Command Palette
Search for a command to run...
GR-Dexter 技術報告
GR-Dexter 技術報告
概要
視覚-言語-行動(Vision-Language-Action: VLA)モデルにより、言語によって制御される長時間スパンのロボット操作が可能となったが、現存する大多数のシステムはハンド(グリッパー)に限定されている。高自由度(DoF)を持つ機敏な両手型ハンドを備えた二腕型ロボットへのVLAポリシーのスケーリングは、拡大した行動空間、頻発するハンドと物体の遮蔽、および実機データ収集のコストといった課題により、依然として困難である。本研究では、両手型機敏ハンドロボットにおけるVLAベースの汎用操作を実現するための包括的かつ統合的なハードウェア-モデル-データフレームワーク「GR-Dexter」を提案する。本手法は、コンパクトな21自由度のロボットハンドの設計、実機データ収集に向けた直感的な両腕遠隔操作システム、および遠隔操作によるロボット軌道データと大規模な視覚-言語データセット、さらに慎重に選別されたクロスエン bodiment データセットを活用したトレーニング手法を統合したものである。実世界における長時間スパンの日常的操作用および汎化可能なピックアンドプレースタスクにおいて、GR-Dexterは領域内での優れた性能を達成するとともに、未確認の物体や未確認の指示に対しても高いロバスト性を示した。本研究は、機敏なハンドを備えた汎用ロボット操作の実現に向けた実用的な一歩であると期待する。
One-sentence Summary
The authors propose GR-Dexter, a holistic framework for bimanual dexterous-hand manipulation using a 21-DoF robotic hand, intuitive teleoperation, and a training recipe combining real-robot trajectories with vision-language and cross-embodiment data, enabling robust, language-conditioned long-horizon tasks with improved generalization to unseen objects and instructions.
Key Contributions
- GR-Dexter addresses the challenge of scaling vision-language-action (VLA) models to bimanual robots with high-degree-of-freedom dexterous hands, which are hindered by expanded action spaces, frequent hand-object occlusions, and the high cost of real-robot data collection.
- The framework introduces a compact 21-DoF robotic hand (ByteDexter V2), an intuitive teleoperation system using Meta Quest and Manus gloves for efficient data collection, and a training recipe that co-trains on teleoperated robot trajectories, vision-language data, cross-embodiment demonstrations, and human hand-motion videos.
- In real-world evaluations, GR-Dexter achieves strong performance on long-horizon everyday manipulation tasks and demonstrates improved robustness to unseen objects and previously unseen language instructions, leveraging diverse data sources to enhance generalization beyond in-domain scenarios.
Introduction
Vision-language-action (VLA) models have advanced language-conditioned, long-horizon robot manipulation, but most systems are limited to gripper-based end effectors. Extending these models to bimanual robots with high-degree-of-freedom (DoF) dexterous hands is challenging due to the expanded action space, frequent hand-object occlusions, and the high cost of collecting real-robot data. Prior work struggles with data scarcity and poor generalization in complex, real-world settings. The authors present GR-Dexter, a holistic framework that integrates a compact 21-DoF anthropomorphic robotic hand (ByteDexter V2), an intuitive bimanual teleoperation interface using VR and glove tracking, and a VLA training recipe combining teleoperated robot trajectories, vision-language data, cross-embodiment human demonstrations, and curated human hand-object interaction datasets. This approach enables robust, generalizable dexterous manipulation in real-world long-horizon tasks and unseen scenarios, demonstrating a practical path toward generalist dexterous-hand robotics.
Dataset

- The dataset for GR-Dexter is composed of three main sources: web-scale vision-language data, cross-embodiment real-robot trajectories, and human trajectory data collected via VR devices.
- Vision-language data is reused from GR-3 and includes tasks like image captioning, visual question answering, and grounded image captioning, totaling a large-scale corpus used to train the VLM backbone via next-token prediction.
- Real-robot data comes from three open-source bimanual manipulation datasets: Fourier ActionNet (140 hours of humanoid bimanual manipulation with 6-DoF hands), OpenLoong Baihu (over 100k trajectories across multiple robot embodiments), and RoboMIND (107k trajectories across 479 tasks involving 96 object classes).
- Human trajectory data consists of over 800 hours of egocentric video with 3D hand and finger tracking, collected using Pico VR devices and supplemented with additional VR-based recordings to enhance diversity and scale.
- To handle structural differences across datasets, missing or unreliable action dimensions (e.g., absent joints in target embodiments) are masked during preprocessing.
