Command Palette
Search for a command to run...
アービトラージ:アドバンテージ認識型予測を活用した効率的な推論
アービトラージ:アドバンテージ認識型予測を活用した効率的な推論
概要
現代の大規模言語モデルは、長い思考過程(Chain of Thoughts)を用いることで驚異的な推論能力を達成しているが、推論時に大きな計算コストを伴うため、性能とコストのバランスを改善するための技術が求められている。そのような技術の一つとして、推測的デコード(Speculative Decoding) がある。これは、高速だが精度の低い「ドラフトモデル」を用いて逐次的にトークンを提案し、その後、より強力な「ターゲットモデル」によって並列的に検証することで、推論を加速する手法である。しかし、意味的に同等のステップにおいてトークンの不一致が発生することで不要な拒否が生じるため、従来のトークンレベルの推測的デコードは推論タスクにおいて課題を抱えている。近年、この問題を克服するために、ステップレベルの意味的検証に移行する研究が進んでいる。これにより、一連の推論ステップ全体を受容または拒否することで効率性が向上している。しかし、既存のステップレベル手法でも、拒否されたステップを何度も再生成するケースが多く、ターゲットモデルの計算リソースが無駄に消費されているのが現状である。本研究では、この課題に対処するため、ドラフトモデルとターゲットモデルの相対的な優位性に基づいて生成プロセスを動的にルーティングする新しいステップレベル推測生成フレームワーク「Arbitrage」を提案する。固定の受容閾値を適用する従来手法とは異なり、Arbitrageは、ターゲットモデルが有意に優れたステップを生成する可能性が高いタイミングを予測できる軽量なルーターを学習させることで、動的な生成ルーティングを実現する。このルーティングは、常により高品質なステップを選択する理想の「アービトラージオラクル」を近似的に再現し、効率性と精度の最適なトレードオフを達成する。複数の数学的推論ベンチマークにおける実験結果から、Arbitrageは従来のステップレベル推測的デコード手法を一貫して上回り、精度を維持したまま推論遅延を最大で約2倍まで削減することに成功した。
One-sentence Summary
UC Berkeley, Apple, ICSI, and LBNL propose ARBITRAGE, a step-level speculative decoding framework that uses a lightweight router to dynamically select higher-quality reasoning steps between draft and target models, improving efficiency by reducing wasteful regeneration and cutting inference latency by up to 2× on mathematical reasoning tasks compared to prior methods.
Key Contributions
- Existing step-level speculative decoding methods often waste computation by regenerating reasoning steps that yield little quality improvement, as their fixed acceptance thresholds do not account for the relative performance of draft and target models.
- ARBITRAGE introduces a dynamic routing mechanism that uses a lightweight router to predict when the target model is likely to produce a meaningfully better reasoning step, enabling more efficient use of target model compute.
- Evaluated on multiple mathematical reasoning benchmarks, ARBITRAGE reduces inference latency by up to ~2× compared to prior step-level methods while maintaining or improving output accuracy.
Introduction
Large language models (LLMs) achieve strong performance on complex reasoning tasks using long chain-of-thought (CoT) generation, but the auto-regressive nature of token decoding creates a memory-bound inference bottleneck, especially for lengthy reasoning sequences. Speculative Decoding (SD) addresses this by using a fast draft model to propose tokens or steps, which a more capable target model verifies in parallel, thereby improving throughput. While step-level SD—verifying entire reasoning steps instead of individual tokens—improves acceptance rates and robustness, existing methods like Reward-guided SD (RSD) rely on absolute quality thresholds to decide when to regenerate with the target model, leading to frequent and often unnecessary regenerations that waste compute without meaningful quality gains.
The authors leverage a key insight: routing decisions should depend not on the draft’s absolute quality, but on the expected advantage of the target model over the draft for a given step. They propose ARBITRAGE, a step-level speculative generation framework that introduces a lightweight router trained to predict when the target model is likely to produce a meaningfully better reasoning step than the draft. This router approximates an ideal ARBITRAGE ORACLE that always selects the higher-quality step, enabling dynamic, advantage-based routing. By avoiding costly target regenerations when gains are marginal, ARBITRAGE reduces redundant computation and improves the efficiency-accuracy trade-off. Experiments show up to ~2× latency reduction over prior step-level SD methods at matched accuracy across mathematical reasoning benchmarks.
