Command Palette
Search for a command to run...
次フレーム予測モデルにおける入力フレームコンテキストのパッキングによる動画生成
次フレーム予測モデルにおける入力フレームコンテキストのパッキングによる動画生成
Lvmin Zhang Maneesh Agrawala
概要
我々は、動画生成における次フレーム(または次フレーム領域)予測モデルの学習を目的としたニューラルネットワーク構造「FramePack」を提案する。FramePackは、フレームごとの重要度に基づいて入力フレームコンテキストを圧縮することで、固定されたコンテキスト長内により多くのフレームを符号化可能とする。重要なフレームほど長いコンテキストを確保できるように設計されている。フレームの重要度は、時間的近接性、特徴量類似性、あるいはそれらを組み合わせたハイブリッド指標によって評価できる。このパッキング手法により、数千フレーム規模の推論および比較的大きなバッチサイズでの学習が可能となる。さらに、観測バイアス(誤差の累積)を抑制するためのドリフト防止手法を提示し、初期に確立されたエンドポイント、調整されたサンプリング順序、離散的履歴表現の導入を含む。アブレーション研究により、単方向動画ストリーミングおよび双方向動画生成の両方において、これらのドリフト防止手法の有効性が検証された。最後に、既存の動画拡散モデルがFramePackを用いて微調整可能であることを示し、異なるパッキングスケジュール間の差異についても分析した。
One-sentence Summary
The authors from Stanford University and MIT propose FramePack, a neural architecture that uses frame-wise importance weighting to compress video contexts, enabling efficient training and inference with thousands of frames; by dynamically prioritizing key frames and incorporating drift prevention techniques like discrete history representation, it improves long-range video generation over prior methods, particularly in bidirectional and streaming scenarios.
Key Contributions
- FramePack introduces a novel frame compression mechanism that prioritizes input frames based on time proximity, feature similarity, or hybrid metrics, enabling efficient encoding of thousands of frames within a fixed transformer context length while preserving critical temporal dependencies.
- The method combats drifting through anti-drifting techniques such as early-established endpoints, adjusted sampling orders, and discrete history representation, which reduce error accumulation and observation bias during both training and inference.
- FramePack enables effective finetuning of existing video diffusion models (e.g., HunyuanVideo, Wan) with improved scalability, supporting long-video generation on consumer hardware and demonstrating superior performance across ablation studies in both unidirectional and bidirectional settings.
Introduction
Next-frame-prediction video diffusion models face a critical trade-off between forgetting and drifting: strong memory mechanisms help maintain temporal consistency but amplify error propagation, while methods that reduce error accumulation weaken temporal dependencies and worsen forgetting. Prior approaches struggle with scalability due to quadratic attention complexity in transformers and inefficient handling of redundant temporal data. The authors introduce FramePack, a memory structure that compresses input frames using time-proximity and feature-similarity-based importance measures, enabling fixed-length context processing and efficient long-video generation. To combat drifting, they propose anti-drifting sampling that breaks causal chains via bi-directional context planning and an anti-drifting training method that discretizes frame history to align training and inference. These techniques enable stable, high-quality video generation over thousands of frames, even on consumer hardware, and can be applied to fine-tune existing models like HunyuanVideo and Wan.
Method
The authors leverage a neural network architecture called FramePack to address the challenge of training next-frame prediction models for video generation under constrained context lengths. The core framework enables the compression of input frame contexts by assigning frame-wise importance, allowing for the encoding of a large number of frames within a fixed context length. This is achieved by applying progressive compression to frames based on their relevance to the prediction target, with more important frames receiving longer context representations. The overall framework operates on latent representations, as is common in modern video generation models, and is designed to work with diffusion-based architectures such as Diffusion Transformers (DiTs). The model predicts a section of S unknown frames conditioned on a section of T input frames, where T is typically much larger than S. The primary goal is to manage the context length explosion that arises in vanilla DiT models, which scales linearly with the total number of frames T+S.