- All visual inputs are standardized by resizing and cropping to ensure consistent scale of robot arms, hands, and objects across datasets.
- High-quality trajectories are retained after strict quality control, with only clean, stable sequences used in training.
- Cross-embodiment trajectories are retargeted to the ByteDexter V2 hand using fingertip-centric alignment, preserving task-relevant contact geometry while being robust to joint-level differences.
- Human trajectories undergo filtering based on hand visibility and motion velocity to reduce noise from ego-motion and temporal jitter. They are then mapped into the same visual and kinematic space as robot data through the same retargeting pipeline.
- Trajectories are resampled by task category to balance the training corpus and ensure even representation across diverse manipulation tasks.
- During training, the authors dynamically mix vision-language data and robot trajectories within mini-batches, combining next-token-prediction loss (for VLM backbone) and flow-matching loss (for action DiT) into a co-training objective.
- The unified preprocessing pipeline ensures seamless integration of all data types, enabling effective co-training of the VLM and action model on a diverse, high-quality, and balanced dataset.
Method
The authors leverage a modular and biomimetic design for the ByteDexter V2 robotic hand, which features a linkage-driven transmission mechanism to enhance force transparency, durability, and maintainability. The hand comprises 21 degrees of freedom (DoFs), with each of the four fingers having four DoFs and the thumb having five, enabling a wide range of oppositional motions. The four fingers share a modular architecture, each equipped with a universal joint at the metacarpophalangeal (MCP) joint and two revolute joints at the proximal interphalangeal (PIP) and distal interphalangeal (DIP) joints. The MCP joint is actuated by two motors housed in the palm, allowing for abduction-adduction and flexion-extension, while the PIP joint is independently actuated by a dedicated third motor, decoupling it from MCP motion. The thumb incorporates a universal joint at the carpometacarpal (CMC) joint and an additional revolute joint to approximate the human hand's saddle-shaped CMC joint, enabling flexion-extension and abduction-adduction. This design increases the thumb's range of motion and reachable workspace, facilitating robust oppositional contact with the other fingers. The DIP joints of the four fingers and the interphalangeal (IP) joint of the thumb are underactuated, utilizing a biomimetic four-bar linkage mechanism that couples each DIP to its corresponding PIP, replicating the intrinsic kinematic coupling observed in the human hand. The fingertips are equipped with high-density piezoresistive tactile arrays that measure normal contact forces, providing fine spatial resolution over the fingertip, finger pad, and lateral surface.
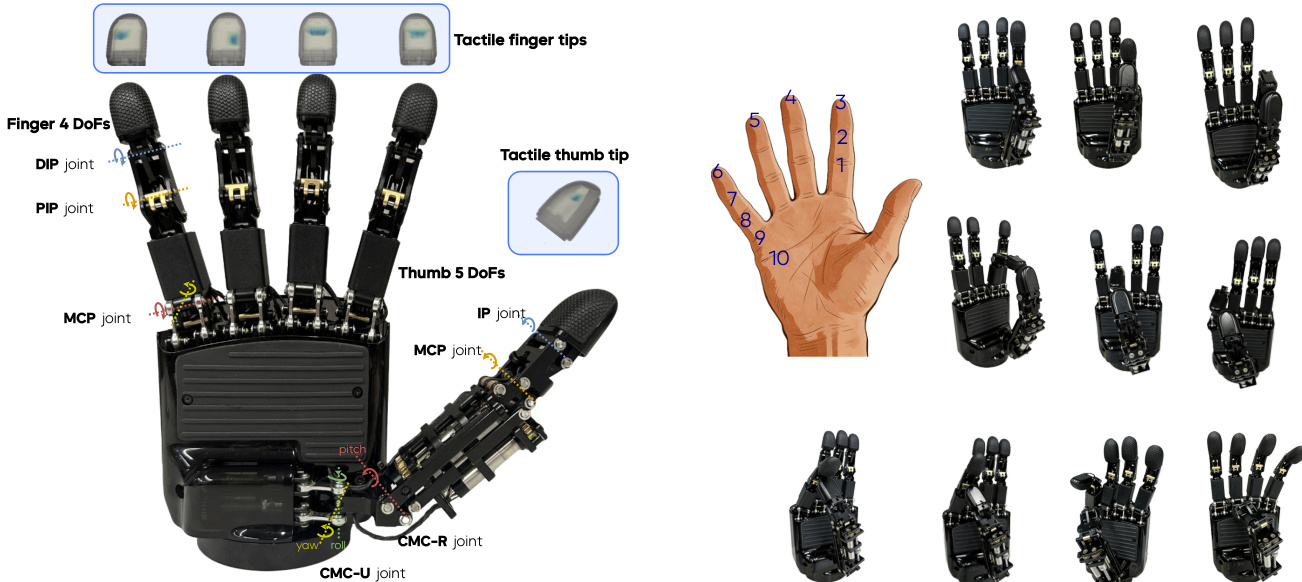
