Command Palette
Search for a command to run...
NextFlow:統一された順序モデリングがマルチモーダル理解および生成を活性化する
NextFlow:統一された順序モデリングがマルチモーダル理解および生成を活性化する
概要
我々は、6兆個の交互に配置されたテキスト・画像の離散トークンを用いて訓練された統一型のデコーダーのみを搭載した自己回帰型Transformer「NextFlow」を提案する。統一された視覚表現と統一された自己回帰アーキテクチャを活用することで、NextFlowはマルチモーダルな理解および生成機能をネイティブに備え、画像編集、交互コンテンツ生成、動画生成といった能力を実現する。テキストは厳密に順序付けられている一方で、画像は本質的に階層構造を持つというモダリティ間の本質的な違いに着目し、テキスト生成では従来の次トークン予測を維持しつつ、視覚生成には次スケール予測を採用している。これは従来のラスタースキャン方式とは異なり、1024×1024の画像生成をわずか5秒で実現可能にし、同等の自己回帰モデルと比べて桁違いに高速である。また、多スケール生成における不安定性を克服するため、堅牢な学習戦略を導入している。さらに、強化学習におけるプレフィックスチューニング戦略を提案する。実験の結果、NextFlowは統一型モデルの中で最先端の性能を達成しており、視覚品質においては専用の拡散モデルベースラインと同等の水準にまで達していることが示された。
One-sentence Summary
The authors, from ByteDance, Tsinghua University, and Monash University, propose NextFlow, a unified decoder-only autoregressive transformer that uses next-scale prediction for visual generation—unlike raster-scan methods—enabling 1024×1024 image synthesis in under 5 seconds, achieving state-of-the-art multimodal performance and production-quality editing with a robust training and prefix-tuning strategy for reinforcement learning.
Key Contributions
- NextFlow introduces a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image tokens, overcoming the limitations of separate LLM and diffusion model paradigms by enabling native multimodal understanding and generation within a single architecture.
- It departs from raster-scan next-token prediction for images by adopting next-scale prediction, which generates high-resolution 1024×1024 images in just 5 seconds—orders of magnitude faster than prior autoregressive models—while a dual-codebook tokenizer ensures semantic richness and visual fidelity.
- The model achieves state-of-the-art performance among unified models, rivals specialized diffusion baselines in visual quality, and supports complex interleaved tasks like Chain-of-Thought reasoning and in-context image editing, validated on the EditCanvas benchmark and multiple multimodal benchmarks.
Introduction
The authors leverage a unified decoder-only transformer architecture to bridge the gap between multimodal understanding and generation, addressing the long-standing separation between large language models (LLMs) and diffusion models. While LLMs excel in reasoning and in-context learning, and diffusion models deliver high-fidelity image generation, prior unified approaches either suffer from inefficient raster-scan autoregressive generation—leading to prohibitively slow inference at high resolutions—or rely on reconstruction-oriented tokenizers that lack semantic richness, limiting understanding performance. NextFlow overcomes these challenges by introducing a next-scale prediction paradigm that generates images hierarchically from coarse to fine, reducing 1024×1024 image generation time to just 5 seconds, and employing a dual-codebook tokenizer that decouples semantic and pixel-level features for improved conceptual alignment. The model is trained on 6 trillion tokens across text, image-text pairs, and interleaved multimodal data, with a novel prefix-tuning strategy for Group Reward Policy Optimization that stabilizes reinforcement learning by focusing on coarse-scale structural predictions. For high-fidelity outputs, an optional diffusion decoder further refines the discrete generation, enabling state-of-the-art visual quality while preserving the unified architecture. The result is a model that matches diffusion-based systems in image quality, outperforms specialized models in image editing, and naturally supports complex interleaved tasks like Chain-of-Thought reasoning and in-context learning.
Dataset

- The dataset is a large-scale multimodal collection combining images and text, designed to support diverse tasks such as visual understanding, image generation, image editing, interleaved image-text document generation, and text generation.
- For visual understanding, the dataset includes image captioning samples from open-source sources, augmented with text-rich images (e.g., scenes with text, tables, charts) and images linked to world knowledge. Captions are rewritten using Vision-Language Models (VLMs) to improve quality and detail. Data is hierarchically structured, with primary categories and sub-categories, and visual samples highlight top 10 most prominent categories.
