Command Palette
Search for a command to run...
Depth Pro:1秒未満で高精度な単眼メトリック深度を実現
Depth Pro:1秒未満で高精度な単眼メトリック深度を実現
Aleksei Bochkovskii Amaël Delaunoy Hugo Germain Marcel Santos Yichao Zhou Stephan R. Richter Vladlen Koltun
概要
ゼロショットメトリック単眼深度推定のためのファウンデーションモデルを提案する。本モデルであるDepth Proは、類を見ないほど高い解像度と高周波成分の詳細を備えた深度マップを合成可能である。推定結果は絶対スケールを保ち、カメラの内部パラメータ(イントリンシック)などのメタデータに依存しないメトリックな深度を出力する。また、標準的なGPU上で225万画素の深度マップを0.3秒で生成するという高速性も実現している。これらの特性は、高密度予測に適した効率的なマルチスケールビジョントランスフォーマー、実データと合成データを組み合わせたトレーニングプロトコル(高精度なメトリック推定と細部の境界追跡を両立)、推定深度マップにおける境界精度を評価する専用の評価指標、および単一画像からの最先端の焦点距離推定技術といった技術的貢献によって実現されている。広範な実験により、具体的な設計選択の有効性が分析され、Depth Proが複数の指標において従来手法を上回ることを示した。コードおよびモデル重みは、https://github.com/apple/ml-depth-pro にて公開している。
One-sentence Summary
The authors from Apple present Depth Pro, a foundation model for zero-shot metric monocular depth estimation that generates high-resolution, scale-accurate depth maps without relying on camera metadata, leveraging an efficient multi-scale vision transformer and a hybrid real-synthetic training protocol to achieve superior boundary fidelity and speed, enabling real-time applications in robotics and AR/VR.
Key Contributions
- Depth Pro introduces a foundation model for zero-shot metric monocular depth estimation that produces high-resolution, metrically accurate depth maps with absolute scale without requiring camera intrinsics, enabling applications like view synthesis on arbitrary images 'in the wild'.
- The model employs an efficient multi-scale vision transformer architecture and a novel training protocol combining real and synthetic datasets with specialized loss functions, achieving state-of-the-art boundary accuracy while maintaining high-frequency detail fidelity.
- Depth Pro generates 2.25-megapixel depth maps in 0.3 seconds on a V100 GPU, outperforming prior methods in boundary recall by a multiplicative factor and setting new benchmarks in both speed and accuracy, while also introducing zero-shot focal length estimation from a single image.
Introduction
Zero-shot monocular depth estimation is critical for applications like view synthesis, 3D reconstruction, and conditional image generation, where accurate, metric depth maps are needed without domain-specific training or camera metadata. Prior methods often fail to balance high resolution, sharp boundary detection, metric accuracy, and low latency—especially when operating on arbitrary images without known camera intrinsics. Many approaches either lack absolute scale, rely on computationally heavy post-processing, or sacrifice detail for speed. The authors introduce Depth Pro, a foundation model that delivers zero-shot metric depth estimation with absolute scale on any image, even without focal length input. It achieves 2.25-megapixel depth maps at 0.3 seconds per image on a V100 GPU, outperforming prior work in boundary accuracy by a multiplicative factor while being orders of magnitude faster. Depth Pro leverages a multi-scale ViT architecture, a novel training curriculum with hybrid real and synthetic data, and a new loss design that promotes sharp depth edges. It also introduces a direct field-of-view estimation module from network features, significantly improving focal length prediction over existing methods.
Dataset
- The dataset comprises multiple sources used for training and evaluation, with detailed information provided in Table 15, including dataset licenses and their designated roles (e.g., training, testing).
- Key subsets include diverse data sources such as public benchmarks, domain-specific corpora, and curated collections, each with specified sizes, origins, and filtering rules applied during preprocessing.
- The authors use a mixture of these datasets during training, with specific mixture ratios defined per dataset to balance representation across tasks and domains.
- Training data is processed through standardized tokenization, normalization, and filtering to ensure consistency, with additional cropping applied to long sequences to fit model input constraints.
- Metadata is constructed to track dataset provenance, task type, and domain labels, enabling fine-grained analysis and controlled evaluation.
- The training split is derived from the full dataset by applying random sampling and stratification to maintain distributional balance across subsets.
