Command Palette
Search for a command to run...
大規模言語モデルのサービングにおける効率的なメモリ管理:PagedAttentionを用いた手法
大規模言語モデルのサービングにおける効率的なメモリ管理:PagedAttentionを用いた手法
Woosuk Kwon Zhuohan Li Siyuan Zhuang Ying Sheng Lianmin Zheng Cody Hao Yu Joseph E. Gonzalez Hao Zhang Ion Stoica
概要
大規模言語モデル(LLM)の高スループットなサービングには、一度に多数のリクエストをバッチ処理する必要がある。しかし、従来のシステムは、各リクエストに必要なキーバリューキャッシュ(KVキャッシュ)メモリが非常に大きく、動的に増減するため、効率的なメモリ管理が困難である。不適切な管理が行われると、メモリの断片化や重複したコピーが発生し、大幅なメモリの無駄遣いが生じ、結果としてバッチサイズの拡大が制限される。この問題に対処するため、本研究では、オペレーティングシステムの従来の仮想メモリおよびページング技術に着想を得た「PagedAttention」というアテンションアルゴリズムを提案する。この技術を基盤に、vLLMと呼ばれるLLMサービングシステムを構築した。vLLMは、(1)KVキャッシュメモリのほぼゼロの無駄を実現し、(2)リクエスト内およびリクエスト間でのKVキャッシュの柔軟な共有により、さらにメモリ使用量を削減することを可能にする。評価結果によると、FasterTransformerやOrcaといった最先端システムと比較して、vLLMは同等の遅延レベルで、代表的なLLMのスループットを2〜4倍まで向上させた。特に長文シーケンス、大規模モデル、および複雑なデコードアルゴリズムを用いる場合、その効果は顕著に増す。vLLMのソースコードは、https://github.com/vllm-project/vllm にて公開されている。
One-sentence Summary
The authors from UC Berkeley, Stanford University, UC San Diego, and an independent researcher propose vLLM, a high-throughput LLM serving system that leverages PagedAttention—inspired by virtual memory—to eliminate KV cache fragmentation and enable flexible cache sharing, achieving 2–4× higher throughput than state-of-the-art systems with minimal latency overhead, especially for long sequences and complex decoding.
Key Contributions
- Existing LLM serving systems suffer from severe KV cache memory waste due to contiguous memory allocation, leading to internal and external fragmentation, which limits batch size and throughput—especially under dynamic, variable-length sequences and complex decoding strategies.
- PagedAttention introduces a novel attention mechanism inspired by operating system virtual memory, dividing KV cache into fixed-size blocks that can be allocated non-contiguously, enabling near-zero memory waste and efficient sharing across sequences within and between requests.
- vLLM, built on PagedAttention, achieves 2-4× higher throughput than state-of-the-art systems like FasterTransformer and Orca across diverse models and workloads, with improvements amplifying for longer sequences, larger models, and advanced decoding algorithms.
Introduction
The authors address the critical challenge of memory efficiency in large language model (LLM) serving, where high costs and limited GPU memory constrain throughput. Existing systems store the KV cache—essential for autoregressive generation—in contiguous memory blocks pre-allocated to maximum sequence lengths, leading to severe internal and external fragmentation, inefficient memory utilization, and inability to share cache across multiple sequences or requests. This limits batch sizes and underutilizes GPU capacity, especially under variable-length inputs and complex decoding strategies like beam search or parallel sampling. To overcome these limitations, the authors introduce PagedAttention, an attention mechanism inspired by operating system virtual memory, which partitions the KV cache into fixed-size blocks that can be allocated non-contiguously. This enables dynamic, on-demand allocation, eliminates fragmentation, and supports fine-grained memory sharing across sequences and requests. Built on this foundation, the authors develop vLLM, a distributed serving engine that combines block-level memory management with preemptive scheduling, achieving near-zero KV cache waste and 2–4× higher throughput than prior systems like FasterTransformer and Orca, without sacrificing accuracy.
Method
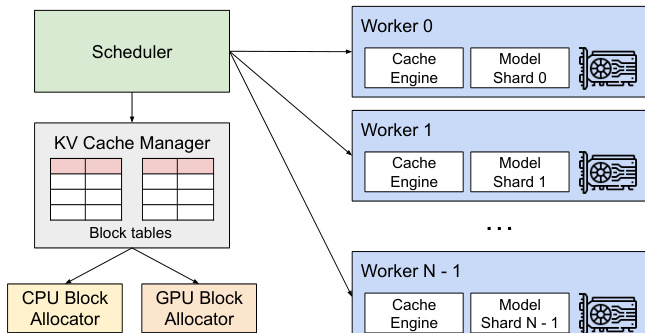
The authors leverage a novel attention algorithm, PagedAttention, and a corresponding system architecture, vLLM, to address the challenges of memory fragmentation and inefficient KV cache utilization in large language model (LLM) serving. The core of the system is a centralized scheduler that coordinates the execution of multiple GPU workers, each hosting a model shard. This scheduler manages a shared KV cache manager, which is responsible for the dynamic allocation and management of KV cache memory across the distributed system. The KV cache manager operates by organizing the KV cache into fixed-size blocks, analogous to pages in virtual memory, and maintains block tables that map logical KV blocks for each request to their corresponding physical blocks in GPU DRAM. This separation of logical and physical memory allows for dynamic memory allocation, eliminating the need to pre-reserve memory for the maximum possible sequence length and significantly reducing internal fragmentation.