- The image generation component comprises a billion-scale dataset sourced from open repositories, high-quality photo collections (Megalith, CommonCatalog), and in-house image galleries. Images undergo heuristic filtering and aesthetic scoring (>4.3) to remove low-quality content. A zero-shot SigLip2 classifier balances topic distribution across categories like landscape, human, animal, plant, and food. All images are captioned via VLMs for accurate, detailed descriptions. A small amount of synthetic data is added during the CT stage to enhance generation aesthetics.
- Traditional editing data starts with open-source datasets (UniWorld-V1, RealEdit, ShareGPT-4o-Image), filtered for resolution mismatches and low-quality edits via manual inspection and VLM-based assessment. Bad edits—those not responding to instructions—are removed. To address bias toward simple tasks, a synthetic dataset is created with a more balanced task distribution across edit types (e.g., Add, Remove, Replace) and semantic categories (Local, Global, View, Text, Style).
- For interleaved generation, a video-text dataset is constructed from OmniCorpus-CC, OmniCorpus-YT, and Koala36M. Raw video clips are filtered: long clips (>20 seconds) are discarded, and only those with high aesthetic scores (>4.3, top 30%), clarity (>0.7, top 50%), and motion scores (>4) are retained—removing ~75% of data. Semantic balancing uses SigLIP to downsample overrepresented classes (e.g., 50% of "person" and "television news" clips removed). Motion-adaptive frame selection uses RAFT optical flow to discard static or camera-motion-only frames, preserving frames with significant object motion or structural changes. Frames are sampled at 0.5 FPS, with a maximum of 5 frames at 512px or 3 at 1k resolution. VLMs generate coherent transition texts between frames to form interleaved image-text sequences.
- The dataset is used in training with a mixture of data types: visual understanding, image generation, editing, and interleaved generation data are combined with tailored ratios. The model is trained on these components in a unified pre-training stage, with synthetic data introduced during CT to refine generation quality.
- Key processing includes VLM-based captioning for all image data, motion-aware frame selection, and semantic balancing via zero-shot classification. Metadata is constructed through automated VLM inference and manual filtering, ensuring high-quality, diverse, and representative content across all tasks.
Method
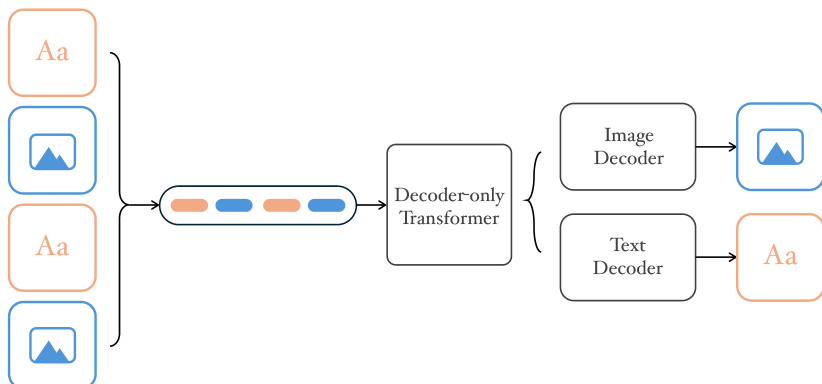
The authors leverage a unified decoder-only autoregressive transformer architecture, NextFlow, designed to process interleaved text-image discrete token sequences. The overall framework processes multimodal inputs and generates interleaved multimodal outputs, as illustrated in the framework diagram. The model is initialized from Qwen2.5-VL-7B, which provides strong multimodal priors, and is extended to support visual token prediction using a next-scale prediction paradigm. This approach departs from traditional raster-scan methods by generating images at progressively coarser scales, enabling the synthesis of 1024×1024 images in just 5 seconds. The model employs a single output head for both text and image tokens, trained with cross-entropy loss to predict codebook indices across both modalities.
The model's tokenizer utilizes a dual-codebook architecture, building upon TokenFlow, which decouples the learning of semantic and pixel-level features while maintaining their alignment via a shared-mapping mechanism. This design jointly constrains the quantization process by both reconstruction fidelity and semantic consistency, ensuring that discrete tokens encapsulate both high-level concepts and fine-grained visual details. The semantic encoder is initialized from siglip2-so400m-naflex, enabling variable resolution and aspect ratio processing, which, when combined with a CNN-based pixel branch, allows the AR model to train directly at native resolutions. Multi-scale VQ is employed to further enhance quantization quality.

