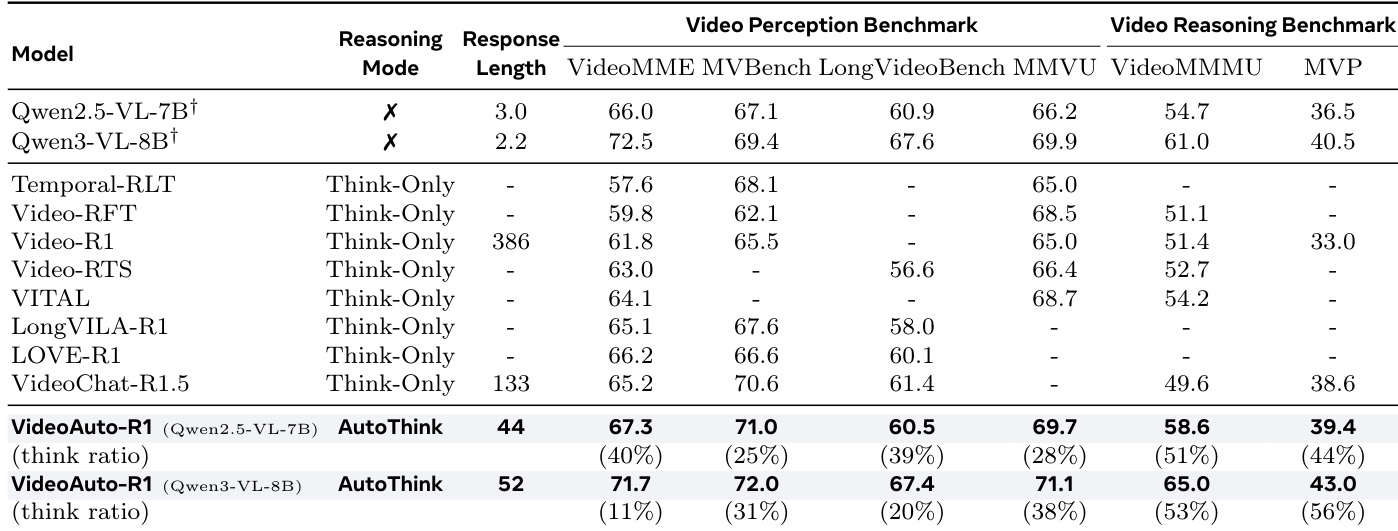
- VideoAuto-R1 achieves state-of-the-art results on video QA benchmarks: 67.3% accuracy on VideoMME (Qwen2.5-VL), surpassing Video-R1, VITAL, and VideoChat-R1.5 by 5.5%, 3.2%, and 2.1% respectively; 58.6% on Video-MMMU (+3.9% over baseline), and 39.4% pairwise accuracy on MVP (+2.9% over prior models).
- On reasoning-heavy benchmarks, VideoAuto-R1 improves accuracy while reducing average response length from 149 tokens (RL with thinking) to 44 tokens, with a think ratio of 51% on Video-MMMU and only 25% on perception tasks like MVBench.
