Command Palette
Search for a command to run...
YOLOv12:注目機構中心型のリアルタイム物体検出器
YOLOv12:注目機構中心型のリアルタイム物体検出器
Yunjie Tian Qixiang Ye David Doermann
概要
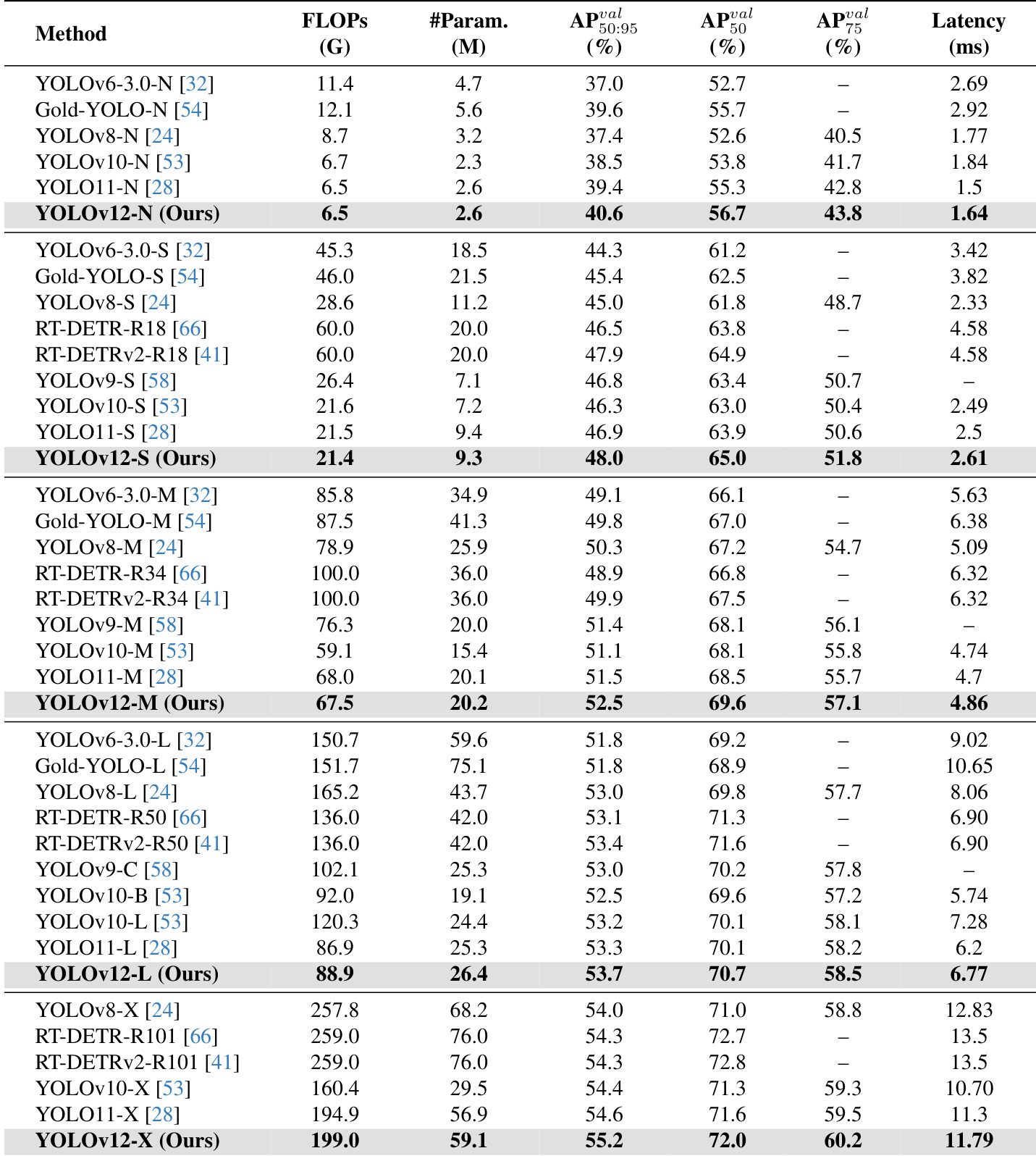
YOLOフレームワークのネットワークアーキテクチャの強化は長年にわたり重要視されてきたが、注目メカニズム(attention mechanism)のモデル化能力における顕著な優位性にもかかわらず、これまでの研究は主にCNNベースの改善に注力してきた。その理由は、注目メカニズムを用いたモデルがCNNベースのモデルと比較して処理速度で劣るためである。本論文では、注目メカニズムの性能利点を活かしつつ、従来のCNNベースのモデルと同等の高速性を実現する、注目中心のYOLOフレームワーク、すなわちYOLOv12を提案する。YOLOv12は、競合するリアルタイム物体検出器と比較して、高い精度と競争力ある処理速度を両立している。例えば、YOLOv12-NはT4 GPU上で1.64msの推論遅延で40.6%のmAPを達成し、先進的なYOLOv10-NおよびYOLOv11-Nと比較してそれぞれ2.1%、1.2%のmAP向上を実現しつつ、処理速度は同等である。この利点は他のモデルスケールにも拡張可能である。また、DETRを改善したエンドツーエンド型リアルタイム検出器(RT-DETR / RT-DETRv2)と比較しても、YOLOv12-SはRT-DETR-R18およびRT-DETRv2-R18を上回る性能を発揮しつつ、処理速度は42%高速で、計算量は36%、パラメータ数は45%に抑えることができる。その他の比較結果については図1に示す。
One-sentence Summary
The authors from University at Buffalo and University of Chinese Academy of Sciences propose YOLOv12, an attention-centric real-time object detector that achieves superior accuracy over CNN-based YOLO variants and end-to-end DETR-style models while matching their speed, leveraging efficient attention mechanisms to outperform prior work in latency-accuracy and FLOPs-accuracy trade-offs.
Key Contributions
- This work addresses the long-standing trade-off between accuracy and speed in real-time object detection by introducing YOLOv12, an attention-centric framework that overcomes the computational inefficiency of attention mechanisms while maintaining the high inference speed required for real-time applications.
- The proposed YOLOv12 integrates a novel area attention module (A2) with a residual efficient layer aggregation network (R-ELAN) and architectural optimizations such as FlashAttention, removal of positional encoding, and adjusted MLP ratios, enabling efficient attention-based modeling within the YOLO paradigm.