Positional encoding is handled by a multi-scale 3D RoPE mechanism. For text tokens at position t, the position is replicated across all three dimensions: (t,t,t). For vision tokens, spatial and scale information are explicitly encoded using normalized spatial coordinates with augmented scale indices. Each patch at scale s with grid coordinates (i,j) receives position (px,py,ps)=(HWC(i+0.5),HWC(j+0.5),s), where H×W is the grid size and C is a constant range factor. This normalized formulation enables resolution-invariant training. Additionally, learnable scale embeddings and sinusoidal scale length positional embeddings are incorporated to enhance the model's ability to adapt to varying resolutions.
To address the imbalance in token count between early and late scales in the next-scale prediction paradigm, the authors introduce scale-aware loss reweighting. This assigns scale-dependent weights as ks=(hs×ws)α1, where hs×ws is the spatial resolution at scale s and α is a hyperparameter. This formulation increases the importance of early-scale predictions, ensuring stable structural generation. A self-correction mechanism is also introduced during training to mitigate exposure bias and local conflicts. This involves sampling from a multinomial distribution over the top-k nearest indices during encoding, while the model predicts the top-1 index as the target. The visual input uses residual features directly from the codebook without accumulation, which constrains the complexity of the visual input feature space and reduces local artifacts.
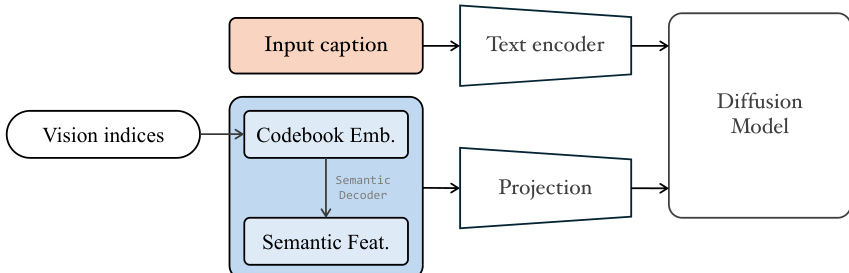
An optional diffusion decoder is introduced as a refinement module to push the boundaries of visual quality. After the next-scale visual index prediction, the corresponding embeddings from both the semantic and pixel codebooks are obtained. The semantic embeddings are processed through the tokenizer's semantic decoder to yield high-dimensional semantic features. These three elements—semantic embeddings, pixel embeddings, and decoded semantic features—are concatenated, projected, and fed into the diffusion model as a visual condition. The diffusion model also integrates the image caption via the text branch.

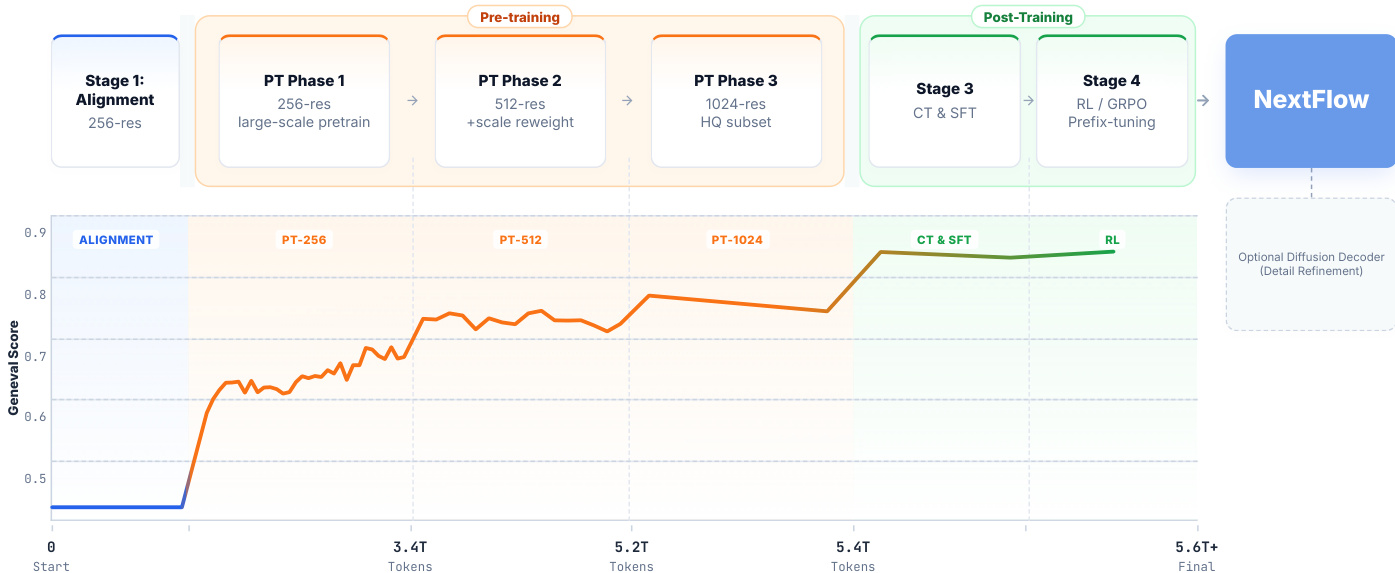
