Command Palette
Search for a command to run...
テキストから3D生成へのRL導入は、本当に準備ができているか? プログレッシブな検証
テキストから3D生成へのRL導入は、本当に準備ができているか? プログレッシブな検証
概要
強化学習(RL)は、かつて大規模言語モデルおよびマルチモーダルモデルにおいて有効であることが実証されており、最近では2次元画像生成への応用も成功裏に拡張されている。一方で、3次元生成へのRLの適用は、3次元オブジェクトが持つ高い空間的複雑性——特にグローバルな幾何構造の一貫性と細部レベルのテクスチャの精度——を要するため、依然としてほとんど未開拓の領域に留まっている。このため、3次元生成は報酬設計やRLアルゴリズムに対して極めて敏感である。こうした課題に対処するため、本研究ではテキストから3次元オブジェクトへの自己回帰的生成におけるRLの適用について、複数の次元にわたる包括的な初の系統的研究を実施した。(1)報酬設計:報酬の次元とモデル選択を評価し、人間の好みとの整合性が極めて重要であることを示した。また、汎用的なマルチモーダルモデルが3次元属性に対して堅牢な信号を提供することを確認した。(2)RLアルゴリズム:GRPOの変種を検討し、トークンレベルの最適化の有効性を強調するとともに、学習データ量および反復回数のスケーリング効果についても調査した。(3)テキストから3次元へのベンチマーク:既存のベンチマークは3次元生成モデルにおける内蔵された推論能力を適切に測定できていないため、本研究ではMME-3DRを提案した。(4)高度なRL枠組み:3次元生成の自然な階層構造に着目し、専用の報酬アンサンブルを用いてグローバルからローカルへと段階的に生成を最適化するHi-GRPOを提案した。これらの知見を基に、粗い形状からテクスチャの精緻化までを包括的に最適化する、初めてのRL強化型テキストから3次元生成モデルAR3D-R1を開発した。本研究が、3次元生成におけるRL駆動型推論の理解に貢献することを期待する。コードは https://github.com/Ivan-Tang-3D/3DGen-R1 にて公開されている。
One-sentence Summary
Researchers from Northwestern Polytechnical University, Peking University, and The Hong Kong University of Science and Technology propose AR3D-R1, the first reinforcement learning-enhanced text-to-3D autoregressive model, introducing Hi-GRPO for hierarchical global-to-local optimization and MME-3DR as a new benchmark, advancing 3D generation through improved reward design and token-level RL strategies.
Key Contributions
- The paper identifies key challenges in applying reinforcement learning (RL) to text-to-3D generation, such as sensitivity to reward design and algorithm choice due to 3D objects' geometric and textural complexity, and conducts the first systematic study of RL in this domain, evaluating reward models and RL algorithms within an autoregressive framework.
- It introduces MME-3DR, a new benchmark with 249 reasoning-intensive 3D generation cases across five challenging categories, and proposes Hi-GRPO, a hierarchical RL method that leverages dedicated reward ensembles to optimize global-to-local 3D structure and texture generation.
- Based on these insights, the authors develop AR3D-R1, the first RL-enhanced text-to-3D model, which achieves significant improvements over baseline methods on MME-3DR, demonstrating the effectiveness of token-level optimization and general multi-modal reward models in 3D generation.
Introduction
Reinforcement learning (RL) has proven effective in enhancing reasoning and generation in large language and 2D image models, but its application to text-to-3D generation remains underexplored due to the increased spatial complexity and need for globally consistent geometry and fine-grained textures in 3D objects. Prior work in 3D generation has largely relied on pre-training and fine-tuning, with limited exploration of RL-based optimization, while existing benchmarks fail to assess models’ implicit reasoning capabilities—such as spatial, physical, and abstract reasoning—leading to an overestimation of model performance. The authors conduct the first systematic investigation of RL in autoregressive text-to-3D generation, evaluating reward models, RL algorithms, and training dynamics, and introduce MME-3DR, a new benchmark targeting reasoning-intensive 3D generation tasks. They further propose Hi-GRPO, a hierarchical RL framework that optimizes coarse-to-fine 3D generation using dedicated reward ensembles, and develop AR3D-R1, the first RL-enhanced text-to-3D model, which achieves state-of-the-art performance by improving both structural coherence and texture fidelity.
