Command Palette
Search for a command to run...
Surfer-H が Holo1 と融合:オープンウェイトで駆動されるコスト効率の高いWebエージェント
Surfer-H が Holo1 と融合:オープンウェイトで駆動されるコスト効率の高いWebエージェント
概要
我々は、ユーザー定義のタスクをウェブ上で実行できるコスト効率の高いウェブエージェント「Surfer-H」を提案する。このエージェントは、視覚言語モデル(VLM)を統合しており、特にウェブナビゲーションおよび情報抽出に特化した新しいオープンウェイトモデル「Holo1」と連携している。Holo1は、オープンアクセスのウェブコンテンツや合成データ、および自律的なエージェントによって生成されたデータを厳選したデータソースに基づいて学習されている。Holo1は、一般的なユーザーインターフェース(UI)ベンチマークおよび我々が新たに提案したウェブUIローカライゼーションベンチマーク「WebClick」において、トップ性能を達成している。Holo1を搭載したSurfer-Hは、WebVoyagerベンチマークにおいて92.2%という最先端の精度を実現し、正確性とコスト効率の間にパレート最適なバランスを実現している。自律型システム分野における研究の加速を目的として、本研究では「WebClick」評価データセットおよびHolo1のモデル重みをオープンソースとして公開する。
One-sentence Summary
The authors propose Surfer-H, a cost-efficient web agent leveraging Holo1—a newly open-weight Vision-Language Model trained on curated web and synthetic data—for accurate, scalable web navigation and information extraction, achieving state-of-the-art 92.2% accuracy on WebVoyager while enabling faster research through open-sourced datasets and model weights.
Key Contributions
-
Surfer-H is a cost-efficient web agent that enables user-defined web tasks through visual interaction, leveraging Vision-Language Models (VLMs) without relying on DOM or accessibility trees, and operates via a modular architecture combining a policy, localizer, and validator for real-time, human-like web navigation.
-
The authors introduce Holo1, a family of open-weight VLMs trained on curated data—including open web content, synthetic examples, and self-produced agentic data—that achieve state-of-the-art performance on both general UI benchmarks and the new WebClick benchmark, specifically designed for web-specific UI localization challenges like dynamic calendars and nested menus.
-
When integrated with Holo1, Surfer-H attains a 92.2% success rate on the WebVoyager benchmark, setting a new state-of-the-art result while maintaining a Pareto-optimal trade-off between accuracy and cost-efficiency, with both the Holo1 model weights and the WebClick dataset openly released to accelerate research in agentic systems.
Introduction
The authors leverage large vision-language models (VLMs) to build Surfer-H, a cost-efficient web agent that interacts with websites through visual interfaces rather than relying on APIs or DOM access. This approach is critical for creating general-purpose agents capable of real-world web tasks—like booking reservations or retrieving up-to-date information—without requiring custom integrations. Prior work on LLM-based agents has been limited by dependence on predefined tools and high engineering overhead, while GUI-based agents have struggled with accurate UI localization, especially on complex, dynamic web elements. To address this, the authors introduce Holo1, a family of lightweight VLMs trained on curated web data—including synthetic and agentic interactions—to excel at action execution and UI localization. They further propose WebClick, a new benchmark tailored to web-specific UI challenges, demonstrating that Holo1 achieves state-of-the-art performance on web retrieval tasks with superior cost-efficiency.
Dataset
-
The training dataset for Surfer-H is a large-scale mixture of diverse data sources designed to enable deep web understanding and precise state-to-action mapping across varied interfaces. It combines real-world web pages, synthetic UIs, document visualizations, and agent-generated behavioral traces, forming a comprehensive foundation for generalization.
-
The dataset is composed of three main components:
- GUI Grounding (50.79% of tokens): Built from web-crawled pages and proprietary synthetic data, this core component includes 89 million clicks from 4 million real web pages, with intent labels generated via frontier models. It is augmented with custom synthetic websites (e.g., calendars), relational tables, and icon-focused datasets to address known model weaknesses.
- Complex Visual Understanding (32.28% of tokens): Includes 5 million coordinate validation triplets for intent-to-location alignment, nearly 7 million pages for exhaustive UI element extraction (clickable, selectable, inputtable), and 300,000 images from public and internal VQA datasets focused on charts, dashboards, tables, and dense reports, totaling 150M tokens.