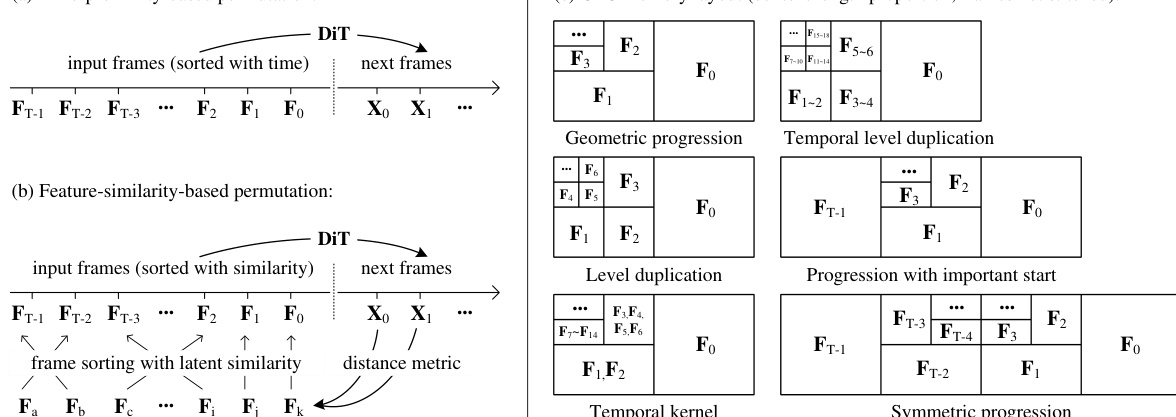
As shown in the figure below, the framework supports multiple packing strategies. The first approach, time-proximity-based packing, orders input frames by their temporal distance to the prediction target, with the most recent frame being the most important. Each frame Fi is assigned a context length ϕ(Fi) determined by a geometric progression defined as ϕ(Fi)=Lf/λi, where Lf is the per-frame context length and λ>1 is a compression parameter. This results in a total context length that converges to a bounded value as T increases, effectively making the compression bottleneck invariant to the number of input frames. The compression is implemented by manipulating the transformer's patchify kernel size in the input layer, with different kernel sizes corresponding to different compression rates. The authors discuss various kernel structures, including geometric progression, temporal level duplication, level duplication, and symmetric progression, which allow for flexible and efficient compression. To support efficient computation, the authors primarily use λ=2, and they note that arbitrary compression rates can be achieved by duplicating or dropping specific terms in the power-of-2 sequence. The framework also employs independent patchifying parameters for different compression rates, initializing their weights by interpolating from a pretrained projection. For handling the tail frames that may fall below a minimum unit size, three options are considered: deletion, incremental context length increase, or global average pooling.
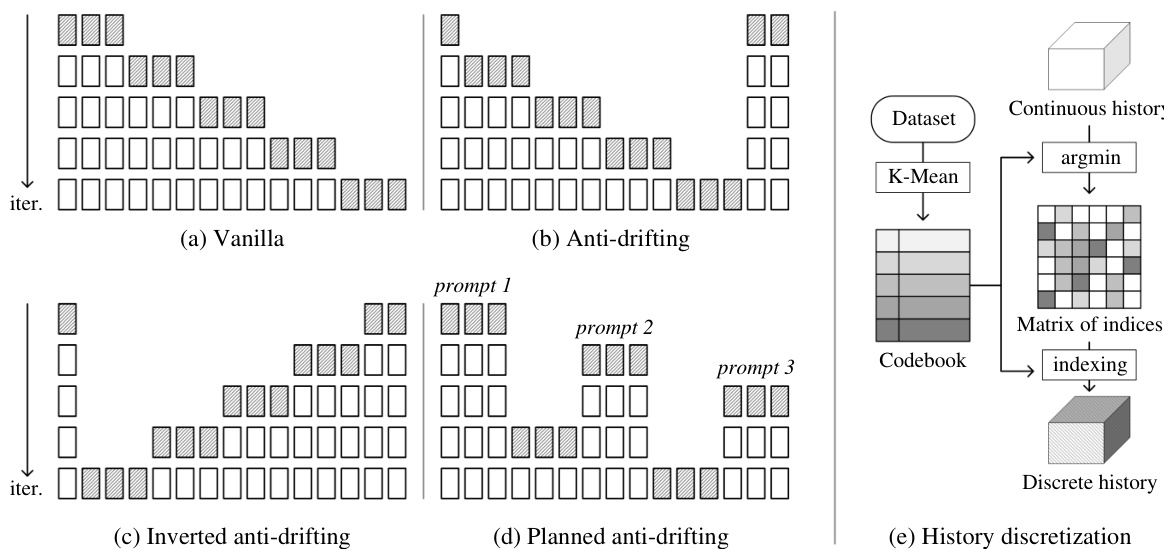
The authors also present a feature-similarity-based packing method, which sorts input frames based on their similarity to the estimated next frame section. This is achieved using a cosine similarity metric, simcos(Fi,X^), which measures the similarity between each history frame and the predicted frame section. This approach can be combined with a smooth time proximity modeling to create a hybrid metric, simhybrid(Fi,X^), which balances feature similarity and temporal distance. This hybrid approach is particularly suitable for datasets where the model needs to return to previously visited views, such as in video games or movie generation. The framework also includes several anti-drifting methods to address observation bias and error accumulation. One method involves planned endpoints, where the first iteration generates both the beginning and ending sections of the video, and subsequent iterations fill the gaps. This bi-directional approach is more robust to drifting than a strict causal system. Another method, inverted sampling, is effective for image-to-video generation, where the first frame is a user input and the last frame is a generated endpoint. This method ensures that all generations are directed towards approximating the high-quality user input. Multiple endpoints can be planned with different prompts to support more dynamic motions and complex storytelling. Finally, the authors introduce history discretization, which converts the continuous latent history into discrete integer tokens using a codebook generated by K-Means clustering. This reduces the mode gap between training and inference distributions, mitigating drifting. The discrete history is represented as a matrix of indices, which is then used during training.