Dataset
-
The authors use a step-level dataset constructed from the NuminaMath-CoT dataset, from which 30,000 questions are selected via stratified sampling to serve as the seed for fine-tuning.
-
For each question context x, the draft and target models are decoded from the same prefix to generate paired reasoning steps (z_d, z_t). The authors compute PRM scores s_d and s_t using a fixed PRM model, then calculate the step-level advantage Δ and derive the oracle label γ = I[Δ > 0], indicating whether using the target model improves output quality.
-
To reduce variance in the oracle signal, multiple target samples may be drawn per context; their PRM scores are averaged to produce \bar{s}_t and \bar{Δ}, from which the final oracle label y is computed.
-
The resulting training tuples (x, z_d, z_t, s_d, s_t, Δ, y) form a supervised dataset for training the router model.
-
Due to class imbalance—where most draft steps are acceptable (y = 0)—the authors apply random downsampling to the majority class (y = 0) to balance the dataset and mitigate bias toward accepting draft steps.
-
Additional preprocessing includes annotating each step with the model that generated it, normalizing sequence lengths, and standardizing the step separator token to \n\n to ensure consistency between PRM scoring and router inputs.
Method
The authors leverage a step-level speculative decoding framework called ARBITRAGE, which dynamically routes between a lightweight draft model and a more powerful target model based on predicted quality advantage. Unlike classical speculative decoding that relies on absolute reward thresholds from a Process Reward Model (PRM), ARBITRAGE introduces a lightweight router that estimates whether regenerating a step with the target model will yield a higher PRM score than the draft’s output — thereby avoiding wasteful target invocations.
At each reasoning step, the draft model generates a candidate step zd conditioned on the current context x, terminating upon emitting a separator token. This step is then evaluated by the ARBITRAGE ROUTER, which outputs a scalar y^=hθrouter(x,zd) representing the predicted likelihood that the target model’s step zt would outperform zd under the PRM. The decision to accept or escalate is governed by a tunable threshold τ: if y^≤τ, the draft step is accepted; otherwise, the target model regenerates the step from the same prefix.
Refer to the framework diagram, which illustrates the two possible execution paths: in Step 1, the router predicts no advantage from escalation (y^<τ), so the draft step is accepted and the system proceeds; in Step 2, the router predicts a meaningful advantage (y^>τ), triggering target regeneration before proceeding.
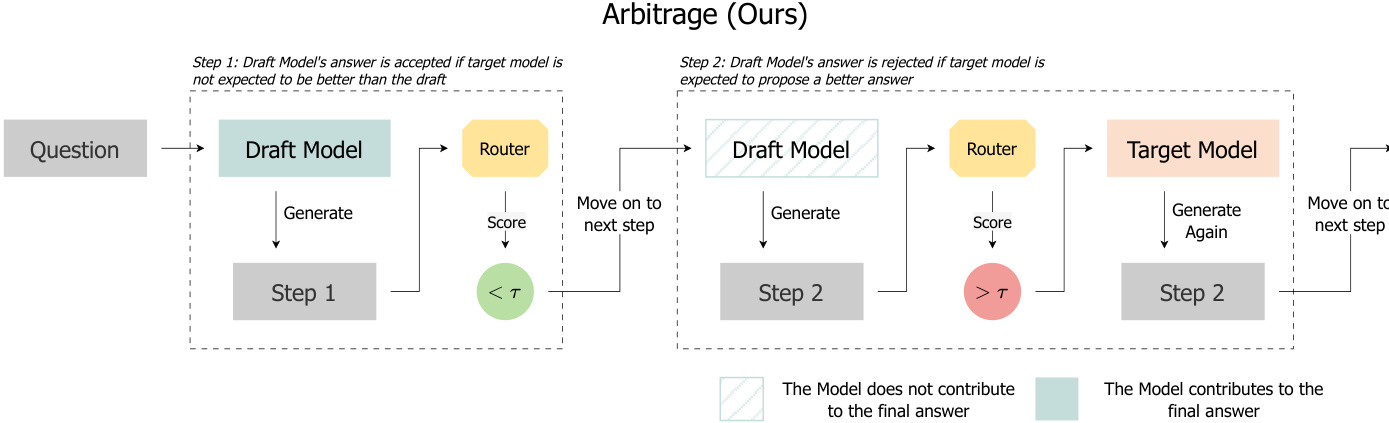
The router is trained offline to approximate the ARBITRAGE ORACLE — a theoretically optimal but computationally infeasible policy that compares the counterfactual PRM scores sd and st for the same context. The oracle selects the step with higher reward: z∗=argmaxz∈{zd,zt}hθPRM(x,z). The advantage Δ=st−sd quantifies the target’s potential gain over the draft. The oracle’s optimal routing policy is aτ∗=I{Δ>τ}, which maximizes expected quality under a fixed escalation budget.