- Behavior Learning on Multimodal Traces (16.93% of tokens): Derived from agent execution traces, this includes 15.48% from successful agent trajectories (FBC-filtered) and 1.45% from evaluation of agent answers against task evidence. Trajectories come from two corpora: WebVoyager (643 tasks on 15 sites) and WebVoyagerExtended (15,000 tasks across 330 sites), with synthetic task generation to boost diversity.
-
The data is processed to support multimodal reasoning: each training sample includes a screenshot, intent, and precise interaction coordinates. For UI extraction, models are trained to identify interactable elements using visual affordances beyond OCR. Coordinate validation data uses a Set-of-Marks approach to assess grounding accuracy. Agent traces are structured as sequences of (thought, notes, action) pairs, conditioned on past observations and actions, enabling memory-aware policy learning.
-
The model is trained using a mixture of these datasets with token-based weighting reflecting their contribution. The training split leverages the full mixture, with synthetic and real data balanced to enhance robustness. The WebClick benchmark, derived from agent and human interactions (including calendar-specific tasks), is used to evaluate localization performance and track progress on real-world web interaction challenges.
Method
The authors leverage a modular architecture for Surfer-H, a web agent designed to perform user-defined tasks through interaction with web interfaces. The system operates through a cycle of perception, decision-making, and action execution, with three primary trainable components: a policy, a localizer, and a validator. As shown in the figure below, the agent begins by receiving a task, which is stored in its internal memory alongside recent screenshots, thoughts, notes, and the current browser state. The policy, a vision-language model (VLM), processes this memory to generate a thought and select the next action from a limited action space, which includes clicking, typing, scrolling, waiting, refreshing, navigating to a URL, or returning an answer. When an action requires interaction with a specific element on the webpage, such as a button or input field, the policy provides a textual description of the target. The localizer then processes this description and the current screenshot to determine the precise 2D coordinates of the element, enabling accurate execution of click or write actions. The action is then executed in the browser, and the resulting state is captured as a new screenshot, which is added to the memory for subsequent steps.
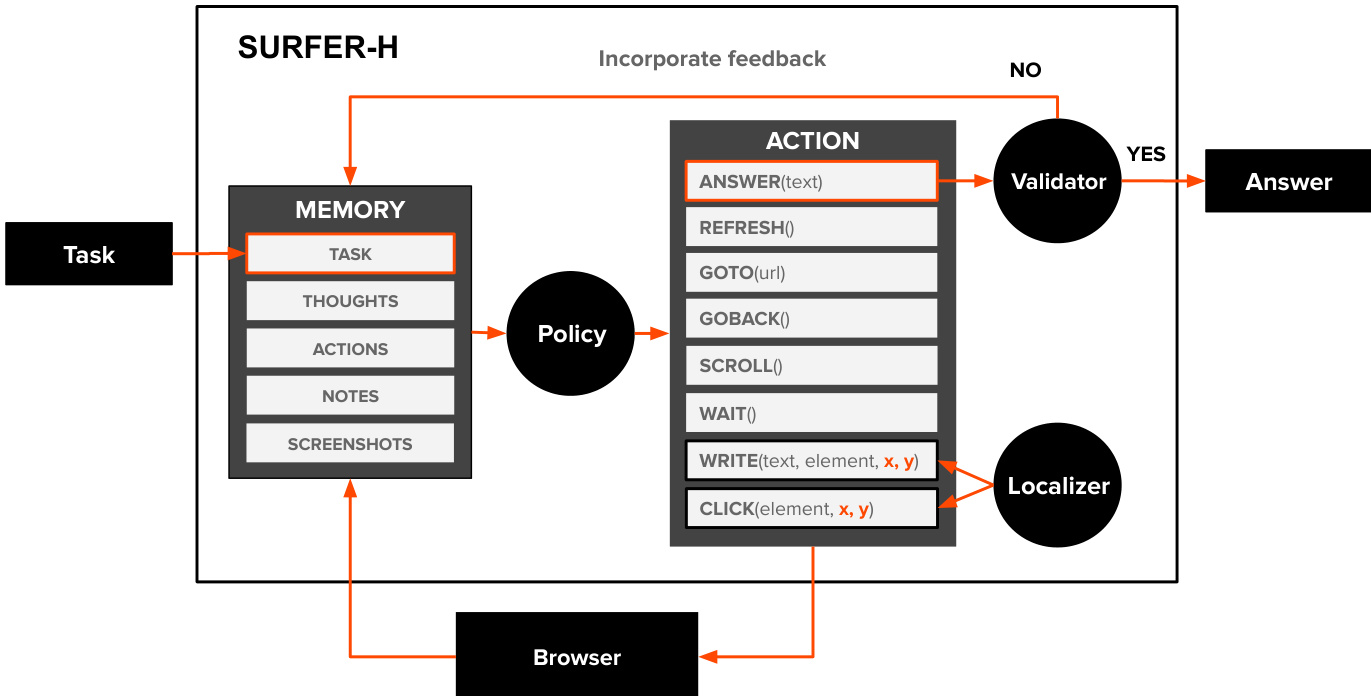
