Command Palette
Search for a command to run...
ピクセルリゾナー:好奇心駆動型強化学習を用いたピクセル空間における推論の促進
ピクセルリゾナー:好奇心駆動型強化学習を用いたピクセル空間における推論の促進
Su Alex Wang Haozhe Ren Weimin Lin Fangzhen Chen Wenhu
概要
思考過程(Chain-of-thought)推論は、さまざまな分野において大規模言語モデル(LLM)の性能を顕著に向上させた。しかし、この推論プロセスはこれまでテキスト空間に限定されており、視覚情報に富むタスクではその効果が制限されていた。この課題を克服するため、本研究では「ピクセル空間における推論」という新概念を導入する。本フレームワークでは、視覚言語モデル(VLM)にズームインやフレーム選択といった視覚的推論操作のセットを搭載する。これらの操作により、VLMは視覚的証拠を直接観察・質問・推論する能力を獲得し、視覚タスクにおける推論の正確性が向上する。VLMにこのようなピクセル空間推論能力を育成することは、モデルの初期段階での能力の不均衡や、新導入のピクセル空間操作への採用抵抗といった顕著な課題を伴う。本研究では、これらを克服するための二段階訓練アプローチを提案する。第一段階では、合成された推論トレースを用いたインストラクションチューニングにより、モデルが新しい視覚操作に慣れ親しむようにする。第二段階では、好奇心駆動の報酬機構を用いた強化学習(RL)を導入し、ピクセル空間推論とテキスト推論の間で探索のバランスを取る。これにより、VLMは情報量の多い画像や動画といった複雑な視覚入力と対話し、必要情報を能動的に収集できるようになる。本手法が、多様な視覚推論ベンチマークにおいてVLMの性能を顕著に向上させることを実証した。本研究で開発した7Bパラメータのモデルは、V*ベンチで84%、TallyQA-Complexで74%、InfographicsVQAで84%の精度を達成し、現時点で公開されているモデルの中でも最高の性能を記録した。これらの結果は、ピクセル空間推論の重要性と、本フレームワークの有効性を示している。
One-sentence Summary
The authors from the University of Waterloo, Hong Kong University of Science and Technology, University of Science and Technology of China, and Vector Institute propose Pixel-Reasoner, a 7B Vision-Language Model that introduces pixel-space reasoning via visual operations like zoom-in and select-frame, enabling direct interaction with visual inputs; through a two-phase training approach combining instruction tuning and curiosity-driven reinforcement learning, the model achieves state-of-the-art open-source performance on visual reasoning benchmarks, demonstrating enhanced fidelity in complex visual tasks.
Key Contributions
- This work introduces pixel-space reasoning for Vision-Language Models (VLMs), enabling direct visual interaction through operations like zoom-in and select-frame, which addresses the limitation of purely textual chain-of-thought reasoning in visually intensive tasks.
- The authors propose a two-phase training framework combining instruction tuning on synthesized reasoning traces and curiosity-driven reinforcement learning to overcome challenges in adopting pixel-space operations and balancing exploration between visual and textual reasoning.
- The resulting 7B model, Pixel-Reasoner, achieves state-of-the-art performance on multiple visual reasoning benchmarks, including 84% on V* bench, 74% on TallyQA-Complex, and 84% on InfographicsVQA, demonstrating the effectiveness of the proposed framework.
Introduction
The authors address a key limitation in current Vision-Language Models (VLMs), which rely exclusively on textual reasoning steps and lack direct interaction with visual inputs during complex tasks. This restricts their ability to capture fine-grained visual details such as small objects, subtle spatial relationships, or embedded text in images and videos. To overcome this, they introduce Pixel Reasoner, a framework that enables VLMs to perform pixel-space reasoning through visual operations like zooming and frame selection. The approach combines warm-start instruction tuning with curiosity-driven reinforcement learning to incentivize meaningful visual exploration, allowing models to iteratively refine their understanding of images and videos. This represents a significant shift from text-only reasoning, enabling deeper, more accurate visual analysis while maintaining compatibility with existing VLM architectures.
Dataset
-
The dataset is composed of three seed datasets: SA1B, FineWeb, and STARQA, selected for their high visual complexity and explicit annotations that enable fine-grained visual analysis. SA1B provides high-resolution natural scenes with detailed segmentation masks; FineWeb offers webpage screenshots with QA pairs and precise bounding box annotations for answer regions; STARQA supplies video data with QA pairs and annotated temporal windows for relevant visual content.
-
Each dataset contributes distinct modalities: SA1B supports image-level fine-grained reasoning, FineWeb enables spatially precise visual queries, and STARQA facilitates temporal reasoning over video sequences. The authors use GPT-4o to extract or generate fine-grained vision-language queries that require localization of specific visual cues, especially for SA1B, where queries are synthesized based on identified image details.
-
Expert trajectories are synthesized using a template-based method to ensure proper integration of visual operations. The template structures reasoning as: (1) global analysis of the full input, (2) execution of a visual operation (crop or select frames), (3) detailed analysis of the resulting visual cue, and (4) final answer. This ensures that visual operations are necessary and not bypassed.