Experiment
- Inverted anti-drifting sampling achieves the best performance in 4 out of 7 metrics and excels in all drifting metrics, demonstrating superior mitigation of video drift while maintaining high quality.
- Vanilla sampling with history discretization achieves competitive human preference scores (ELO) and a larger dynamic range, indicating effective balance between memory retention and drift reduction.
- DiffusionForcing ablations show that higher test-time noise levels (σ_test) reduce reliance on history, mitigating drift but increasing forgetting; optimal trade-off found at σ_test = 0.1.
- History guidance amplifies memory but exacerbates drifting due to accelerated error accumulation, confirming the inherent forgetting-drifting trade-off.
- On HunyuanVideo at 480p resolution, FramePack supports batch sizes up to 64 on a single 8xA100-80G node, enabling efficient training at lab scale.
- Ablation studies confirm that overall architecture design dominates performance differences, with minor variations within the same sampling approach.
The authors use a comprehensive ablation study to evaluate different FramePack configurations, focusing on their impact on video quality, drifting, and human preferences. Results show that the inverted anti-drifting sampling method achieves the best performance in all drifting metrics and ranks highest in human assessments, while the vanilla sampling with discrete history offers a strong balance between drifting reduction and dynamic range.
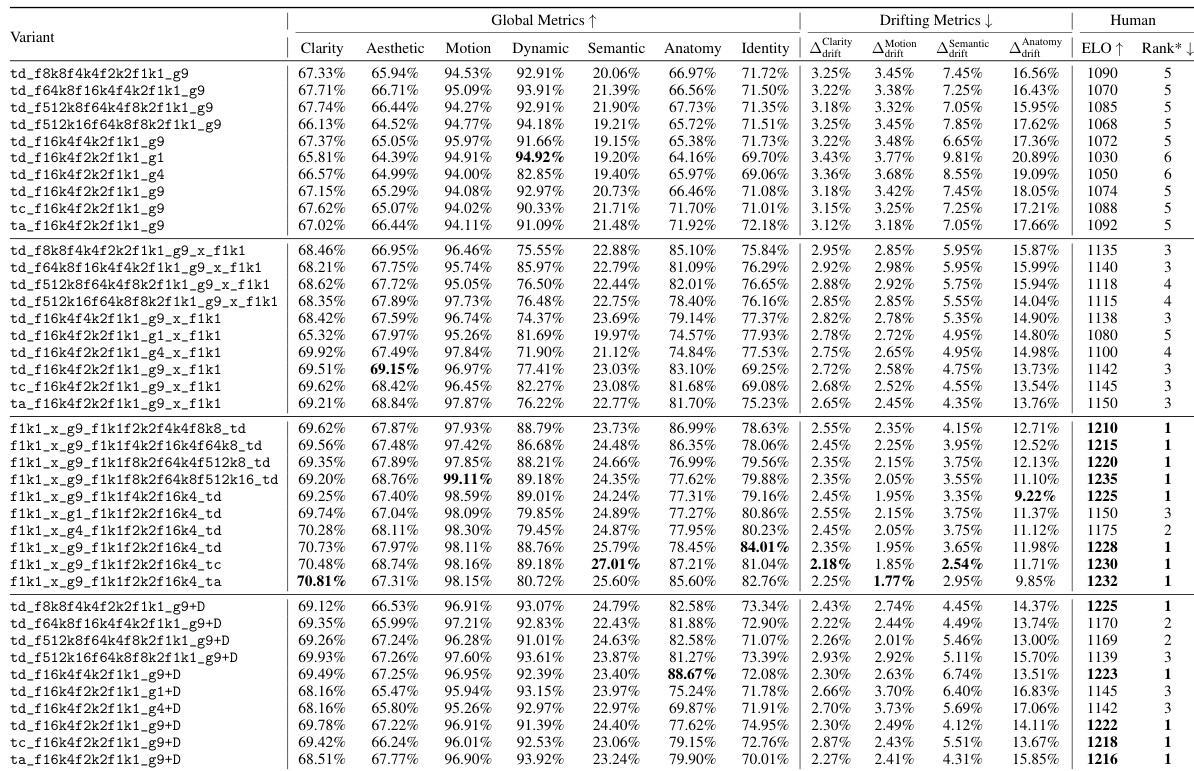
The authors use a series of ablation studies to evaluate different video generation methods, focusing on their performance across global quality metrics, drifting metrics, and human assessments. Results show that the inverted anti-drifting sampling method achieves the best performance in all drifting metrics and ranks highest in human preference, while the vanilla sampling with discrete history offers a strong balance between low drifting and high dynamic range.
