Command Palette
Search for a command to run...
香港科技大学は、タンパク質配列中の多金属結合部位を効率的に予測するための融合ニューラルネットワークフレームワークを提案した。
金属イオンは生命活動において不可欠な役割を果たしています。亜鉛は加水分解酵素の触媒作用においてルイス酸として働き、鉄は呼吸鎖における電子伝達の重要な担い手であり、マグネシウムはRNAが安定した三次構造に折り畳まれるために不可欠です。タンパク質データバンクには多数の高解像度金属タンパク質構造が蓄積されているにもかかわらず、金属-タンパク質相互作用の実験的同定は依然として時間がかかり、労力と費用がかかります。したがって、残留レベルに基づいて金属結合部位を計算で予測することが、効果的な代替戦略となっています。
多金属化合物を予測する既存の手法は、その構造によって大きな制約を受けており、構造に基づく予測手法は計算コストの高いプログラムに依存しているため、実用化が困難です。タンパク質言語モデルは有望な予測手法として浮上していますが、膨大な計算量と長い推論時間を要するため、実用化には限界があります。
この問題に対処するため、香港科技大学の研究チームは、タンパク質配列中の複数の金属の結合部位を予測するための融合ニューラルネットワークフレームワークを提案しました。このフレームワークは、畳み込みニューラルネットワーク(CNN)とフュージョンネットワークを組み合わせた2段階アーキテクチャを採用しています。不均衡を考慮した損失関数、統合評価、そしてモジュール型アーキテクチャを導入することで、異なる金属の陽性サンプルと陰性サンプル間のクラス不均衡、そしてそれらの複雑な相互作用に効果的に対処します。構造非依存設計により、構造入力を必要とせずに大規模データセットに対して高速、堅牢、かつ高品質な包括的予測が可能になり、金属-タンパク質相互作用マイニングの可能性を大きく高めます。
関連研究は、「タンパク質配列内の複数の金属結合部位を効率的に予測するモジュラー融合ニューラルネットワークアプローチ」というタイトルでbioRxivに掲載されました。
研究のハイライト:
* CNN と融合ネットワークを組み合わせた 2 段階の融合ニューラル ネットワーク フレームワーク。
* 重み付けバイナリクロスエントロピー損失関数を導入することで、金属結合部位予測におけるクラス不均衡問題が効果的に処理されます。
紙のアドレス:
公式アカウントをフォローし、「Multi-metal binding sites」と返信すると、完全なPDFを入手できます。
AIフロンティアに関するその他の論文:
安定した代表的なデータセットの構築
研究チームは、トレーニングと評価に適した高品質のデータセットを構築するために、既存のMbPAデータベースに基づいて二次処理を行いました。まず、MbPAデータベースから金属結合タンパク質の包括的なデータセットを取得しました。亜鉛(Zn)、鉄(Fe)、マグネシウム(Mg)に結合可能な合計91,593個のタンパク質がスクリーニングされ、検証済みの結合部位情報と対応する金属イオンが保持されました。この基盤を基に、研究チームはさらに、配列の正規化と整数エンコード(500アミノ酸の均一長)、結合部位のマルチラベルアノテーション、層別サンプリング(15%テストセット、85%開発セット)、およびクラス不均衡処理を完了しました。クラス不均衡処理には、クラス不均衡に対処するための3段階の前処理と独立したトレーニングプロセスが含まれ、同時に金属固有の予測子を実装しました。実装プロセスは、金属固有のラベル生成、陽性サンプルのカウント、および加重バイナリクロスエントロピー損失でした。