If the policy decides the task is complete, it generates an answer via the ANSWER action. This answer is then passed to the validator, another VLM component, which evaluates the correctness of the answer based on the task description and a set of supporting screenshots from the recent trajectory. The validator outputs a boolean indicating success and a natural language explanation justifying the decision. If the answer is validated, the agent terminates and returns the answer to the user. Otherwise, the feedback is incorporated into the agent's memory, and the agent continues its execution. The agent operates under a step limit, ensuring termination even if the task is not completed. The policy, localizer, and validator can be implemented using either generalist foundation models or specialized models, with the authors introducing Holo1, a new open-weight collection of VLMs trained specifically for web navigation and information extraction, to power these modules.
Experiment
- Evaluated Holo1 models on localization benchmarks including Screenspot, Screenspot-V2, Screenspot-Pro, GroundUI-Web, and WebClick; Holo1-3B and Holo1-7B achieve state-of-the-art average localization performance at their respective scales, scoring 73.55% and 76.16%, outperforming Qwen2.5-VL-3B, UGround-V1-2B, UI-TARS-2B, and even surpassing Qwen2.5-VL-7B by 4.23 percentage points.
- Holo1-7B exceeds UGround-V1-7B on two Screenspot benchmarks and two WebClick datasets, and achieves the highest average score of 76.19% despite a slight drop on GroundUI-Web (78.50%).
- In the WebVoyager benchmark, Surfer-H powered by Holo1-7B reaches 92.2% success after 10 attempts, matching GPT-4.1 performance (92.0%) at a significantly lower cost of 0.13/taskversus0.54/task.
- Holo1-3B and Holo1-7B outperform external baselines BrowserUse, Project Mariner, and OpenAI Operator after 5 attempts, matching BrowserUse’s performance after 10 attempts.
- Using Holo1 as the validator reduces cost but drops performance by 12–16 percentage points, indicating validation is more demanding than policy or localization tasks.
- Holo1-7B trained on in-domain WebVoyagerExtended data (Holo1-7B-WVE) achieves a 9.5 percentage point improvement over Qwen2.5-VL-7B-Instruct and a 4.5 point gain over Holo1-7B, demonstrating the benefit of targeted fine-tuning and cross-domain exploration.
The authors use the WebVoyager benchmark to evaluate Surfer-H with various policy and validator modules, showing that Holo1-based agents achieve high accuracy at significantly lower cost compared to GPT-4. Results show that Surfer-H powered by Holo1-7B reaches 92.2% accuracy after 10 attempts at a cost of $0.13 per task, outperforming GPT-4.1 while being much more cost-efficient.