Method
The authors leverage a multi-scale vision transformer (ViT) architecture to achieve high-resolution, sharp, and metric monocular depth estimation. The overall framework operates at a fixed resolution of 1536×1536, which is a multiple of the base ViT resolution of 384×384, ensuring a consistent receptive field and efficient computation while avoiding memory issues associated with variable-resolution approaches. The network processes the input image through a series of scales, where at each scale the image is split into non-overlapping or overlapping patches of size 384×384. For the two finest scales, patches are allowed to overlap to prevent seams in the final depth map. These patches are then concatenated along the batch dimension and processed in parallel by a shared ViT-based patch encoder, which produces feature tensors at a resolution of 24×24 per patch. At the finest scale, additional intermediate features are extracted to capture finer-grained details. The resulting feature patches are merged into feature maps using a Voronoi partitioning scheme, where each patch's contribution is determined by its Voronoi cell centered at the patch's center. This merging process ensures that overlapping regions are properly combined while maintaining spatial consistency. The merged features are then upsampled and fused through a decoder module that resembles the DPT decoder, which generates the final inverse depth prediction. The entire process is anchored by a separate image encoder that processes the full-resolution image downsampled to 384×384, providing global context to the patch-based predictions. 
The network is trained using a multi-objective loss function that prioritizes canonical inverse depth, which is particularly beneficial for applications such as novel view synthesis. For metric datasets, the primary loss is the mean absolute error (MAE) between the predicted and ground-truth canonical inverse depth, with outliers discarded based on the top 20% error per image. For non-metric datasets, predictions and ground truth are normalized using the mean absolute deviation from the median before applying the loss. To enhance boundary sharpness, the training incorporates derivative-based losses on the first and second-order gradients of the inverse depth maps at multiple scales. These include the mean absolute gradient error (MAGE), mean absolute Laplace error (MALE), and mean squared gradient error (MSGE), which are computed over a multi-scale pyramid generated by blurring and downsampling. The training follows a two-stage curriculum: the first stage trains on a mix of real and synthetic datasets using MAE and a scale-and-shift-invariant gradient loss on synthetic data to learn robust, domain-general features; the second stage focuses exclusively on high-quality synthetic datasets, using MAE and the derivative losses to refine predictions and sharpen boundaries. This approach contrasts with conventional methods that typically fine-tune on real data after synthetic pretraining.