Dataset
-
The authors use a combination of three primary 3D object datasets for training: Objaverse-XL, HSSD, and ABO, with evaluation performed on Toys4K.
-
Objaverse-XL serves as a large-scale source with over 10 million 3D objects collected from platforms like GitHub, Thingiverse, Sketchfab, and Polycam. It undergoes strict deduplication and rendering validation to ensure quality and diversity across categories and fine-grained attributes.
-
HSSD contributes approximately 18,656 real-world object models embedded in 211 high-quality synthetic indoor scenes. The dataset emphasizes realistic indoor layouts, semantic structure, and object relationships.
-
ABO provides around 8,000 high-quality 3D models of household items, drawn from nearly 147,000 product listings and 400,000 catalog images. These models include detailed material, geometric, and attribute annotations.
-
For evaluation, the authors use Toys4K, which contains about 4,000 3D object instances across 105 categories, offering diverse shapes and significant variation in form.
-
During training, prompts are sampled from Objaverse-XL, HSSD, and ABO, and the model is trained on a mixture of these sources without specified ratios. The base model is ShapeLLM-Omni, trained for 1,200 steps using 8 GPUs, a per-device batch size of 1, and gradient accumulation over 2 steps, resulting in an effective batch size of 16.
-
The training setup uses a learning rate of 1 × 10⁻⁶, a β value of 0.01, and a group size of 8. A configurable loss weight λ = 1.0 is applied to supervise global planning using final quality scores.
-
Reward models are served via the vLLM API framework, but no explicit cropping strategies, metadata construction methods, or additional preprocessing details are described in the provided text.
Method
The authors leverage a hierarchical reinforcement learning paradigm, Hi-GRPO, to decompose text-to-3D generation into two distinct, sequential stages: global geometric planning followed by local appearance refinement. This architecture explicitly models the coarse-to-fine nature of human 3D perception and enables targeted optimization at each level of detail.
In Step 1, the model receives the 3D textual prompt and a high-level semantic instruction to generate a concise semantic reasoning plan. This plan, represented as a sequence of semantic tokens {si,1,…,si,∣si∣}, serves to clarify object subcategories, establish spatial layouts of key components, and resolve ambiguous terms. As shown in the framework diagram, this semantic reasoning is then combined with the original prompt and a mesh start token to condition the 3D autoregressive model. The model generates a sequence of coarse 3D tokens {ti,1,…,ti,M}, which are decoded via a VQVAE decoder into a triangular mesh Mi(1). This initial output captures the global structure and basic color distribution, such as ensuring balanced proportions and a gradient of pink from center to outer petals for a flower.
