Command Palette
Search for a command to run...
UniCorn:自己生成された教師信号を用いた自己改善型統合型マルチモーダルモデルへの道
UniCorn:自己生成された教師信号を用いた自己改善型統合型マルチモーダルモデルへの道
概要
統合型マルチモーダルモデル(UMMs)は、クロスモーダル理解において顕著な成果を上げているが、その内部知識を高品質な生成に活用する能力に大きなギャップが依然として存在する。本研究では、この不一致を「伝導性失語症(Conduction Aphasia)」と定式化する。すなわち、モデルがマルチモーダル入力を正確に解釈する一方で、その理解を忠実かつ制御可能な生成に変換する能力に欠ける現象である。これを解決するために、外部データや教師ラベルの不要なシンプルかつ洗練された自己改善フレームワーク「UniCorn」を提案する。UniCornは、単一のUMMを「提案者(Proposer)」「解決者(Solver)」「評価者(Judge)」という三つの協調的役割に分割し、自己対戦(self-play)を通じて高品質な相互作用を生成するとともに、認知パターン再構成を用いて潜在的な理解を明示的な生成信号に抽出する。マルチモーダル整合性の回復を検証するため、テキスト→画像→テキストの再構成ループに基づくサイクル整合性ベンチマーク「UniCycle」を導入する。広範な実験により、UniCornは6つの一般的な画像生成ベンチマークにおいて、ベースモデルと比較して包括的かつ顕著な性能向上を達成した。特に、TIIF(73.8)、DPG(86.8)、CompBench(88.5)、UniCycleにおいてSOTA(最良)の成績を記録し、WISEでは+5.0、OneIGでは+6.5の大幅な向上を達成した。これらの結果は、本手法がテキストから画像(T2I)生成の質を顕著に向上させつつ、堅牢な理解能力を維持できることを示しており、統合型マルチモーダル知能における完全自己教師付き精緻化のスケーラビリティの可能性を示している。
One-sentence Summary
The authors from USTC, FDU, ECNU, CUHK, NJU, and SUDA propose UniCorn, a self-supervised framework that enhances unified multimodal models by decomposing them into Proposer, Solver, and Judge roles to enable self-play and cognitive pattern reconstruction, significantly improving text-to-image generation quality and coherence without external data, achieving SOTA results on multiple benchmarks including TIIF, DPG, and UniCycle.
Key Contributions
-
The paper identifies "Conduction Aphasia" in Unified Multimodal Models (UMMs), where strong cross-modal comprehension fails to translate into high-quality generation, and proposes UniCorn, a self-improvement framework that repurposes a single UMM’s internal capabilities into three collaborative roles—Proposer, Solver, and Judge—enabling self-supervised refinement without external data or teacher models.
-
UniCorn employs cognitive pattern reconstruction to convert multi-agent interactions into structured training signals, such as descriptive captions and evaluative feedback, thereby distilling latent understanding into explicit generative guidance and enabling autonomous, scalable improvement within a unified model architecture.
-
Extensive experiments show UniCorn achieves state-of-the-art performance on six image generation benchmarks, including TIIF (73.8), DPG (86.8), CompBench (88.5), and UniCycle (46.5), with significant gains of +5.0 on WISE and +6.5 on OneIG, while UniCycle, a novel cycle-consistency evaluation, validates enhanced multimodal coherence across text-to-image-to-text reconstruction.
Introduction
Unified Multimodal Models (UMMs) aim to integrate perception and generation within a single framework, enabling coherent reasoning across modalities—a key step toward Artificial General Intelligence. However, a critical limitation persists: strong comprehension often fails to translate into high-quality generation, a phenomenon the authors term "Conduction Aphasia," where models understand content but cannot reliably produce it. Prior self-improvement methods rely on external supervision, curated data, or task-specific reward engineering, limiting scalability and generalization. The authors introduce UniCorn, a post-training framework that enables fully self-contained improvement by treating a single UMM as a multi-agent system with three roles: Proposer (generates diverse prompts), Solver (produces image candidates), and Judge (evaluates outputs using internal comprehension). This self-generated feedback loop, enhanced by data reconstruction into structured signals, allows the model to refine its generation without external data or teacher models. To validate genuine multimodal coherence, they propose UniCycle, a cycle-consistency benchmark that measures conceptual alignment through text-to-image-to-text reconstruction. Experiments show UniCorn achieves state-of-the-art results across multiple benchmarks while maintaining robustness under out-of-distribution conditions, demonstrating that internal understanding can be repurposed as a powerful, self-sustaining training signal.