The training pipeline consists of several stages. The tokenizer is trained in a multi-stage strategy: first, the pixel branch is trained independently; then, all components are trained jointly; finally, the pixel decoder is fine-tuned separately. The model is pre-trained on approximately 6 trillion tokens across three sub-stages: 256-level, 512-level, and 1024-level, using a progressive resolution curriculum. At 512-level, a scale-reweighting strategy is applied to stabilize training and eliminate artifacts. After pre-training, a two-phase post-training strategy is employed: continued training on high-quality data to improve aesthetic quality, followed by supervised fine-tuning on conversational data to enhance naturalness and contextually appropriate interactions.
For reinforcement learning, the authors employ Group Reward Policy Optimization (GRPO) and introduce a prefix-tuning strategy. Since early steps in the VAR architecture are most critical for global layout, the RL updates are focused on the coarse scales. The policies for the first m scales are optimized, while the policies for the finer scales remain frozen. This approach stabilizes training by concentrating the high-variance RL signal on the most semantically critical generation steps, avoiding noisy updates to later-stage policies.
Experiment
- Lightweight ablation studies validate the shared single-head output design, showing lower training losses and superior performance over dual-head variants, leading to its adoption for large-scale training.
- Self-correction with residual features significantly improves performance, achieving optimal results at 60% token correction probability (p=1.0), while accumulated features degrade performance due to input space complexity mismatch.
- Incorporating 25% text-only data during training does not harm text-to-image generation quality, preserving strong text capabilities.
- High-performance kernel optimizations (e.g., fused linear cross-entropy, RoPE, RMS norm, Flash-Attention) reduce peak memory usage by ~20GB per GPU and improve arithmetic intensity.
- Pre-extracting image indices offline eliminates online encoding latency and enables efficient data packing, improving training throughput.
- Workload balancing via precomputed TFLOPS reduces inter-GPU idle time, achieving a 4.1× speedup over naive packing.
- On GenEval, NextFlow RL achieves 0.84 (state-of-the-art), surpassing FLUX.1-dev and matching top-tier models.
- On WISE, NextFlow RL scores 0.62, matching Qwen-Image and outperforming autoregressive baselines (e.g., Show-o: 0.30).
- On PRISM-Bench, NextFlow RL achieves 78.8 overall, on par with Seedream 3.0 and Qwen-Image, demonstrating strong aesthetic and text rendering quality.