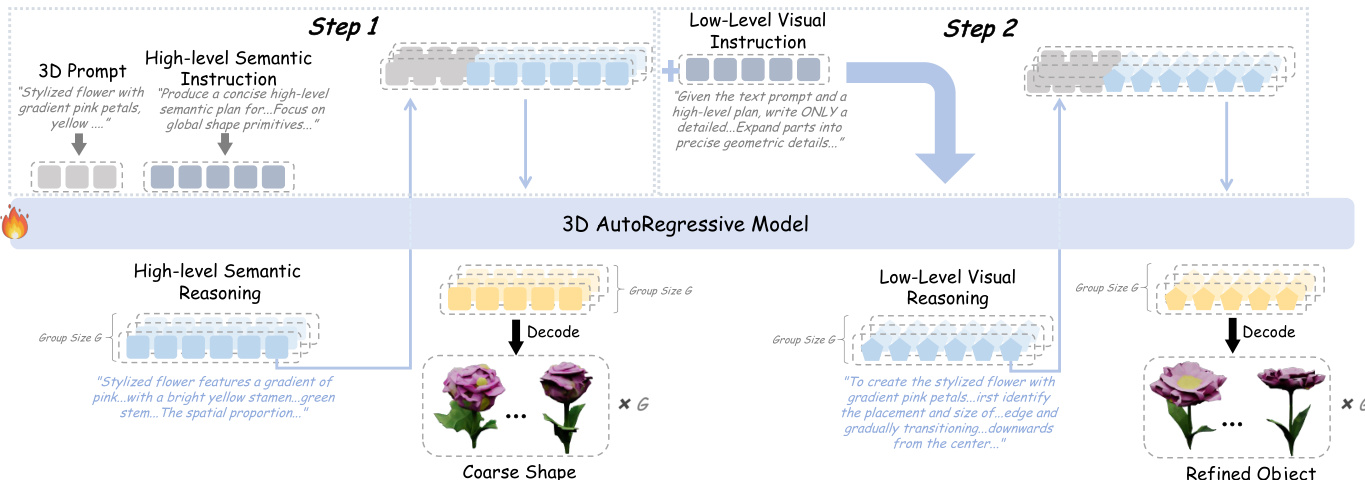
In Step 2, the model is conditioned on the original prompt, the previously generated high-level semantic reasoning, and a low-level visual instruction. It then generates a sequence of visual reasoning tokens {vi,1,…,vi,∣vi∣}, which focus on refining local appearance details. This includes specifying textures, interactions between components, and local attributes like element counts and symmetry. The model subsequently generates a second sequence of 3D tokens {oi,1,…,oi,M}, which are decoded into the final, refined mesh Mi(2). This step adds fine-grained details such as petal textures, stamen-petal spatial relations, and leaf counts, transforming the coarse shape into a high-fidelity 3D asset.
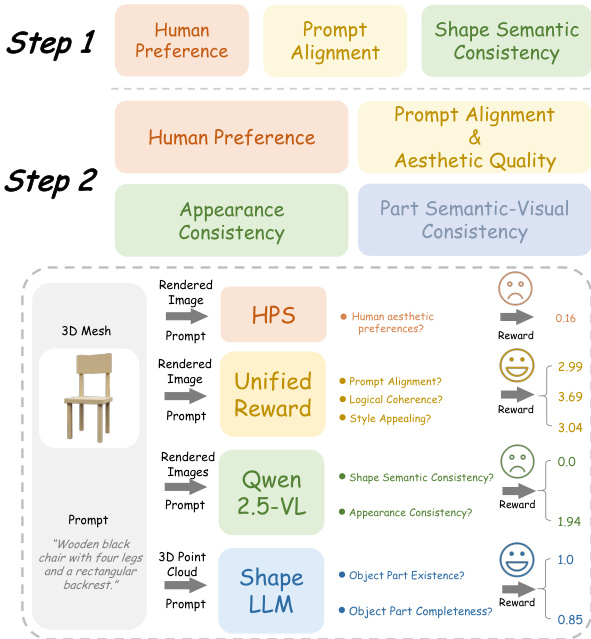
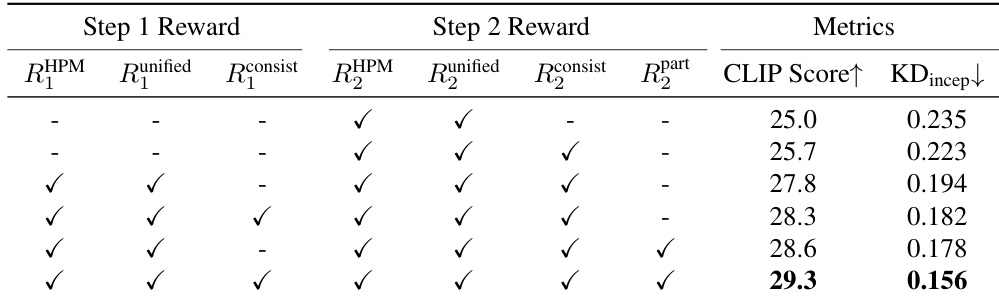
The training process employs a tailored reward ensemble for each step to guide the policy gradient optimization. As illustrated in the reward design figure, Step 1 rewards focus on global alignment, including human preference (HPS), prompt alignment (UnifiedReward), and geometric consistency (Qwen2.5-VL). Step 2 rewards emphasize local refinement, incorporating human preference, appearance quality (UnifiedReward-2.0), cross-view consistency (Qwen2.5-VL), and component completeness (ShapeLLM). Each reward is dimension-normalized to ensure balanced contribution. Critically, the reward from Step 2 is backpropagated to Step 1 via a configurable weight λ, allowing the final output quality to supervise the initial global planning. The total loss is the sum of independent policy losses computed for each step, using a clipped surrogate objective with asymmetric clipping thresholds to promote exploration and prevent entropy collapse.