As shown in the figure below, ARBITRAGE avoids the “wasted regeneration” problem inherent in RSD: under RSD, Step 3 and Step 4 are regenerated despite yielding lower or equal PRM scores than their draft counterparts, whereas ARBITRAGE only regenerates Step 3 — where the predicted advantage is positive — and accepts Step 4 without regeneration, since the router predicts no improvement.

The router’s prediction enables fine-grained control over the compute-quality trade-off via τ, while introducing only a single forward pass per step. This design preserves the efficiency of speculative decoding while significantly reducing redundant computation, as the router approximates the oracle’s advantage-aware decisions without executing the target model during inference.
Experiment
- Empirical analysis shows RSD incurs up to 40% wasted target model calls at 70% deferral rate, with no quality gain due to regeneration on low-scoring but correct draft steps or shared draft-target failure modes.
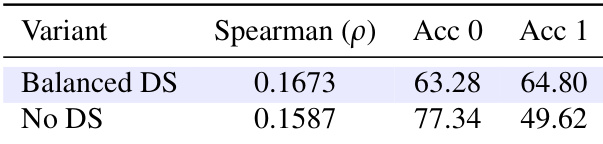
- ARBITRAGE ROUTER is trained using a 1.5B PRM checkpoint with step-level annotations and class-balanced downsampling, achieving higher Spearman correlation (ρ = 0.1673) and balanced accuracy by addressing label imbalance.
- On MATH500 and OlympiadBench, ARBITRAGE ROUTER outperforms RSD across LLaMA3 (1B/8B), LLaMA3 (8B/70B), and Qwen2.5-Math (3bit-7B/7B), achieving higher accuracy at comparable acceptance rates, closely tracking the oracle.
- Ablations confirm binary classification with step annotations yields best performance: it improves Spearman correlation and label-1 accuracy over non-annotated and multi-class variants.
- ARBITRAGE achieves up to 1.62× lower latency on MATH500 and up to 1.97× speedup on OlympiadBench at matched accuracy, demonstrating superior compute-quality trade-off by reducing unnecessary target model invocations.
The authors evaluate the impact of incorporating historical routing context into the ARBITRAGE router, finding that annotated inputs—which include prior model choices—improve both Spearman correlation and accuracy for escalation decisions. Results show that the annotated variant achieves higher correlation (0.1508 vs. 0.1305) and better label-1 accuracy (72.96% vs. 69.58%), indicating that routing history enhances the model’s ability to identify steps where target escalation is beneficial.

The authors evaluate different label granularities for the ARBITRAGE router and find that the 2-class classification variant achieves the highest Spearman correlation with oracle advantage scores and balanced accuracy across both classes. Increasing the number of classes to 4 or 10 reduces overall correlation and introduces label skew, indicating that binary routing provides the most robust trade-off for practical deployment.

The authors evaluate the impact of class-balanced downsampling on router training, finding that balancing the dataset improves Spearman correlation and label-1 accuracy while reducing bias toward the majority accept class. Without downsampling, the router becomes overconfident in accepting draft steps, leading to under-escalation and worse overall routing quality.