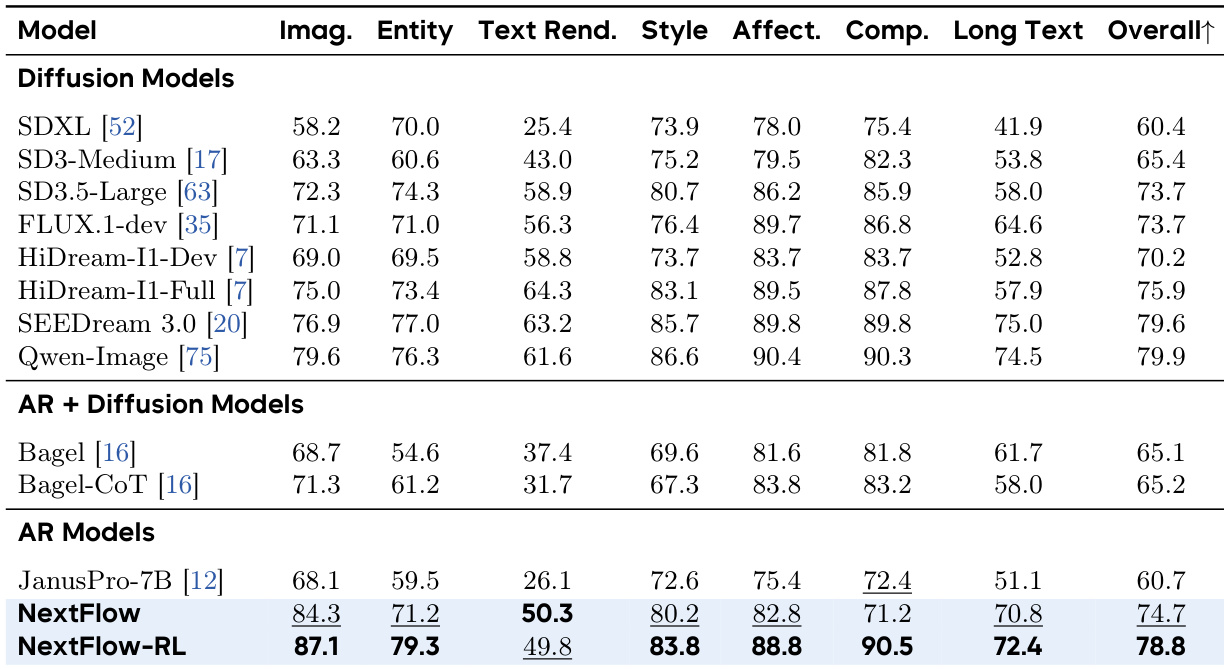
- On ImgEdit, NextFlow RL scores 4.49 (highest), excelling in Adjust (4.68) and Remove (4.67) tasks.
- On OmniContext, NextFlow RL achieves 9.22 SC, outperforming OmniGen2 (8.34) and approaching GPT-4o (9.03) in subject consistency.
- On GEdit-Bench, NextFlow RL achieves 7.87 overall, besting baselines in semantic consistency and perceptual quality.
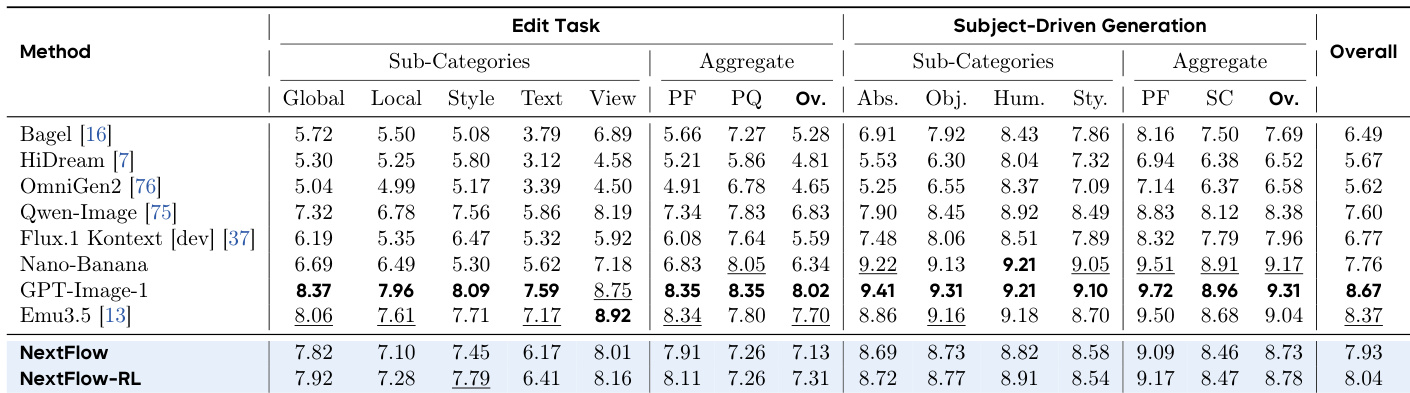
- On EditCanvas, NextFlow RL scores 8.04 overall, with 8.78 in Subject-Driven Generation, confirming balanced excellence in fine-grained editing.
- On interleaved generation, NextFlow produces coherent alternating text-image sequences across storytelling, recipes, and dynamic scenes.