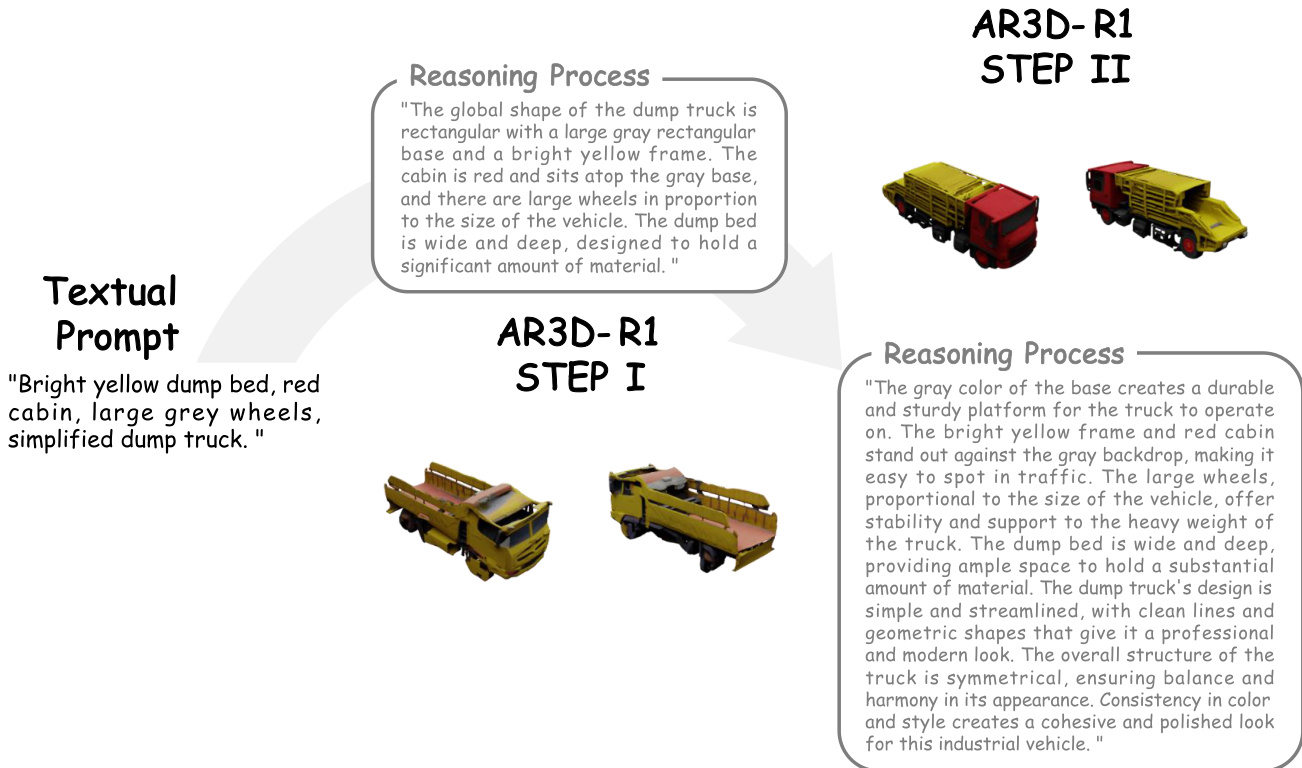
The model’s output during inference follows this same two-step progression. As shown in the qualitative results, the first step produces a basic, geometrically consistent shape, while the second step refines it with detailed textures, colors, and part structures, resulting in a final mesh that closely aligns with the prompt’s specifications.