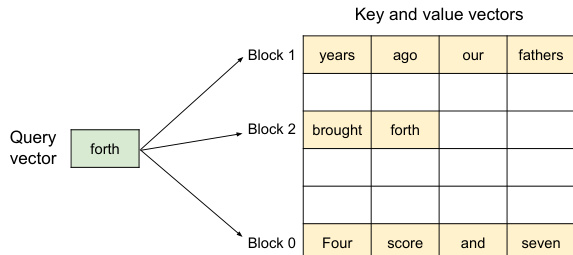
The PagedAttention algorithm, as illustrated in the figure below, enables the efficient computation of attention scores when the key and value vectors are stored in non-contiguous physical memory blocks. Instead of requiring the KV cache for a sequence to be stored in a single contiguous block, PagedAttention partitions the cache into fixed-size KV blocks. During the attention computation, the algorithm identifies the relevant blocks for a given query token and fetches them separately. The attention score for a query token qi is computed by multiplying qi with the key vectors in each block Kj to obtain a row vector of attention scores Aij, and then multiplying this vector with the corresponding value vectors Vj to produce the final output oi. This block-wise computation allows the attention kernel to process multiple positions in parallel, improving hardware utilization and reducing latency, while enabling flexible memory management.
The memory management process is demonstrated in the following example. During the prompt phase, the KV cache for the prompt tokens is generated and stored in logical blocks. For instance, the first four tokens of a prompt are stored in logical block 0, and the next three tokens are stored in logical block 1. The block table records the mapping from these logical blocks to their physical counterparts in GPU DRAM. As the autoregressive generation phase proceeds, new tokens are generated, and their KV cache is stored in the next available slot of the last logical block. When a logical block becomes full, a new physical block is allocated and mapped to a new logical block in the block table. This process ensures that memory is allocated only as needed, and any unused space within a block is the only source of memory waste, which is bounded by the block size. The system can also handle multiple requests simultaneously, as shown in the figure below, where the logical blocks of different requests are mapped to non-contiguous physical blocks, allowing for efficient utilization of the available GPU memory.
In a distributed setting, vLLM supports model parallelism, where the model is partitioned across multiple GPUs. The KV cache manager remains centralized, providing a common mapping from logical blocks to physical blocks that is shared among all GPU workers. Each worker only stores a portion of the KV cache for its corresponding attention heads. The scheduler orchestrates the execution by broadcasting the input tokens and block table for each request to the workers. The workers then execute the model, reading the KV cache according to the provided block table during attention operations. This design allows the system to scale to large models that exceed the memory capacity of a single GPU while maintaining efficient memory management.
Experiment
- Parallel sampling: vLLM enables efficient sharing of prompt KV cache across multiple output sequences via paged memory management and copy-on-write, reducing memory usage; on OPT-13B with Alpaca dataset, it achieves 1.67×–3.58× higher throughput than Orca (Oracle) in shared prefix scenarios and up to 2.3× higher throughput in beam search compared to Orca (Oracle).
- Beam search: vLLM dynamically shares KV cache blocks across beam candidates, reducing frequent memory copies; on OPT-13B with Alpaca dataset, it achieves 37.6%–55.2% memory savings and 2.3× higher throughput than Orca (Oracle) with beam width 6.
- Shared prefix: vLLM caches KV blocks for common prefixes, allowing reuse across requests; on LLaMA-13B with WMT16 translation workload, it achieves 1.67× higher throughput with one-shot prefix and 3.58× higher throughput with five-shot prefix compared to Orca (Oracle).