- YOLOv12 achieves state-of-the-art accuracy across all model scales—e.g., 40.6% mAP for YOLOv12-N—surpassing YOLOv10-N and YOLOv11-N by 2.1% and 1.2% mAP respectively, while running faster and using significantly fewer parameters and FLOPs than end-to-end detectors like RT-DETR and RT-DETRv2.
Introduction
Real-time object detection is critical for applications like autonomous driving and robotics, where low latency and high accuracy are essential. The YOLO series has dominated this space by balancing speed and performance, but recent advances have largely relied on CNN-based architectures despite attention mechanisms demonstrating superior modeling capacity. The main challenge lies in attention’s quadratic computational complexity and inefficient memory access patterns, which hinder real-time deployment. Prior attempts to integrate attention into YOLO systems have failed to match CNN-based models in speed, limiting their practical adoption. The authors introduce YOLOv12, an attention-centric framework that overcomes these limitations through three key innovations: a simple yet efficient area attention module (A2) that reduces complexity while maintaining a large receptive field, a redesigned residual efficient layer aggregation network (R-ELAN) that improves optimization and gradient flow, and architectural streamlining—including the use of FlashAttention, removal of positional encoding, and balanced MLP ratios—to enhance speed and reduce overhead. As a result, YOLOv12 achieves state-of-the-art accuracy across all scales while matching or exceeding the speed of prior CNN-based YOLO models, outperforming YOLOv10-N, YOLOv11-N, and end-to-end detectors like RT-DETR-R18 with significantly lower FLOPs, parameters, and latency.
