HyperAI
Command Palette
Search for a command to run...
Dolphin マルチモーダルドキュメント画像解析
1. チュートリアルの概要

Dolphinは、ByteDanceが2025年5月に発表したマルチモーダル文書解析モデルです。このモデルは2段階のアプローチに基づいています。まず、文書レイアウト要素のシーケンスを生成し、次にこれらの要素をアンカーとして使用してコンテンツを並列解析します。Dolphinは様々な文書解析タスクにおいて非常に優れたパフォーマンスを発揮し、GPT-4.1やMistral-OCRなどのモデルを凌駕しています。関連研究論文もご覧いただけます。 Dolphin: 異種アンカープロンプトによるドキュメント画像解析 ACL 2025に採択されました。
このチュートリアルでは、単一の RTX 4090 カードのリソースを使用します。
2. プロジェクト例

3. 操作手順
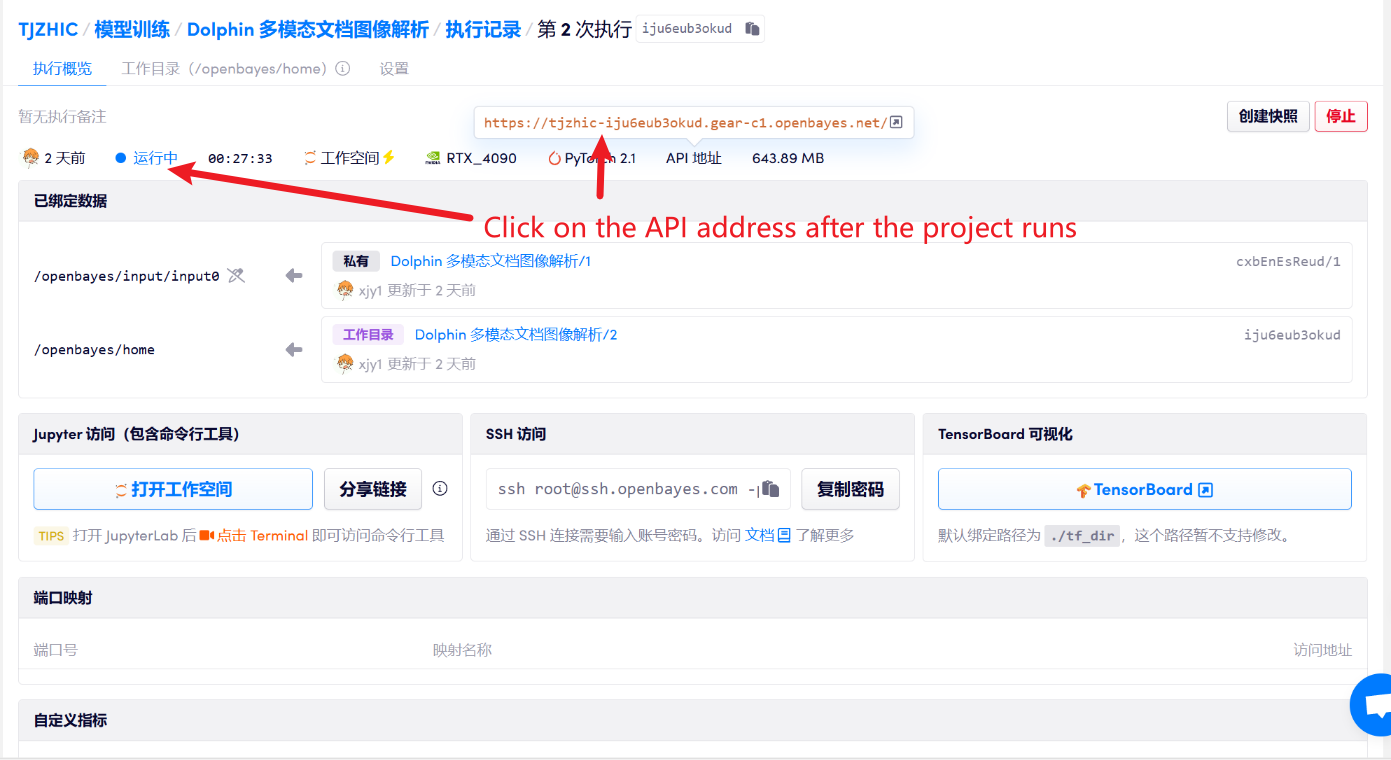
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってページを更新してください。
2. 使用例
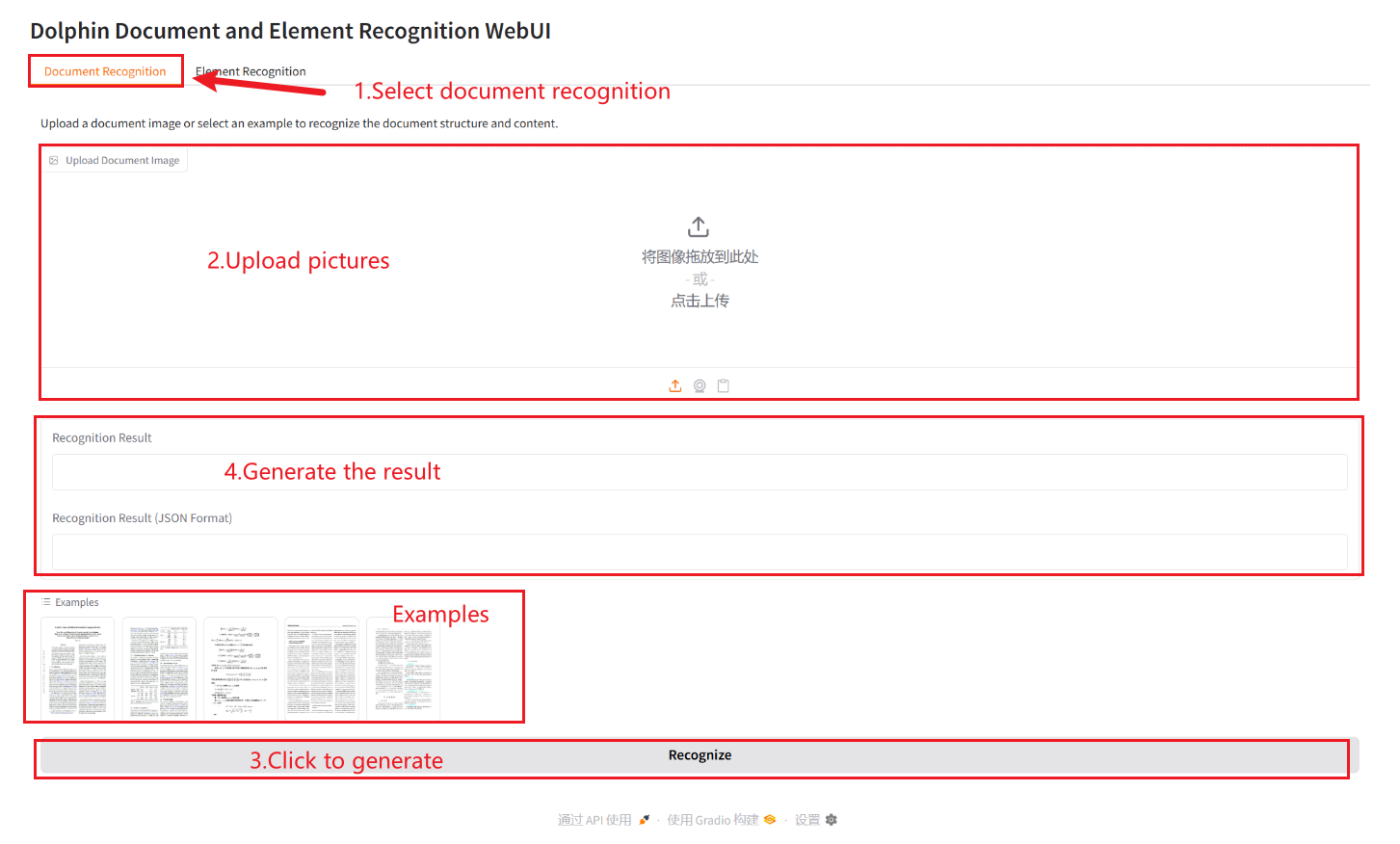
文書認識