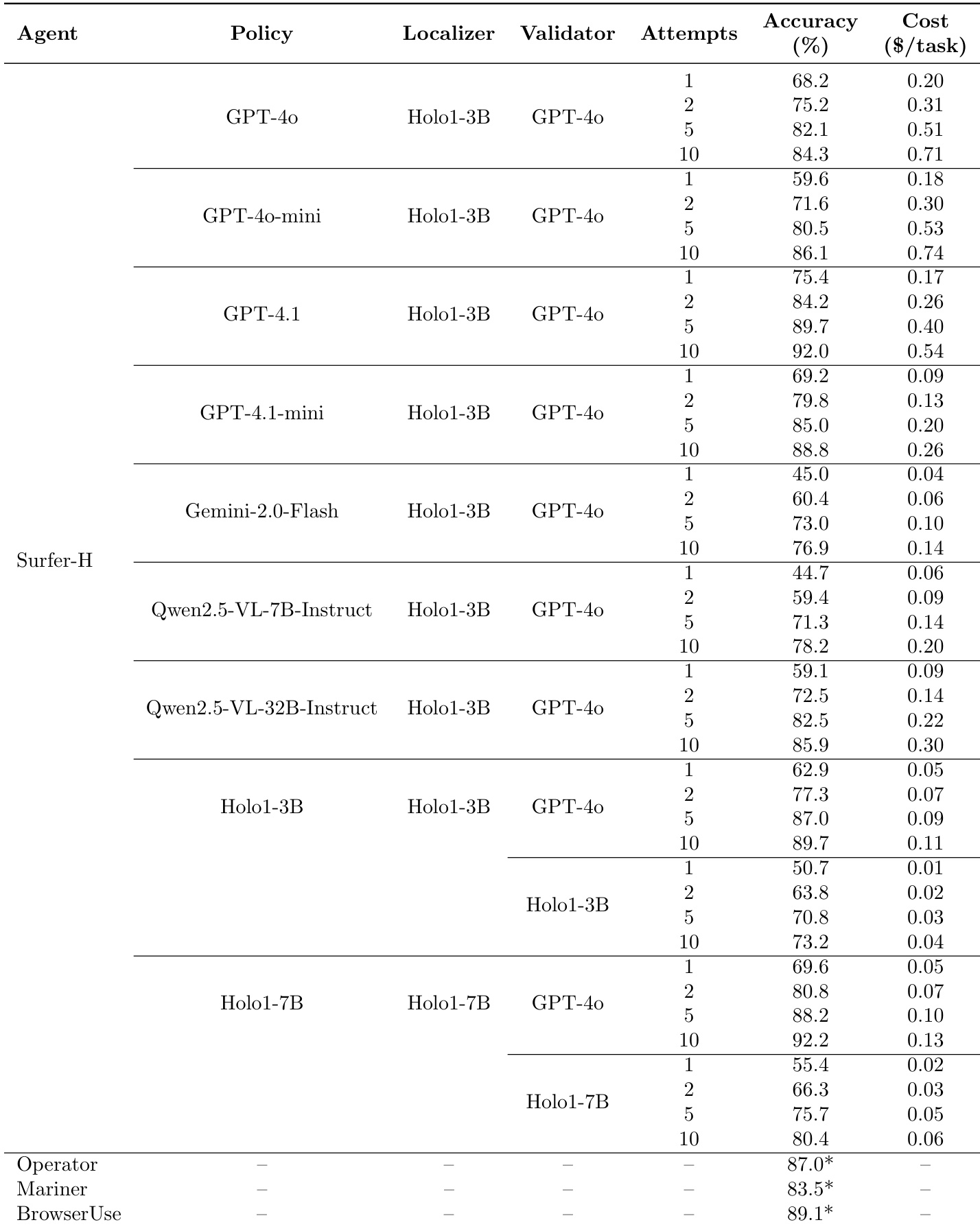
The authors use the table to compare the localization performance of their Holo1 models against state-of-the-art models across multiple benchmarks. Results show that Holo1-3B achieves the highest average score of 73.55% among 2B and 3B models, outperforming Qwen2.5-VL-3B and UGround-V1-2B, while Holo1-7B achieves the highest average score of 76.19%, surpassing UGround-V1-7B on most benchmarks despite a slight drop on GroundUI.