Method
The authors leverage a novel network architecture to integrate attention mechanisms into the YOLO framework, addressing the computational inefficiencies typically associated with such designs in real-time object detection systems. The core of the approach centers on two key innovations: the area attention module and the residual efficient layer aggregation network (R-ELAN), which are designed to reduce computational complexity while maintaining high performance.
The area attention module is introduced as a simple yet effective alternative to existing attention mechanisms. As shown in the figure below, it transforms global attention into a localized operation by dividing the feature map of resolution (H,W) into l segments along either the height or width dimension, resulting in segments of size (lH,W) or (H,lW). This approach avoids the explicit window partitioning required by methods such as shift window or criss-cross attention, eliminating associated overhead and simplifying the implementation to a single reshape operation. The default value of l is set to 4, which reduces the receptive field to one-fourth of the original but still preserves a sufficiently large field for effective feature representation. This design reduces the computational cost of the attention mechanism from 2n2hd to 21n2hd, where n is the number of tokens, h is the number of heads, and d is the head size. Despite the quadratic complexity in n, this remains efficient for the fixed input resolution of 640×640, and the authors observe only a slight impact on performance while achieving significant speed improvements.
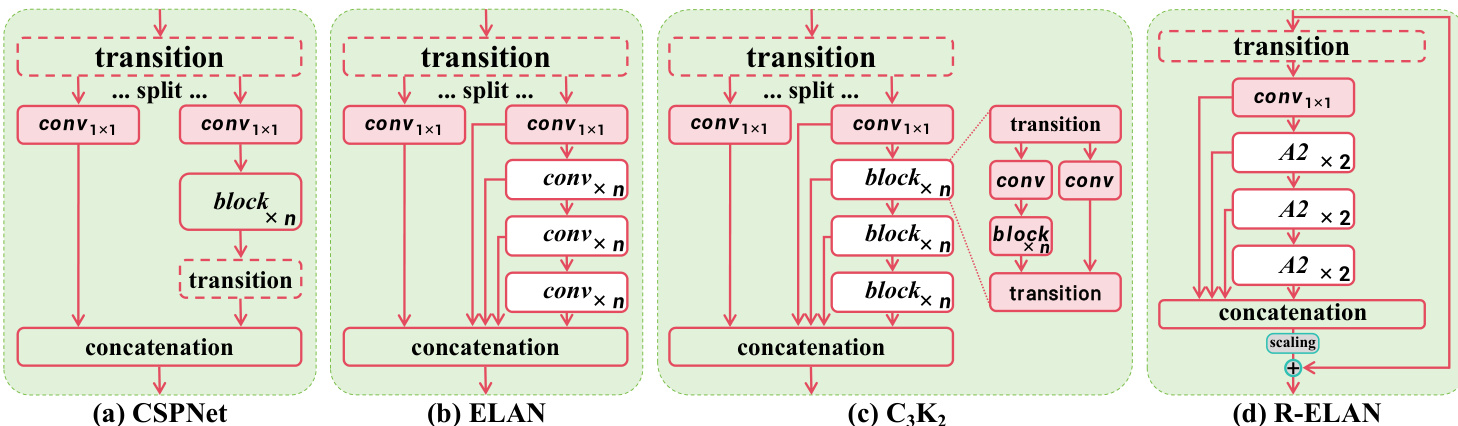
The R-ELAN architecture is designed to overcome the instability and gradient blocking issues present in the original efficient layer aggregation network (ELAN). As illustrated in the framework diagram, the standard ELAN (Figure 3b) splits the output of a transition layer into two parts, processes one through multiple modules, and then concatenates the results. This design lacks residual connections from input to output, which can hinder convergence, especially when combined with attention mechanisms. To address this, the authors propose R-ELAN (Figure 3d), which introduces a residual shortcut from the input to the output of the block, scaled by a factor of 0.01. This scaling factor is similar to layer scaling used in deep vision transformers and helps stabilize training. Additionally, the R-ELAN design modifies the aggregation process by first applying a transition layer to adjust channel dimensions and producing a single feature map, which is then processed through subsequent blocks before concatenation. This creates a bottleneck structure that preserves feature integration capabilities while reducing computational cost and memory usage.