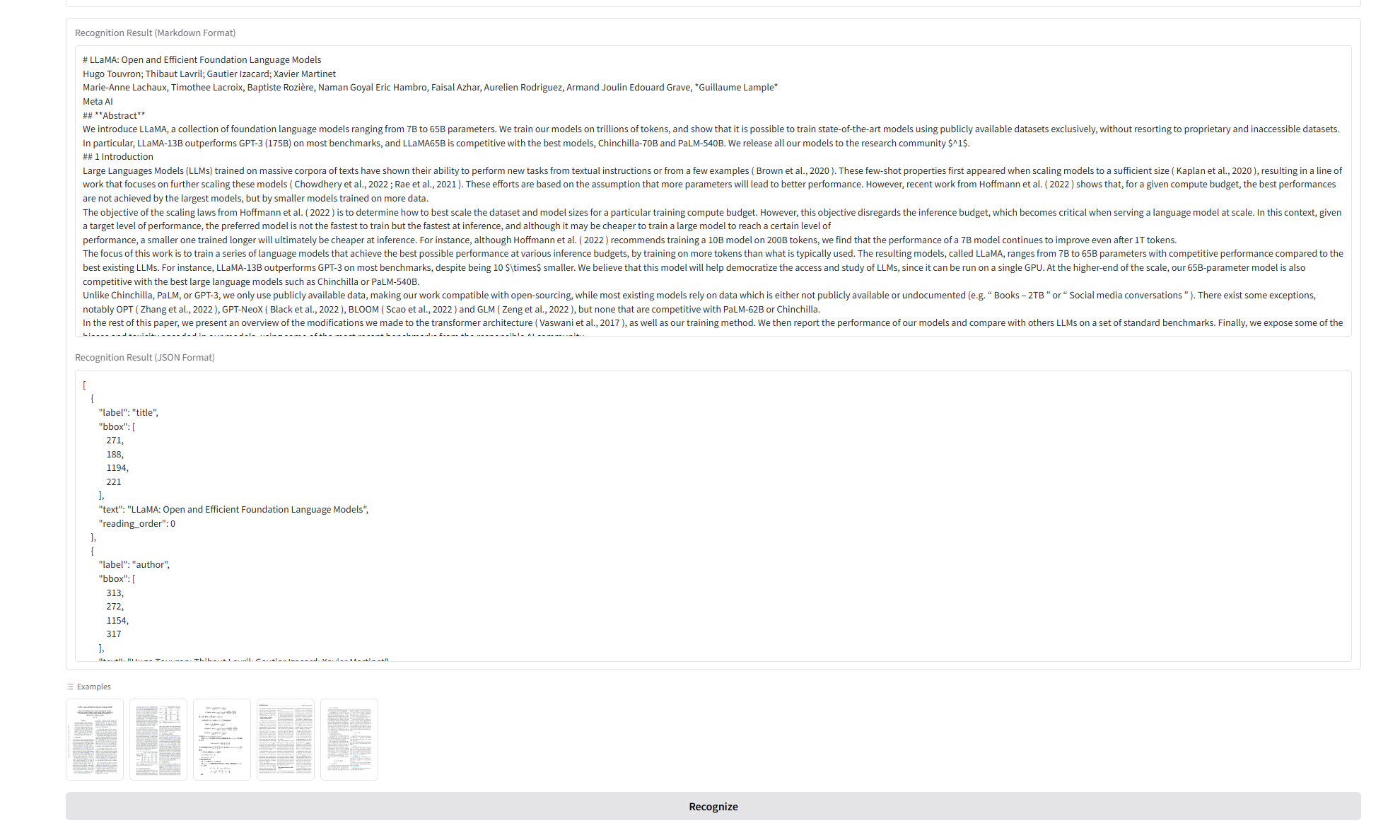
 結果
結果
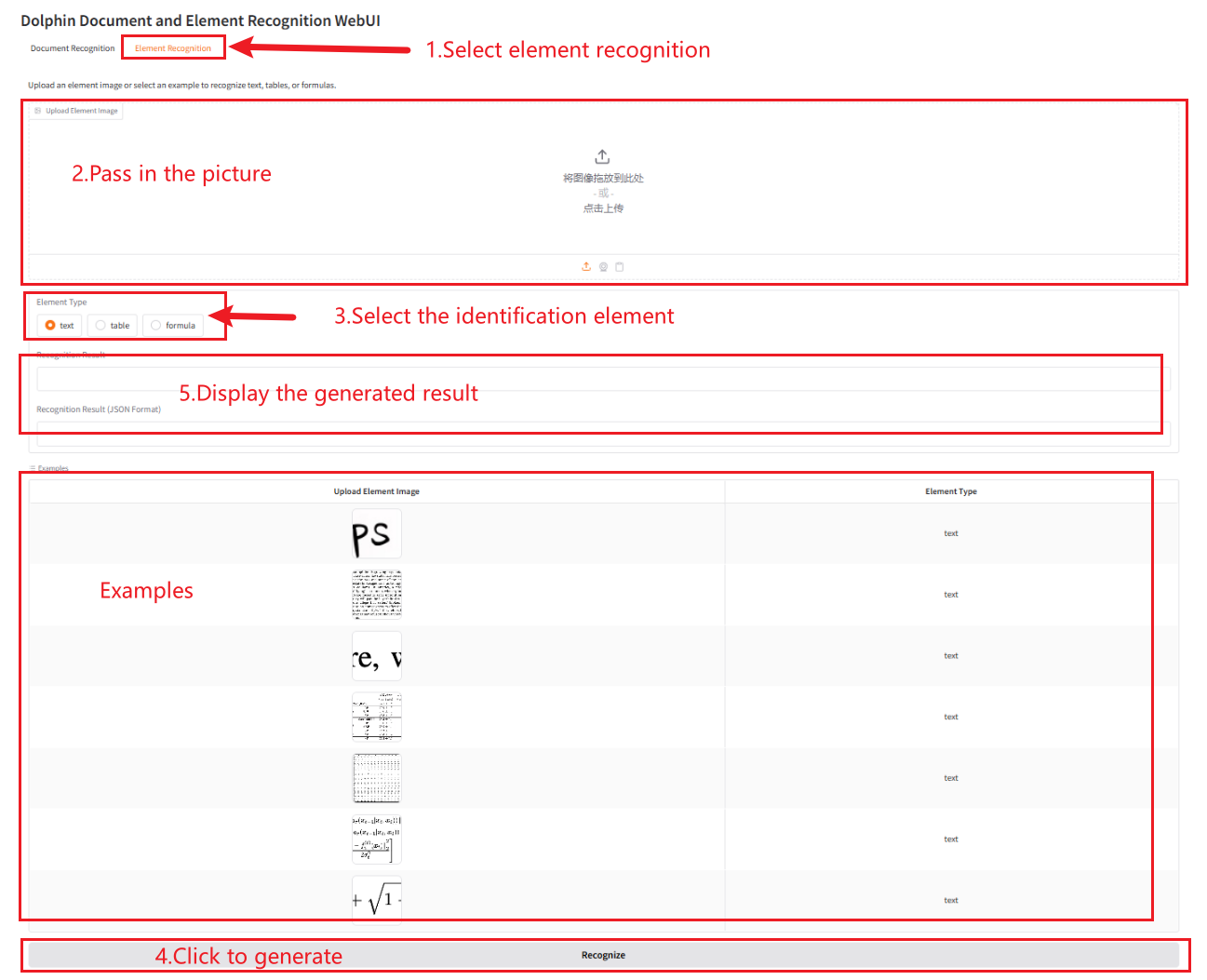
要素認識
結果
引用情報
このプロジェクトの引用情報は次のとおりです。
@inproceedings{dolphin2025,
title={Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting},
author={Feng, Hao and Wei, Shu and Fei, Xiang and Shi, Wei and Han, Yingdong and Liao, Lei and Lu, Jinghui and Wu, Binghong and Liu, Qi and Lin, Chunhui and Tang, Jingqun and Liu, Hao and Huang, Can},
year={2025},
booktitle={Proceedings of the 65rd Annual Meeting of the Association for Computational Linguistics (ACL)}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。