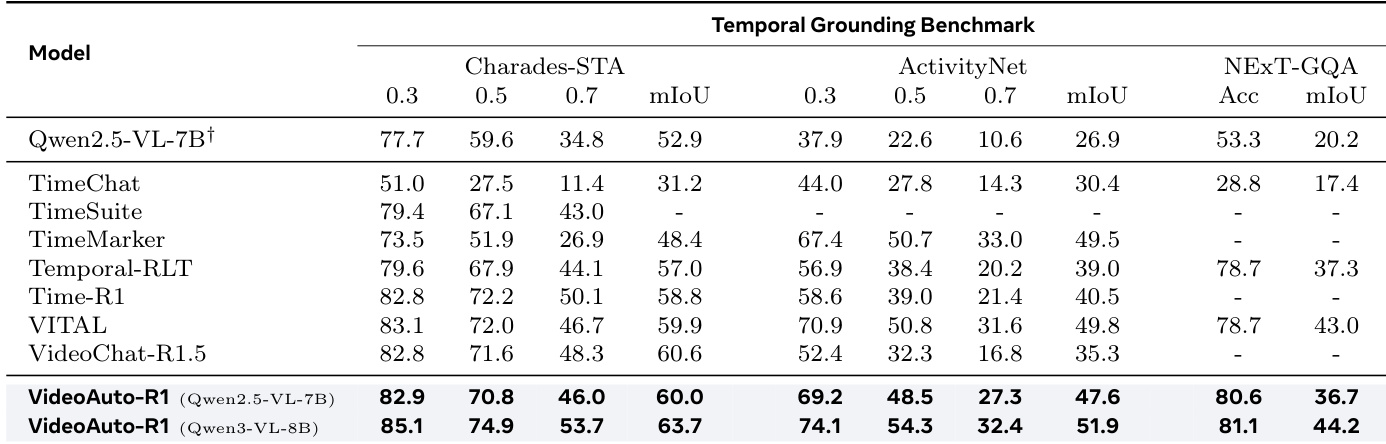
- For temporal grounding, the initial answer is sufficient for accurate localization; early exit without further reasoning maintains performance (e.g., mIoU unchanged on ActivityNet and NExT-GQA), enabling significant inference efficiency gains.
- Ablations confirm that dual-answer reward design (w₂ > w₁) and fallback reward (α) improve accuracy, and confidence-based early exit effectively routes reasoning to hard tasks, with a 4.0% accuracy gain on Video-MMMU.
- Data filtering improves performance and training efficiency, with combined text, image, and video data yielding best results, and removal of overly easy/hard samples consistently boosting performance.
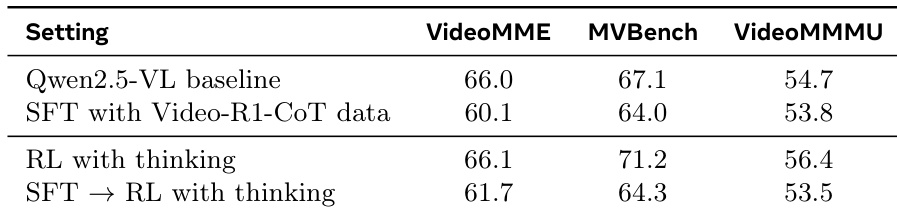
- Cold-start RL without CoT SFT outperforms SFT-based training, as low-quality CoT supervision degrades model performance, validating the effectiveness of direct reinforcement learning.
The authors compare different training strategies on the Qwen2.5-VL baseline, showing that direct SFT with Video-R1-CoT data degrades performance across all benchmarks. RL with thinking improves results on perception and reasoning tasks compared to the baseline, while the SFT → RL with thinking approach yields the best performance on VideoMME and MVBench, though it underperforms on VideoMMMU.
The authors use VideoAuto-R1, a model built on Qwen2.5-VL-7B, to evaluate its performance on image reasoning benchmarks. Results show that VideoAuto-R1 achieves higher accuracy than the Qwen2.5-VL-7B baseline across all tested benchmarks, with improvements ranging from 4.3% on MathVista to 10.9% on MM-Vet, demonstrating the effectiveness of its auto-thinking mechanism for reasoning tasks.

Results show that VideoAuto-R1 achieves consistent performance across different inference strategies on temporal grounding benchmarks, with no significant difference in mIoU or accuracy between the first and second answers. The model's confidence-based early exit mechanism effectively selects the initial answer without further reasoning, maintaining high accuracy while improving inference efficiency.

The authors use VideoAuto-R1, a model that adaptively triggers reasoning based on confidence, to achieve state-of-the-art results on both perception and reasoning video QA benchmarks. Results show that VideoAuto-R1 significantly outperforms existing thinking-only models on reasoning-heavy tasks like VideoMMMU and MVP while maintaining a much shorter average response length, demonstrating its effectiveness and efficiency.
Results show that VideoAuto-R1 achieves state-of-the-art performance on temporal grounding benchmarks, outperforming prior models such as Time-R1 and VITAL across multiple metrics. The model's initial boxed prediction is sufficient for accurate localization, and further reasoning provides only explanatory value without improving performance, supporting the use of early exit to enhance inference efficiency.