To ensure metric depth predictions, the model includes a dedicated focal length estimation head. This head is a small convolutional network that ingests frozen features from the depth estimation network and task-specific features from a separate ViT image encoder trained for focal length prediction. The head predicts the horizontal angular field-of-view, which is used to scale the canonical inverse depth into a metric depth map. The focal length head is trained separately after the depth estimation network, which avoids the need to balance competing objectives and allows the use of diverse datasets for focal length supervision, including those without depth annotations. This modular design enables the model to produce accurate, scale-aware depth maps even when camera intrinsics are missing or unreliable. 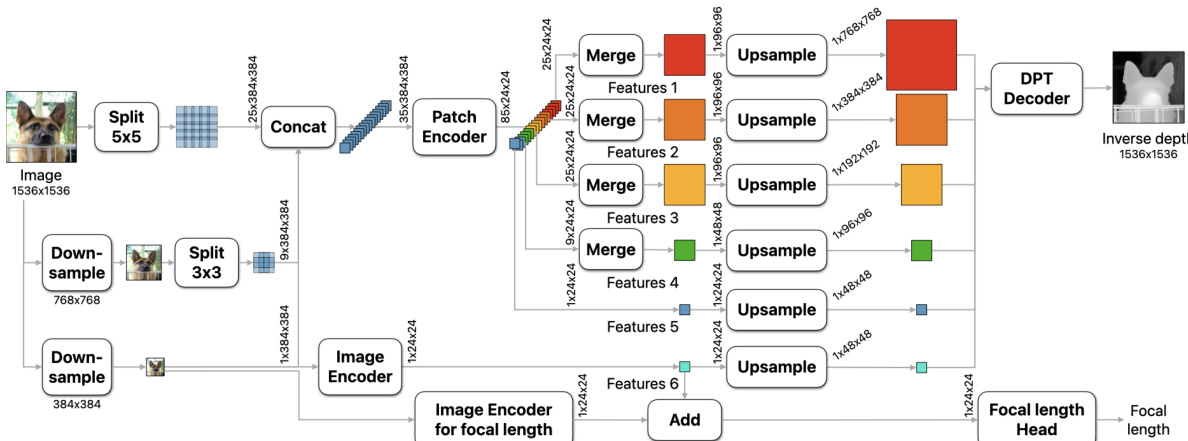
Experiment
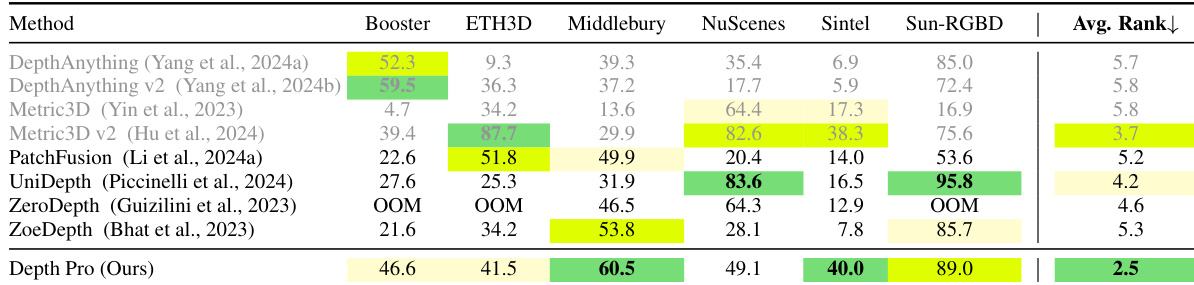
- Zero-shot metric depth estimation: Depth Pro achieves state-of-the-art performance on multiple datasets (Booster, Middlebury, Sun-RGBD, ETH3D, nuScenes, Sintel), attaining the best average rank in Tab. 1 using the δ₁ metric, with superior accuracy compared to leading models including Depth Anything v2, Metric3D v2, and ZoeDepth.
- Zero-shot boundary accuracy: Depth Pro significantly outperforms all baselines on boundary F1 and recall metrics across diverse datasets (Sintel, Spring, iBims, AM-2k, P3M-10k, DIS-5k), producing sharper boundaries for fine structures like hair and fur, and demonstrating clear advantages in downstream applications such as novel view synthesis and image matting.
- Focal length estimation: Depth Pro achieves the highest accuracy in zero-shot focal length estimation across five datasets (FiveK, DDDP, SPAQ, PPR10K, ZOOM), with 64.6% of images on PPR10K having a relative error below 25%, outperforming the second-best method SPEC by 30 percentage points.
- Runtime efficiency: Depth Pro processes high-resolution images (4K) in under 1 second on a V100 GPU, with less than half the parameters and one-third the runtime of Metric3D v2, while achieving higher native output resolution and better boundary accuracy than variable-resolution models like PatchFusion and ZeroDepth.
Results show that Depth Pro achieves the best performance across all metrics, with the lowest Log10 and AbsRel errors and the highest F1 score, outperforming Marigold, Depth Anything v2, and DPT. The model's superior accuracy and boundary detection are attributed to its high native output resolution and optimized training approach.