The bimanual robotic system integrates two ByteDexter V2 hands mounted on Franka Research 3 arms, forming a 56-DoF robot capable of coordinated arm-hand control for dexterous manipulation. To capture hand-object interactions from multiple perspectives and mitigate occlusions, the system deploys four global RGB-D cameras: one primary egocentric view and three complementary third-person views. The platform supports both teleoperated data collection and autonomous policy rollouts. For teleoperation, a bimanual interface combines a Meta Quest VR headset for wrist pose tracking, Manus Metagloves for hand movement capture, and foot pedals to enable or disable teleoperation. Two Meta Quest controllers are mounted on the dorsal side of the gloves to improve wrist–hand tracking reliability. Human motions are retargeted in real time to joint position commands via a whole-body controller, ensuring kinematically consistent mapping. The hand-motion retargeting is formulated as a constrained optimization problem that includes wrist-to-fingertip and thumb-to-fingertip alignment terms, collision-avoidance constraints, and regularization, solved using Sequential Quadratic Programming. During policy rollout, the model generates future action chunks that promote coordinated and temporally consistent arm–hand motions for dexterous manipulation. A parameterized trajectory optimizer smooths the generated actions, ensuring smooth transitions within and across chunks, which is critical for delicate grasping.
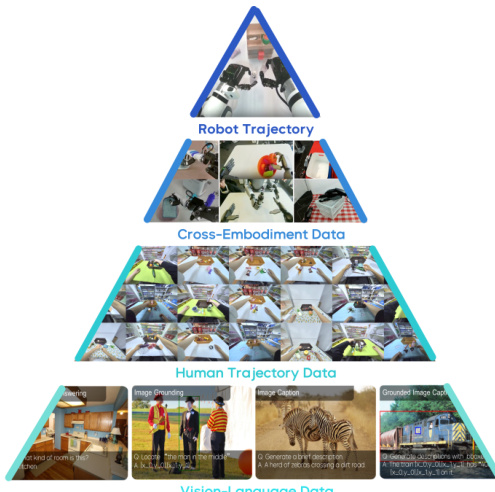
The GR-Dexter model follows the GR-3 architecture and employs a Mixture-of-Transformer framework for a vision-language-action (VLA) model πθ with 4 billion parameters. This model generates a k-length action chunk at=at:t+k conditioned on the input language instruction l, observation ot, and robot state st. Each action at is a vector of length 88, composed of: 1) arm joint actions (7 DoFs per arm), 2) arm end-effector poses (6D per arm), 3) hand joint actions (16 active DoFs per hand), and 4) fingertip positions (3D per finger). The model is trained on a diverse dataset that includes vision-language data, human trajectory data, and robot trajectory data, as illustrated in the framework diagram. The training process leverages cross-embodiment data to enable the model to generalize across different tasks and environments, such as makeup table decluttering, bread serving with tongs, vacuum handling, and generalizable pick-and-place operations.

Experiment
- Evaluated GR-Dexter on long-horizon bimanual manipulation and generalizable pick-and-place tasks using 21-DoF ByteDexter V2 hands and 20 hours of teleoperated robot trajectories.
- On the makeup decluttering task, GR-Dexter achieved 0.89 success rate in OOD settings with novel layouts, surpassing plain VLA's 0.64, while maintaining strong in-domain performance (0.97 vs. 0.96).
- Demonstrated reliable execution of complex tool-use tasks: vacuuming (stable grasp and power control) and bread serving (precise object transfer), showcasing long-horizon manipulation capabilities.