Experiment
Respond strictly in English.
The authors use a hierarchical reward system across two generation steps, combining human preference, unified aesthetic, 3D consistency, and part-level rewards. Results show that including step-specific rewards—especially part-level guidance in Step 2—yields the highest CLIP Score and lowest KD_incep, indicating improved semantic alignment and structural fidelity. Omitting any component, particularly step-specific or part-level rewards, leads to measurable performance degradation.
The authors use textual reasoning as a prior step before 3D token generation, finding that this approach improves CLIP Score from 22.7 in the base model to 24.0 when reasoning is included, outperforming direct generation without reasoning (23.4). Results show that incorporating reasoning enhances the model’s ability to plan semantically coherent 3D outputs.

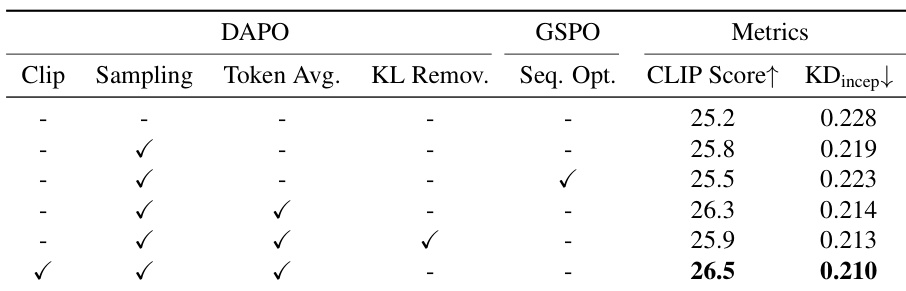
Results show that combining Dynamic Sampling, Token-level Loss Aggregation, and Decoupled Clip in DAPO yields the highest CLIP Score of 26.5 and lowest KD_incep of 0.210, outperforming both vanilla GRPO and GSPO variants. Token-level strategies consistently improve performance over sequence-level optimization, while retaining the KL penalty stabilizes training and prevents degradation.
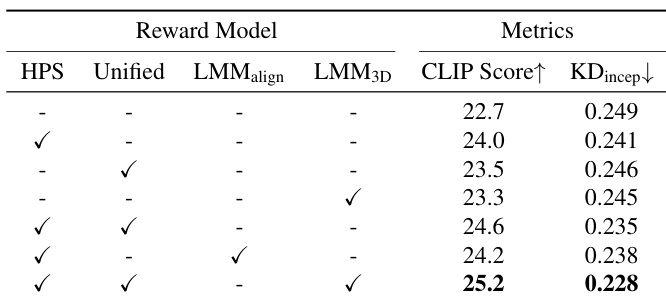
The authors use a combination of human preference (HPS), UnifiedReward, and LMM-based 3D consistency rewards to optimize 3D autoregressive generation via GRPO. Results show that combining all three reward signals yields the highest CLIP Score (25.2) and lowest KD_incep (0.228), outperforming any single or partial combination. HPS alone provides the strongest baseline improvement, while LMM_3D adds unique value in enhancing cross-view structural coherence.
Results show that AR3D-R1 outperforms prior methods across both MME-3DR and Toys4K benchmarks, achieving the highest CLIP scores and lowest KD and FD metrics. The model demonstrates superior text-to-3D alignment and structural coherence, particularly in complex object categories. These gains stem from its hierarchical RL framework combining step-specific rewards and textual reasoning guidance.