Method
The authors leverage a self-supervised framework, UniCorn, to bridge the comprehension-generation gap in unified multimodal models (UMMs) by enabling internal synergy through multi-agent collaboration and cognitive pattern reconstruction. The framework operates in two primary stages: Self Multi-Agent Sampling and Cognitive Pattern Reconstruction (CPR).
In the first stage, the UMM is functionally partitioned into three collaborative roles—Proposer, Solver, and Judge—within a single model, enabling a self-play loop without external supervision. The Proposer generates diverse and challenging text prompts for image generation, guided by fine-grained rules across ten predefined categories and enhanced by a dynamic seeding mechanism that iteratively refines prompt generation using previously sampled examples. The Solver then produces a set of images in response to these prompts, utilizing multiple rollouts per prompt to ensure diversity and quality. The Judge evaluates the generated images by assigning discrete scores from 0 to 10, leveraging task-specific rubrics and Chain-of-Thought reasoning to provide evaluative signals. This process, illustrated in the framework diagram, establishes a closed-loop system where the model generates, evaluates, and refines its own outputs.

In the second stage, Cognitive Pattern Reconstruction (CPR), the raw interactions from the self-play cycle are restructured into three distinct training patterns to distill latent knowledge into explicit supervisory signals. The first pattern, Caption, establishes bidirectional semantic grounding by training the model to predict the original prompt given the highest-scoring generated image, thereby reinforcing the inverse mapping from image to text. The second pattern, Judgement, calibrates the model's internal value system by training it to predict the evaluative score for any prompt-image pair, using the reasoning traces and rubrics from the Judge. The third pattern, Reflection, introduces iterative self-correction by training the model to transform a suboptimal image into an optimal one, using the contrast between high- and low-reward outputs from the same prompt. This process, detailed in the cognitive pattern reconstruction diagram, transforms the model's internal "inner monologue" into structured data that facilitates robust learning.

These three reconstructed data types—caption, judgement, and reflection—are combined with high-quality self-sampled generation data to fine-tune the UMM. The entire process is fully self-contained, requiring no external teacher models or human annotations. The framework's effectiveness is further validated through the UniCycle benchmark, which evaluates the model's ability to reconstruct textual information from its own generated content, as illustrated in the benchmark diagram.

Experiment
- UniCycle benchmark validates internal multimodal intelligence by measuring semantic preservation in a Text → Image → Text loop, achieving a Hard score of 46.5, outperforming base models by nearly 10 points and demonstrating superior self-reflection and unified understanding.
- On TIIF, UniCorn achieves a 3.7-point gain on short prompts and a 22.4-point improvement on the Text subtask of OneIG-EN, indicating strong instruction following and knowledge internalization.
- On WISE, UniCorn improves by 5 points, and on CompBench by 6.3 points, with notable gains in Numeracy (+13.1) and 3D Spatial (+6.1), surpassing GPT-4o on DPG (86.8 vs 86.2).
- Ablation studies confirm that Cognitive Pattern Reconstruction (CJR) stabilizes latent space and enables reciprocal reinforcement between understanding and generation, with removal of generation or judgment leading to performance collapse.
- Scaling experiments show that UniCorn achieves SOTA performance with only 5k self-generated samples, outperforming IRG (trained on 30k GPT-4o data) and DALL·E 3, demonstrating efficient, unbounded self-improvement.