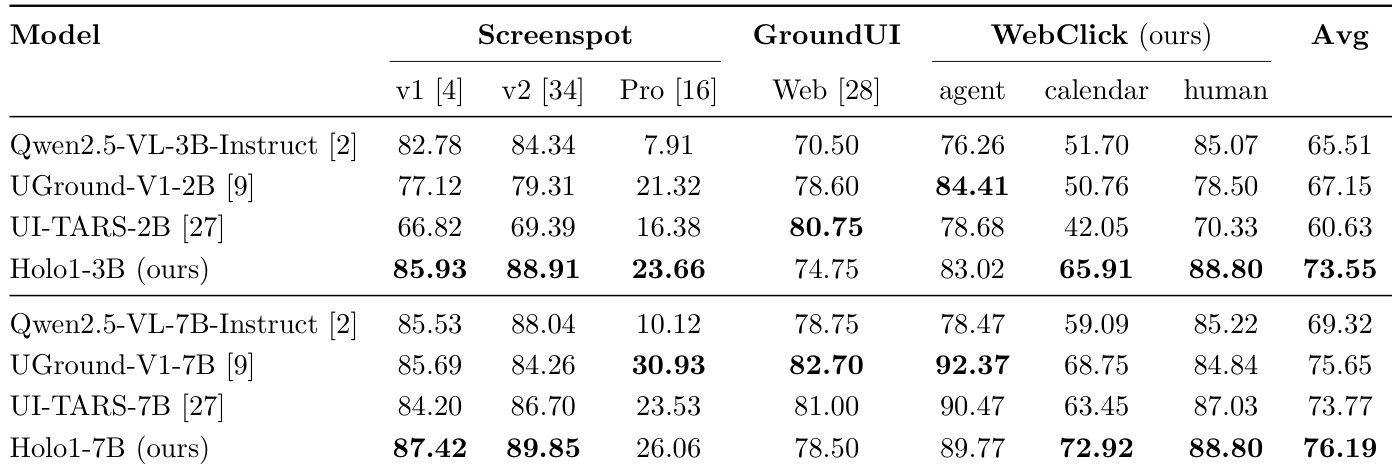
The authors use the table to detail the composition of their training mixture, showing that GUI Grounding constitutes the largest portion at 50.79%, primarily driven by WebCrawl data. The mixture also includes significant contributions from Complex Visual Understanding (32.28%) and Behavior Learning (16.93%), with Policy being the dominant component in Behavior Learning.
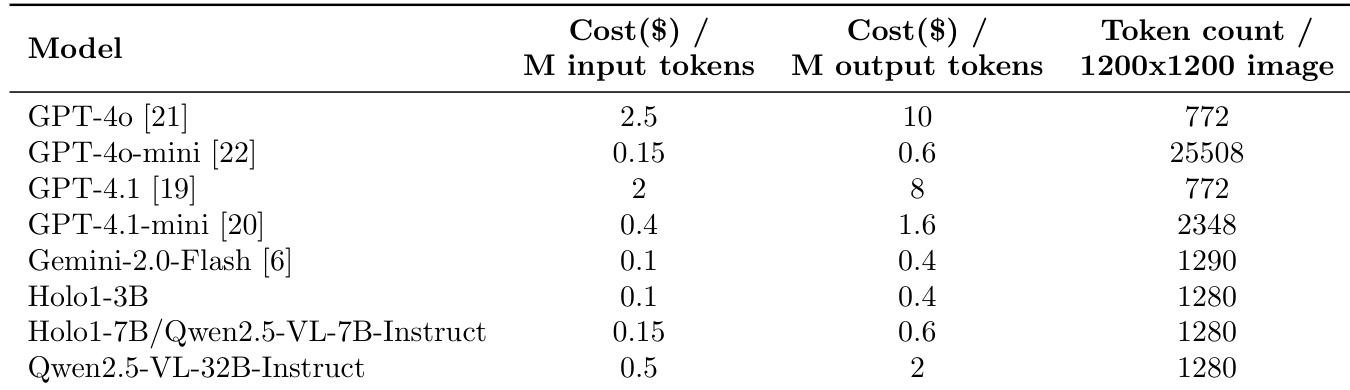
The authors use the provided table to compare the inference costs of various models, showing that Holo1-3B and Holo1-7B/Qwen2.5-VL-7B-Instruct have low input and output token costs, with Holo1-3B costing 0.1 dollars per million input tokens and 0.4 dollars per million output tokens. Results show that Holo1-3B and Holo1-7B/Qwen2.5-VL-7B-Instruct are among the most cost-efficient models, with similar token counts per 1200x1200 image as other models, indicating efficient processing for visual tasks.
The authors use the WebVoyager benchmark to evaluate Surfer-H with different policy training tasks and modules, showing that Holo1-7B achieves the highest WebVoyager accuracy at 92.2% when trained on both WebVoyager and WebVoyagerExtended data. This performance surpasses the Qwen2.5-VL-7B-Instruct baseline by 14 percentage points and demonstrates the benefit of combining in-domain and cross-domain training for improved agent performance.