Beyond these core modules, the authors implement several architectural improvements to better align the attention mechanism with the real-time constraints of the YOLO system. They retain the hierarchical design of previous YOLO systems, contrasting with the plain-style architectures common in attention-centric vision transformers. The number of blocks in the backbone is reduced by removing the stacking of three blocks in the final stage, retaining only a single R-ELAN block to simplify the network and aid optimization. The first two stages of the backbone are inherited from YOLOv11, and the R-ELAN module is not applied to these stages. Furthermore, several default configurations of the vanilla attention mechanism are modified: the MLP ratio is reduced to 1.2 (or 2 for smaller models), nn.Conv2d with batch normalization is used instead of nn.Linear with layer normalization to leverage the efficiency of convolutional operators, positional encoding is removed, and a large separable convolution (7×7), referred to as a position perceiver, is introduced to help the area attention module capture positional information. These modifications are designed to better allocate computational resources and improve the overall efficiency of the system.
Experiment
- YOLOv12-N achieves 45.8 mAP on MSCOCO 2017, outperforming YOLOv6-N, YOLOv8-N, YOLOv10-N, and YOLOv11-N by 3.6%, 3.3%, 2.1%, and 1.2% respectively, with 1.64 ms/image latency.
- YOLOv12-S achieves 48.0 mAP with 2.61 ms/image latency, surpassing YOLOv8-S, YOLOv9-S, YOLOv10-S, and YOLOv11-S by 3.0%, 1.2%, 1.7%, and 1.1%, while maintaining lower or comparable FLOPs and parameters.
- YOLOv12-M achieves 52.5 mAP with 4.86 ms/image latency, outperforming Gold-YOLO-M, YOLOv8-M, YOLOv9-M, YOLOv10-M, YOLOv11-M, and RT-DETR-R34/RT-DETRv2-R34.
- YOLOv12-L surpasses YOLOv10-L by 0.4% mAP with 31.4G fewer FLOPs, and outperforms RT-DETR-R50/RT-DETRv2-R50 with faster speed, 34.6% fewer FLOPs, and 37.1% fewer parameters.
- YOLOv12-X exceeds YOLOv10-X and YOLOv11-X by 0.8% and 0.6% mAP respectively, and beats RT-DETR-R101/RT-DETRv2-R101 with faster speed, 23.4% fewer FLOPs, and 22.2% fewer parameters.
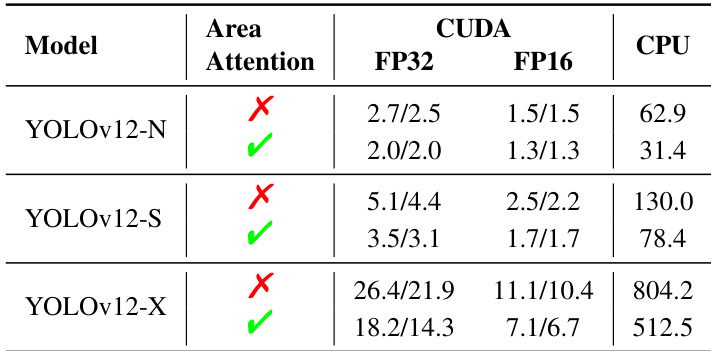
- Ablation studies confirm that R-ELAN improves training stability in larger models (YOLOv12-L/X) and reduces complexity with minimal performance loss; area attention significantly accelerates inference across GPU and CPU platforms.
- Diagnostics show that convolution-based attention with batch normalization outperforms linear-based attention and layer normalization; removing positional embeddings improves performance and speed; an MLP ratio of 1.2 enhances performance over the conventional 4.0; FlashAttention reduces latency by 0.3–0.4 ms.
- Visualization reveals that YOLOv12 produces clearer object heat maps than YOLOv10 and YOLOv11, indicating superior foreground perception due to the area attention mechanism’s larger receptive field.
The authors use the MSCOCO 2017 dataset to evaluate YOLOv12, comparing its performance against several state-of-the-art real-time detectors. Results show that YOLOv12 achieves higher accuracy with fewer parameters and faster inference speed across all model scales, particularly excelling in the N, S, and M variants while maintaining competitive performance in the L and X variants.