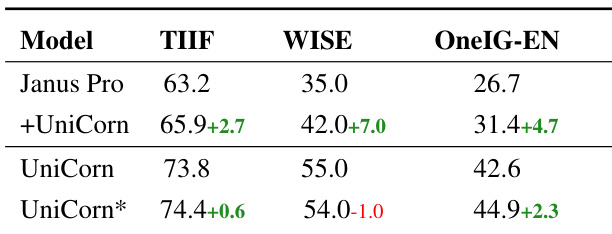
- UniCorn generalizes across architectures, improving Janus-Pro by +3.2 on TIIF and +7.0 on WISE, confirming its effectiveness in enhancing knowledge expression and understanding-guided generation.
The authors use the UniCycle benchmark to evaluate the ability of unified multimodal models to preserve instruction-critical semantics through a Text → Image → Text loop. Results show that UniCorn achieves the highest Hard score (46.5) on UniCycle, outperforming its base model BAGEL by nearly 10 points and other models by over 3 points, demonstrating superior self-reflection and comprehensive multimodal intelligence.
The authors use the UniCycle benchmark to evaluate the ability of unified multimodal models to preserve instruction-critical semantics through a Text → Image → Text loop. Results show that UniCorn achieves the highest Hard score (46.5) on UniCycle, significantly outperforming its base model BAGEL and other unified models, indicating superior internalization of knowledge and self-reflection capabilities.
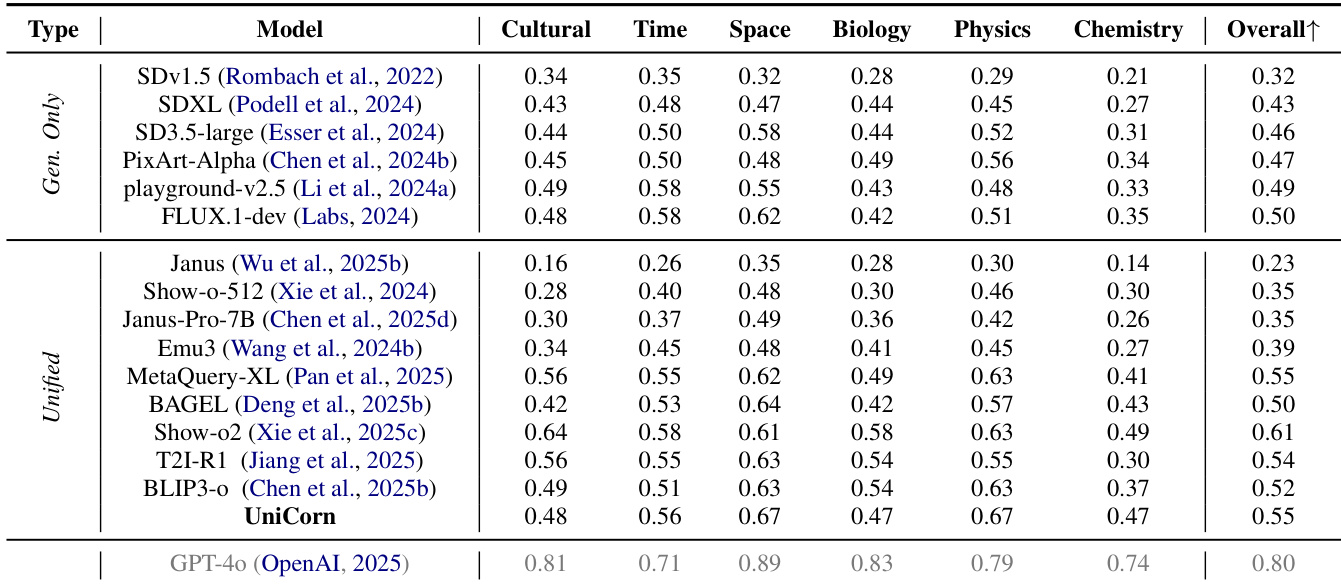
The authors use the UniCycle benchmark to evaluate the ability of multimodal models to preserve instruction-critical semantics through a Text → Image → Text loop. Results show that UniCorn achieves the highest Hard score of 46.5 on UniCycle, significantly outperforming its base model BAGEL and other unified models, indicating superior internalization of knowledge and self-reflection capabilities.