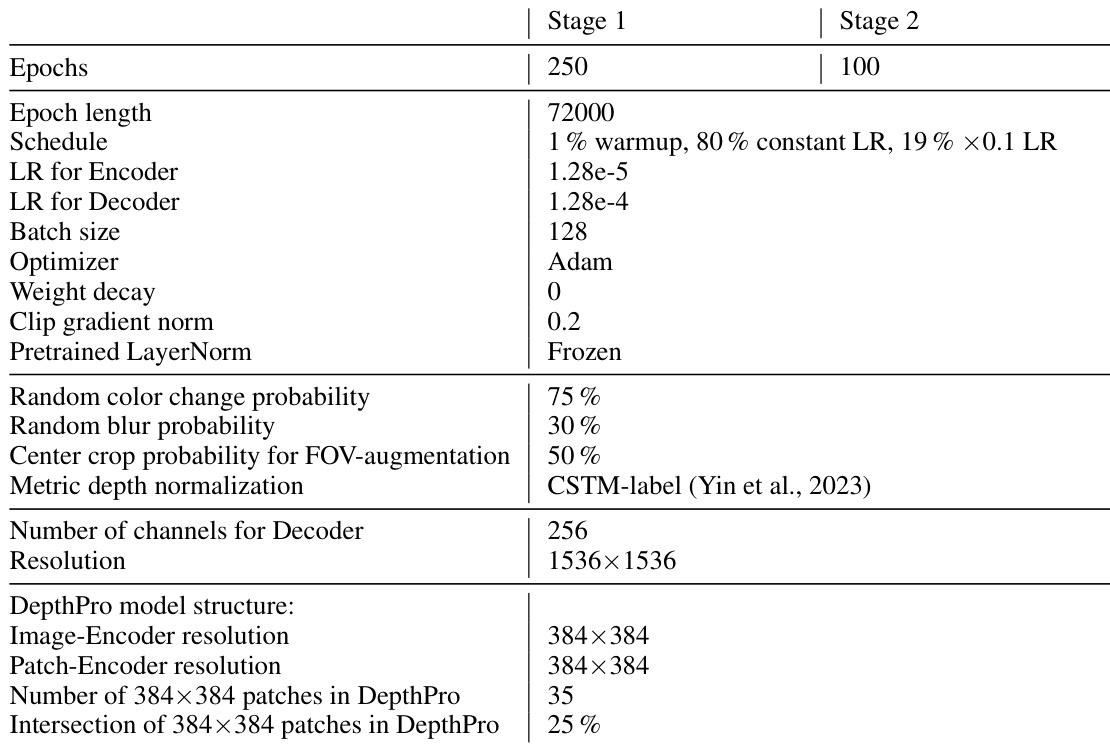
The authors use a two-stage training curriculum for Depth Pro, with Stage 1 lasting 250 epochs and Stage 2 lasting 100 epochs, employing a learning rate schedule that includes a 1% warmup followed by 80% constant learning rate and a final 19% decay to 0.1 of the initial rate. The model is trained with a batch size of 128 using the Adam optimizer, and the decoder resolution is set to 1536×1536, while the image and patch encoders operate at 384×384.
The authors use a two-stage training curriculum to optimize depth estimation, with the first stage focusing on metric depth accuracy and the second on sharpening boundaries. Results show that their approach (3A) achieves the best average rank across datasets, outperforming single-stage and reversed-stage training methods in both metric depth and boundary accuracy.

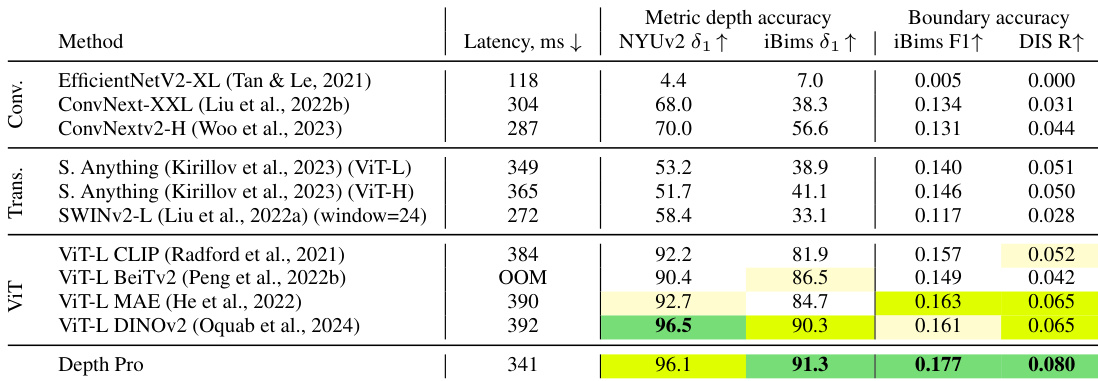
Results show that Depth Pro achieves the highest metric depth accuracy across all datasets, with the best scores in NYUv2 and iBims, while also outperforming all baselines in boundary accuracy, particularly in iBims F1 and DIS R metrics. The model maintains competitive latency, processing images in 341 ms, and demonstrates superior performance compared to other vision transformer-based methods.
Results show that Depth Pro achieves the best average rank across all datasets, outperforming all baselines in zero-shot metric depth estimation. It consistently scores among the top approaches per dataset, with particularly strong performance on Middlebury and Sun-RGBD, where it achieves the highest individual scores.