-
Two types of trajectories are generated: single-pass trajectories, where the correct visual cue is used directly, and error-induced self-correction trajectories, which insert incorrect or misleading visual operations (e.g., unrelated frames, oversized bounding boxes) before the correct cue to simulate error recovery.
-
The self-correction trajectory types include: Recrop once (one incorrect bounding box), Recrop twice (two incorrect bounding boxes), Further zoom-in (overly large bounding box containing the correct cue), and Reselect (incorrect frame selection). These are proportionally distributed as detailed in Table 2.
-
Visual operations are limited to two types: CropImage, which takes a 2D bounding box and target image index to zoom into a region, and SelectFrames, which selects up to 8 frames from a 16-frame video sequence.
-
During training, the authors use a mixture of single-pass, self-correction, and purely textual reasoning trajectories to allow the model to learn when to apply pixel-space reasoning. A loss mask is applied to tokens representing erroneous visual operations in self-correction trajectories to prevent the model from learning incorrect actions.
-
The data pipeline, illustrated in Figure 8, involves feeding the full high-resolution image or video and the reference visual cue to GPT-4o to generate both global and localized textual analyses, which are then combined with the visual operation to form a complete trajectory.
-
The dataset is publicly available with full documentation, including data schema, usage instructions, and license information, ensuring reproducibility and compliance with original dataset terms.
Method
The authors introduce Pixel-Reasoner, a framework designed to enable Vision-Language Models (VLMs) to perform reasoning directly within the pixel space by incorporating visual operations such as zoom-in and select-frame. This approach contrasts with traditional textual reasoning, where visual information is translated into text before reasoning. The core of the framework involves an iterative reasoning process where the model generates reasoning steps that can be either textual thinking or visual operations. A visual operation step involves invoking a predefined function, such as zoom-in or select-frame, which yields an execution outcome that is then incorporated into the reasoning chain. This process allows the model to actively inspect, interrogate, and infer from visual evidence, thereby enhancing reasoning fidelity for visually intensive tasks.
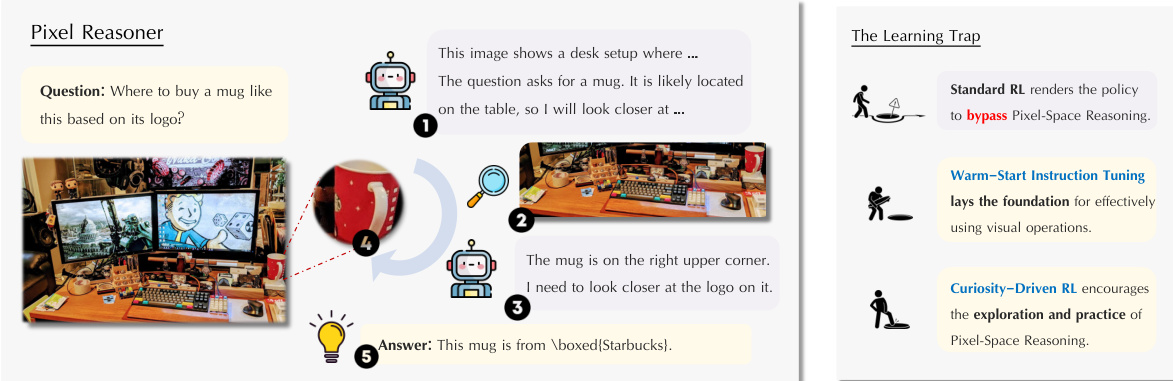
The framework is built upon a two-phase training approach to address the challenges of cultivating pixel-space reasoning. The first phase is warm-start instruction tuning, which aims to familiarize the model with the novel visual operations while preserving its self-correction capabilities. This phase involves synthesizing 7,500 reasoning traces that guide the model in mastering visual operations and developing a foundational understanding. The instruction tuning phase is crucial for establishing a baseline proficiency in visual operations, which is necessary for the subsequent reinforcement learning phase.

The second phase employs a curiosity-driven reinforcement learning (RL) approach to balance exploration between pixel-space and textual reasoning. This phase is designed to overcome the "learning trap" that arises from the model's initial imbalance in proficiency between textual and visual reasoning. The learning trap is characterized by the model's initial incompetence in visual operations leading to negative feedback, and the ability to bypass visual operations in queries that do not strictly require them. To break this cycle, the authors propose a curiosity-driven reward scheme that intrinsically rewards the act of attempting pixel-space operations. This scheme is formalized as a constrained optimization problem, where the objective is to maximize the expected correctness outcome while ensuring a minimum rate of pixel-space reasoning and limiting the number of visual operations per response. The modified reward function incorporates a curiosity bonus for responses that utilize pixel-space reasoning when the overall rate is below a threshold, and a penalty for exceeding a maximum number of visual operations.