- In-context learning enables NextFlow to infer and apply transformation patterns from examples, demonstrating strong adaptability.
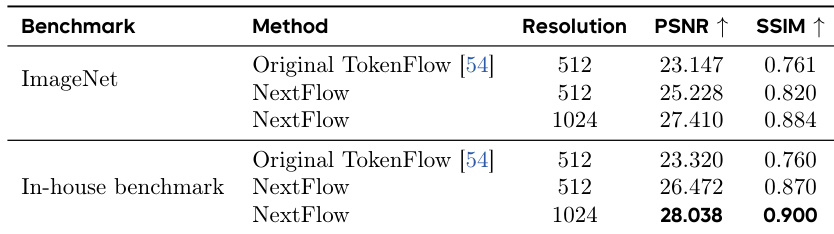
- On ImageNet-1K (512²), NextFlow improves PSNR by +2.08 dB over TokenFlow; at 1024², it reaches 28.04 PSNR, validating multi-stage training and scale dropout.
- On multimodal understanding benchmarks, the 7B model fine-tuned on 40M composite data (19M captioning + 21M SFT) achieves robust performance across tasks, outperforming larger baselines.
- Inference efficiency analysis shows NextFlow reduces FLOPs by up to 6× compared to MMDiT, due to dynamic token generation and KV-caching in the next-scale prediction paradigm.
The authors use a shared output head design for their decoder-only model, which achieves lower total and vision losses compared to separate modality-specific heads during both alignment and supervised fine-tuning phases. Results show that the shared head architecture consistently outperforms the dual-head approach, leading to the adoption of the simpler and more effective single-head design for all subsequent experiments.
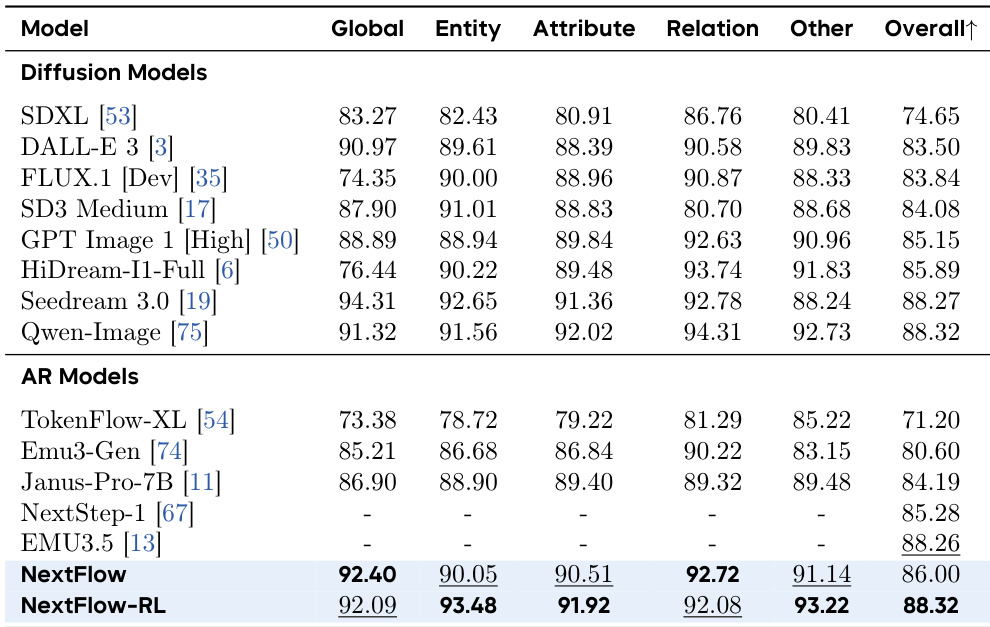
The authors use a shared output head design for their decoder-only model, which achieves lower training losses and better performance compared to separate modality-specific heads in both alignment and supervised fine-tuning phases. Results show that NextFlow-Rl achieves state-of-the-art performance across multiple benchmarks, outperforming diffusion-based models and other autoregressive models in prompt following, world knowledge, and aesthetic quality.