The authors use the MS COCO 2017 dataset to evaluate YOLOv12 against several state-of-the-art detectors, showing that YOLOv12 achieves higher accuracy with fewer parameters compared to YOLOv8, YOLOv9, RT-DETR, and YOLOv10. The results demonstrate that YOLOv12 establishes a superior accuracy-parameter trade-off, particularly in the smaller model sizes, indicating its efficiency and effectiveness.

The authors compare YOLOv12 with YOLOv9, YOLOv10, and YOLOv11 across different model scales and hardware platforms, showing that YOLOv12 achieves faster inference speeds on RTX 3080, A5000, and A6000 GPUs while maintaining competitive performance. For example, YOLOv12-N reduces latency to 1.7 ms (FP32) on RTX 3080, outperforming YOLOv9 and matching YOLOv10 and YOLOv11 in speed.

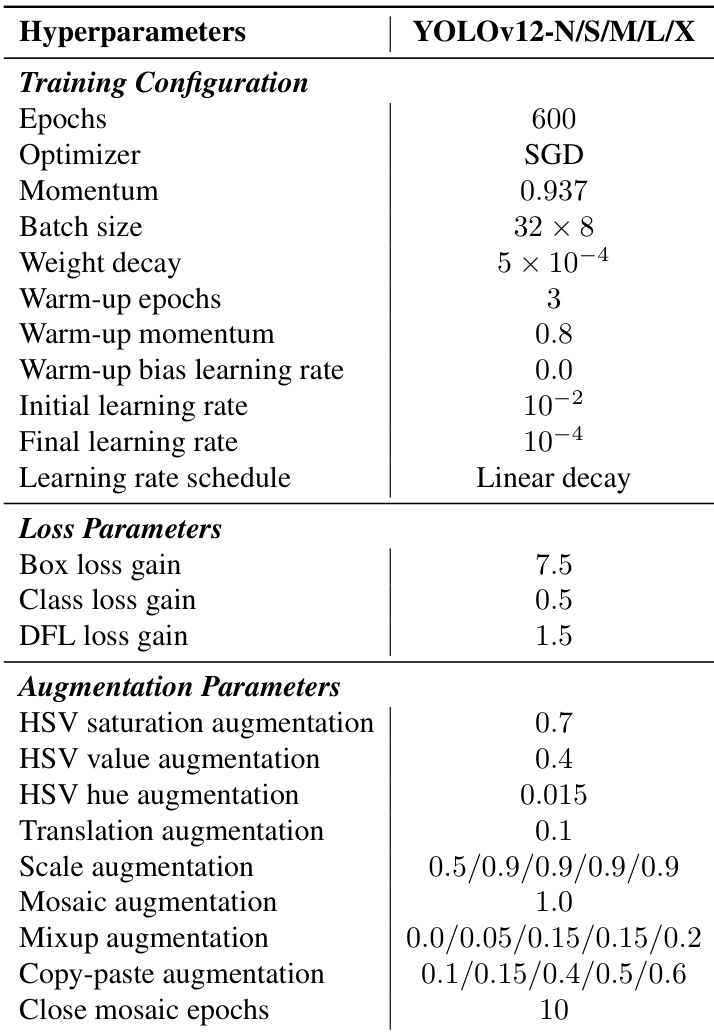
The authors use a training configuration of 600 epochs with SGD optimizer, linear learning rate decay, and a warm-up period of 3 epochs for YOLOv12-N/S/M/L/X models. The setup includes specific hyperparameters such as a batch size of 32 × 8, weight decay of 5 × 10⁻⁴, and data augmentations like Mosaic, Mixup, and copy-paste to enhance model performance.
Results show that the area attention mechanism significantly reduces inference latency for YOLOv12-N, YOLOv12-S, and YOLOv12-X across both GPU (CUDA) and CPU platforms. For example, YOLOv12-N achieves a 0.7ms reduction in FP32 latency on RTX 3080 when area attention is enabled, with consistent speed improvements observed across all models and hardware configurations.