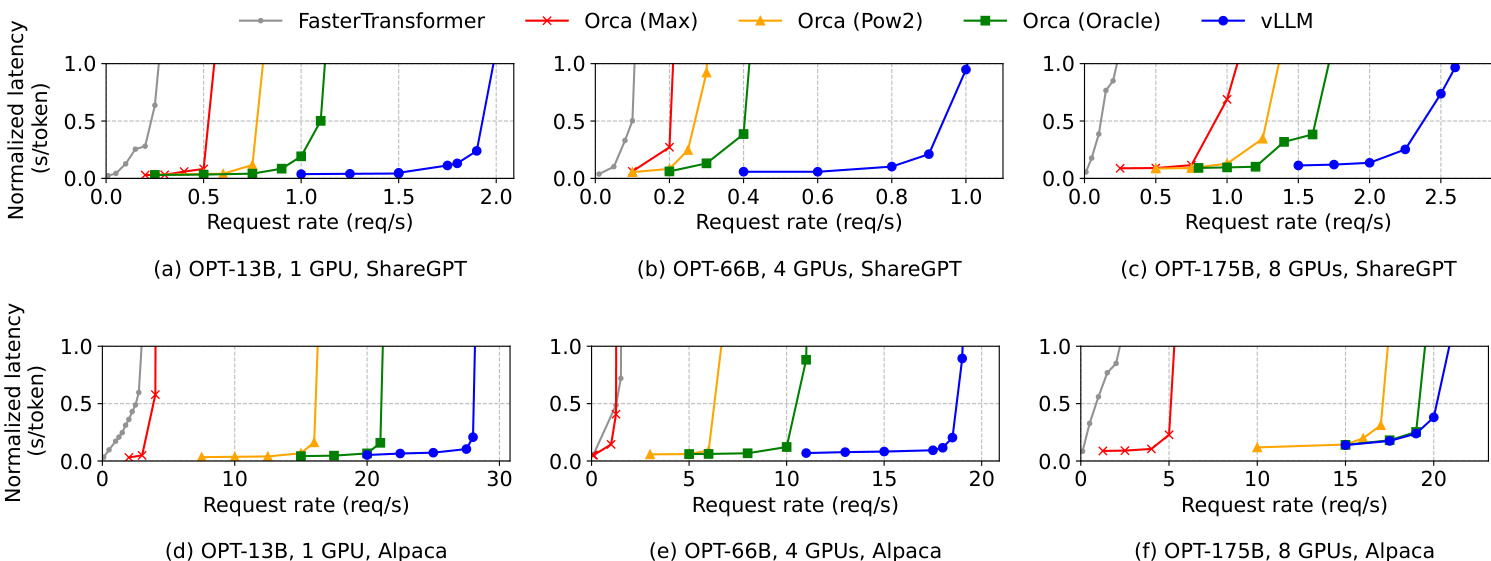
- Basic sampling: On OPT-13B and OPT-175B models, vLLM sustains 1.7×–2.7× higher request rates than Orca (Oracle) and 2.7×–8× higher than Orca (Max) on ShareGPT dataset while maintaining low normalized latency; on Alpaca dataset, it achieves up to 22× higher request rates than FasterTransformer.
- Memory efficiency: vLLM reduces memory usage by 6.1%–9.8% in parallel sampling and 37.6%–66.3% in beam search (on ShareGPT) through block sharing, with default block size 16 balancing GPU utilization and fragmentation.
Results show that vLLM sustains significantly higher request rates than Orca and FasterTransformer across all models and datasets, with the largest improvements observed on the ShareGPT dataset due to its longer prompts and higher memory pressure. The performance advantage of vLLM is particularly pronounced under high request loads, where it maintains low normalized latency while outperforming baselines that suffer from memory management inefficiencies.
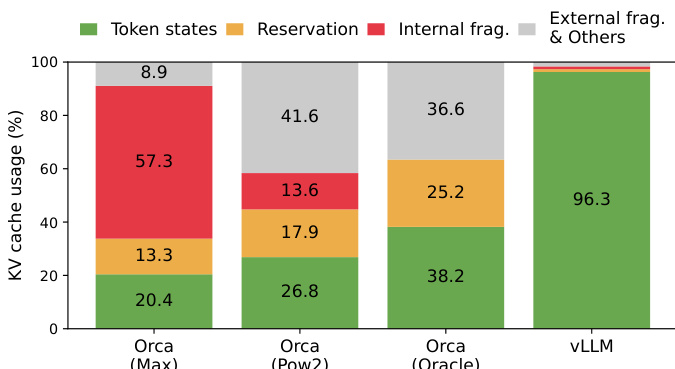
The authors use a bar chart to compare KV cache usage across different systems, showing that vLLM achieves significantly lower internal fragmentation and reservation overhead compared to Orca variants. Results show that vLLM reduces internal fragmentation to 3.7% and reservation to 0.4%, while Orca (Max) has 57.3% internal fragmentation and 13.3% reservation, indicating vLLM's superior memory management efficiency.
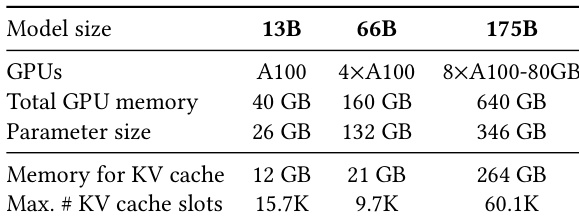
The authors use the table to show the GPU and memory configurations for different model sizes in their evaluation. For each model size, the table specifies the number of GPUs, total GPU memory, parameter size, memory required for KV cache, and the maximum number of KV cache slots. The results show that the memory required for KV cache increases with model size, and the maximum number of KV cache slots varies significantly across models, with the 175B model supporting the highest number of slots.