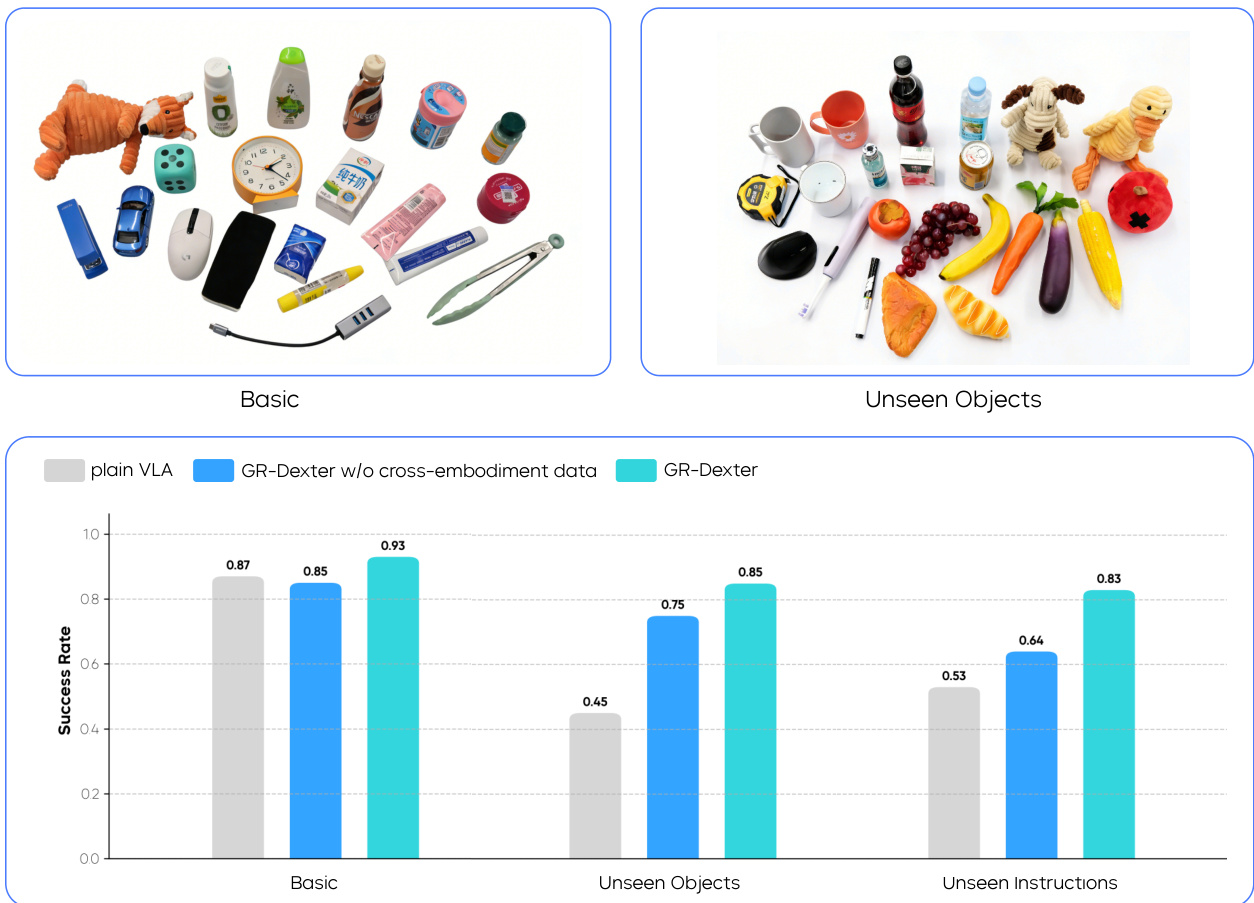
- In generalizable pick-and-place, GR-Dexter achieved 0.93 success rate in basic settings, outperforming plain VLA (0.87) and GR-Dexter without cross-embodiment data (0.85).
- On unseen objects and instructions, GR-Dexter achieved 0.85 and 0.83 success rates respectively, significantly outperforming baselines and validating robust generalization through curated vision-language and cross-embodiment data.
Results show that GR-Dexter achieves high success rates in both in-domain and out-of-distribution settings for long-horizon manipulation tasks. In the basic setting, GR-Dexter reaches a success rate of 0.97, matching the plain VLA baseline, while in the OOD setting with unseen layouts, GR-Dexter maintains a high success rate of 0.89 compared to the plain VLA's drop to 0.64, demonstrating improved generalization.

The authors evaluate GR-Dexter on a generalizable pick-and-place task, comparing its performance against a plain VLA baseline and a variant without cross-embodiment data. Results show that in the basic setting with seen objects, GR-Dexter achieves the highest success rate of 0.93, outperforming both baselines. In unseen object and unseen instruction settings, GR-Dexter maintains strong generalization with success rates of 0.85 and 0.83 respectively, demonstrating the effectiveness of cross-embodiment data in improving robustness.