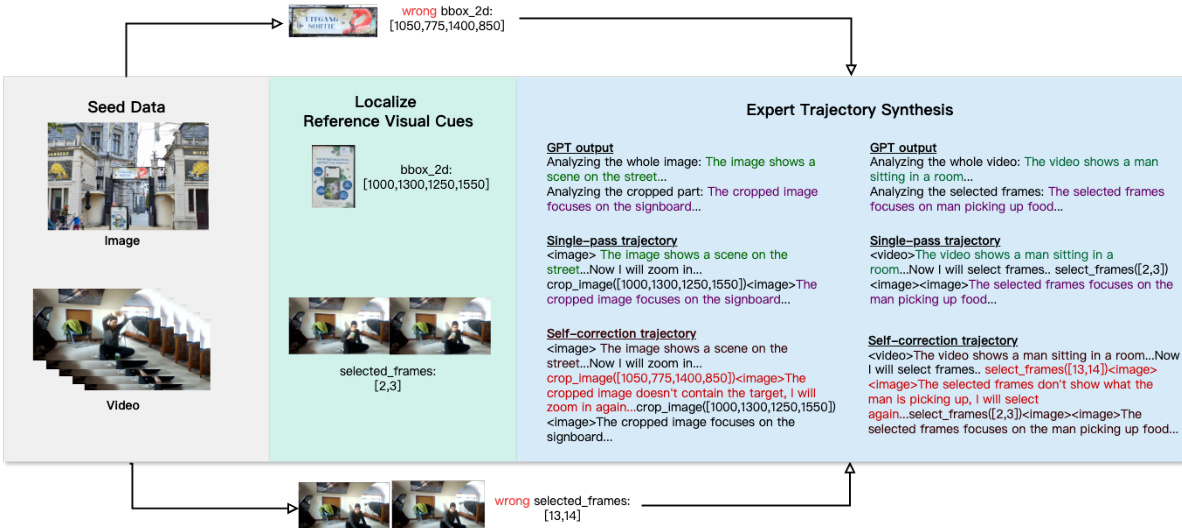
The training pipeline begins with seed data, which is used to generate reference visual cues. These cues are then used in expert trajectory synthesis, where GPT-4o is employed to generate reasoning traces that involve visual operations. The synthesis process includes both single-pass trajectories and self-correction trajectories, which are designed to provide a diverse set of training examples. The final model, Pixel-Reasoner, is built on top of Qwen2.5-VL-7B and is trained using the synthesized data and the curiosity-driven RL approach. This framework enables the model to interact with complex visual inputs, such as information-rich images or videos, by proactively gathering necessary information through visual operations.
Experiment
- Pixel-Reasoner achieves state-of-the-art results on four multimodal benchmarks: V* (84.3), TallyQA, InfographicVQA, and MVBench, outperforming both larger open-source models (e.g., 27B Gemma3) and proprietary models (e.g., Gemini-2.5-Pro by 5.1 points on V*).
- The model, trained on 7,500 trajectories with 5,500 pixel-space reasoning samples, demonstrates that reinforcement learning with curiosity-driven rewards is essential for cultivating pixel-space reasoning, overcoming the "learning trap" observed in supervised fine-tuning.
- Ablation studies confirm that warm-start instruction tuning with self-correction and curiosity incentives are critical: models without these components default to text-space reasoning, leading to a 2.5-point average performance drop.
- Pixel-Reasoner triggers pixel-space reasoning in 78.5% of responses on V*, 66.9% on MVBench, and over 57% on other benchmarks, with low error rates, indicating effective and reliable visual operation utilization.
- Training on 4×8 A800 (80G) GPUs for 20 hours using GRPO with selective sample replay and a reward scheme incorporating curiosity bonus and efficiency penalty enables stable and high-performing training dynamics.
The authors use the table to detail the distribution of trajectory types in their dataset, showing that for image tasks, 30% are single-pass, 20% involve one recrop, 20% involve two recrops, and 30% require further zoom-in operations. For video tasks, 90% of trajectories are single-pass, while 10% involve a reselction.

Results show that Pixel-Reasoner achieves the highest open-source performance across all four benchmarks, outperforming larger models and specialized tool-based systems. The model's success is attributed to effective instruction tuning and a curiosity-driven reward scheme that overcomes the "learning trap" by actively cultivating pixel-space reasoning.

Results show that Pixel-Reasoner achieves a high rate of pixel-space reasoning, with its RaPR stabilizing above 0.7 after 20,000 training steps, while the baseline model without curiosity rewards rapidly declines to near zero. This demonstrates that the curiosity-driven reward scheme is essential for sustaining and cultivating pixel-space reasoning during training.

The authors use a comprehensive set of benchmarks to evaluate Pixel-Reasoner, a 7B parameter model trained with reinforcement learning and a curiosity-driven reward scheme. Results show that Pixel-Reasoner achieves state-of-the-art performance across all four benchmarks, outperforming larger open-source models and specialized tool-based models, with the highest scores on V* Bench (84.3) and InfographicVQA (84.0).