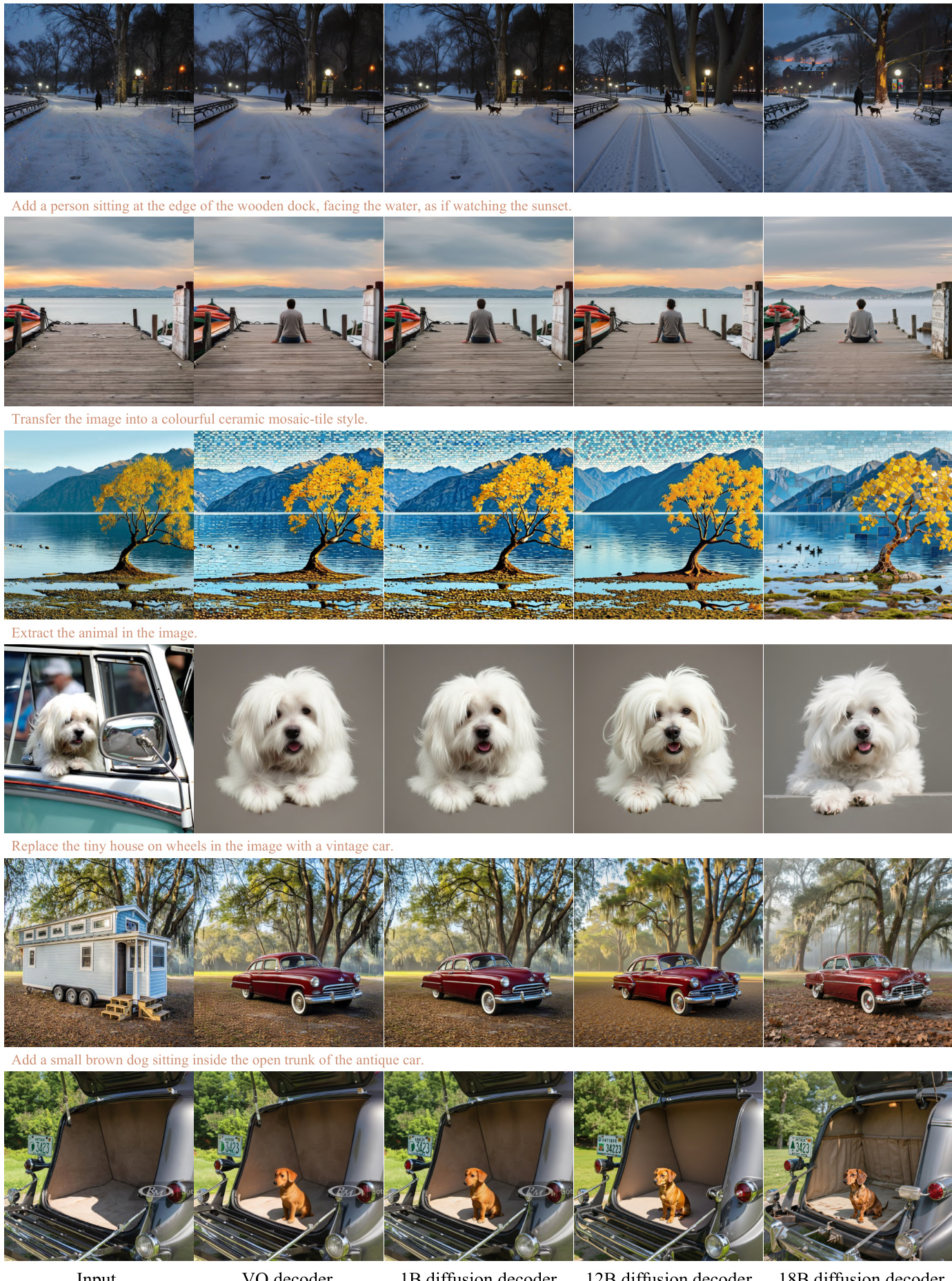
Results show that NextFlow-RL achieves the highest overall score of 8.04 on the EditCanvas benchmark, outperforming all compared methods across both traditional editing and subject-driven generation tasks. It demonstrates particular strength in subject-driven generation, with a score of 8.78, indicating precise local modifications while maintaining high aesthetic quality.