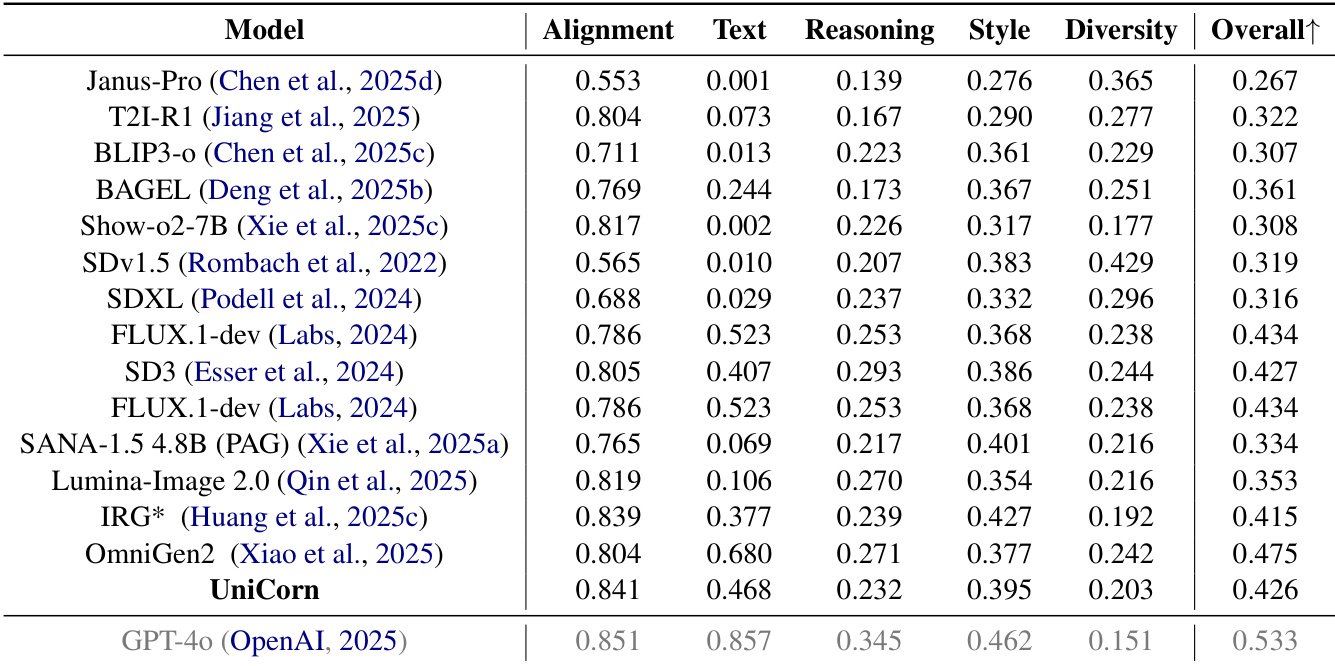
The authors use a table to compare UniCorn with other models on criteria including external model and data dependency, as well as hyperparameter tuning. Results show that UniCorn achieves state-of-the-art performance on OneIG-EN using only 5K training samples without relying on external task-specific models or annotated data, while also requiring no hyperparameter tuning.

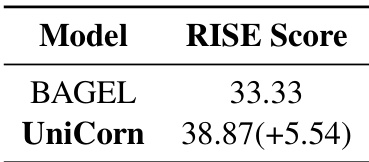
The authors use the RISE benchmark to evaluate the performance of UniCorn and its base model BAGEL. Results show that UniCorn achieves a RISE score of 38.87, which is 5.54 points higher than BAGEL's score of 33.33, indicating significant improvement in instruction-following and generation quality.