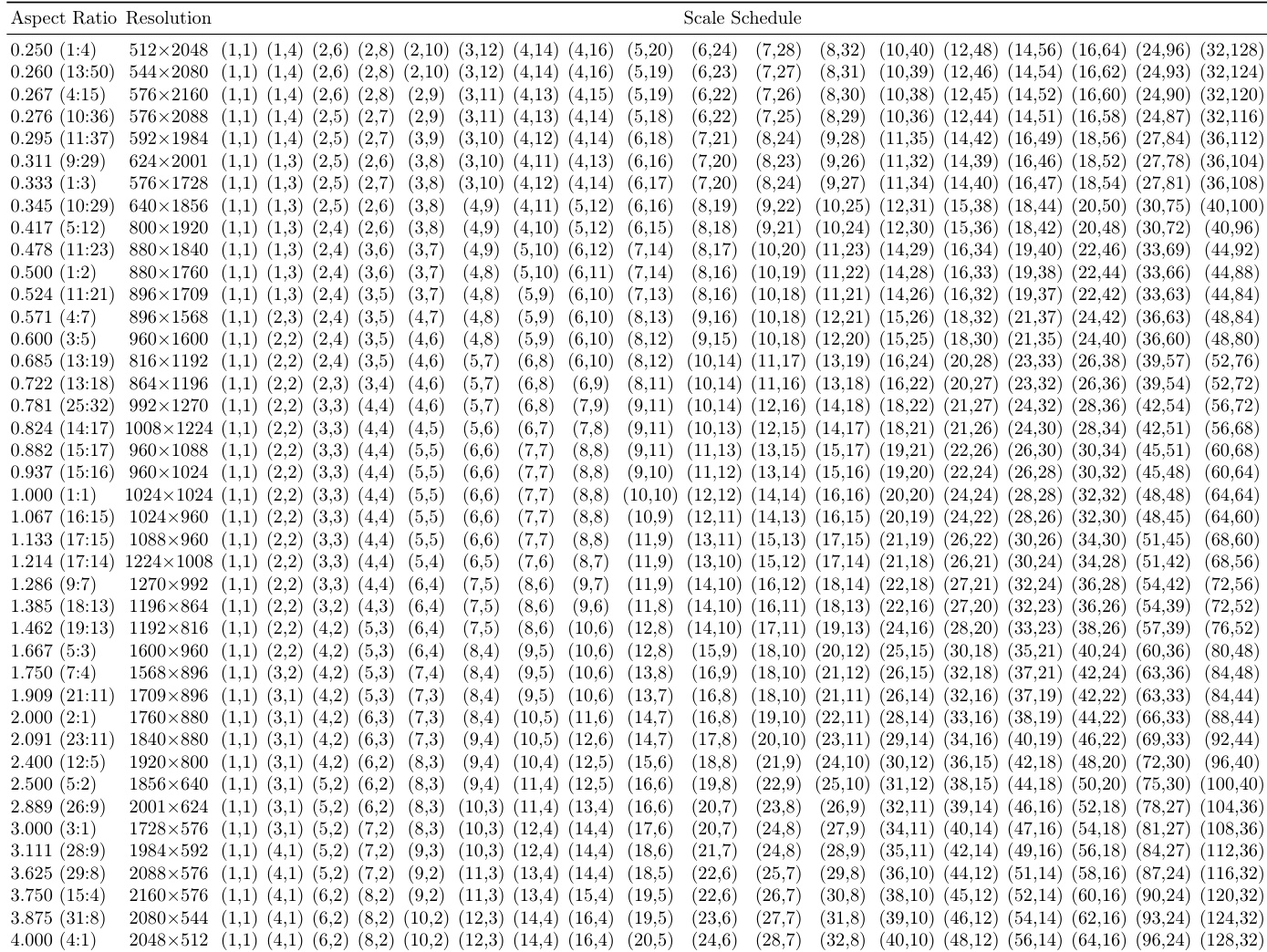
The authors use a scale schedule that varies the resolution and aspect ratio across training steps, with the scale increasing from 1×1 to the target resolution in a structured manner. The table shows that the model is trained on a wide range of resolutions and aspect ratios, with the scale schedule dynamically adjusting the sequence length at each step to support efficient next-scale prediction.
The authors compare NextFlow against the original TokenFlow architecture on image reconstruction tasks, showing that NextFlow achieves higher PSNR and SSIM scores across both 512×512 and 1024×1024 resolutions. Specifically, NextFlow improves PSNR by 2.08 dB on ImageNet-1K at 512×512 and reaches a PSNR of 28.038 on the in-house benchmark at 1024×1024, demonstrating the effectiveness of its multi-stage training and scale dropout strategies.