* MbPA(金属結合タンパク質アトラス)は、金属結合タンパク質のリソースライブラリです。現在、データベースには106,373件のエントリと440,187のサイトが含まれており、54種類の金属イオンと8,169種の化合物が登録されています。

2段階のディープラーニングフレームワークとモジュール融合
研究チームは、タンパク質配列中の多金属結合部位を効率的に予測するための配列ベースの2段階ディープラーニングフレームワークを提案しました。全体的な考え方は、まず単一の金属イオンについて独立した予測モデルを学習し、単一残基の確率マップを生成することです。次に、これらのマップを軽量な融合ネットワークを介して統合し、金属間の依存関係をモデル化し、最終的に予測性能を最適化します。
第一段階では、Zn、Fe、Mgの各単一金属について、1次元畳み込みニューラルネットワーク(Single-metal CNN)を用いて、特定の金属イオンの位置的結合確率を予測した。上記の処理後、各タンパク質配列は500次元表現として均一に表現された。整数符号化された残基は、64次元の学習可能なベクトルの埋め込み層にマッピングされた。その後、配列は、ReLU(Uniform Rectangular Unit)活性化関数を用いて、4つのConv1D層(畳み込みカーネル数:512、256、128、64、カーネルサイズ:15、7、5、3)に通された。畳み込み層の後に、ドロップアウト率0.3のドロップアウト層を追加した。畳み込み特徴抽出と正規化の後、シーケンス特徴は時間分散型完全接続層に入力され、シグモイド活性化関数を使用して予測された結合確率がビットごとに出力されます。
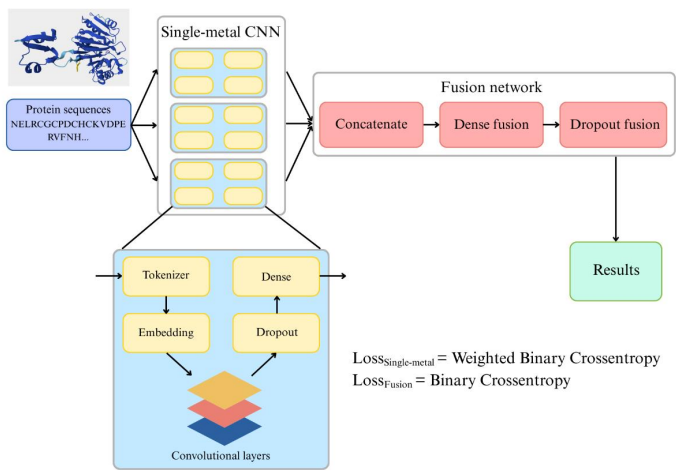
第二段階、研究チームは、複数の金属を統合した核融合ネットワーク(Fusionネットワーク)を設計しました。3種類の金属の予測値は、形状(Lmax, M)のテンソルに連結されます。ここで、Lmax = 500アミノ酸、M = 3金属チャネルです。このテンソルは、256個の隠れユニットとReLU活性化を持つ全結合層に入力され、各残基レベルで金属固有の特徴間の非線形相互作用を学習します。次に、ドロップアウト率0.2のドロップアウト層が導入され、融合重みを正規化し、過剰適合を防止します。最後に、M個のシグモイド出力が密層で使用され、各残基のZn、Fe、Mgの正確な結合確率が得られます。融合ネットワークは、損失関数として標準的なバイナリクロスエントロピーを使用し、Adamオプティマイザーでトレーニングすることで、相関誤差の補正方法を学習し、全体的な精度を向上させます。
さらに、このフレームワークのユニークな特徴は、完全にタンパク質配列データに依存しているため、構造への依存が排除されていることです。これにより、単一の NVIDIA A800 GPU でプロセス全体を 1 時間以内に完了できるようになり、その効率性により実験プロセスとリアルタイムのパラメータ調整が加速されます。
多次元的包括的実験評価
研究チームは多次元指標を用いて実験評価を実施した。この複合指標には、適合率、再現率、F1スコア、マシューズ相関係数(MCC)が含まれます。予測結合確率には決定閾値τが適用されます。残基の予測結合確率がτを超える場合、その残基は金属結合部位に分類され、そうでない場合は非金属結合部位に分類されます。単一の値のみを考慮する評価方法と比較して、この複合指標システムは、クラス不均衡シナリオにおけるフレームワークの真のパフォーマンスをより適切に反映します。
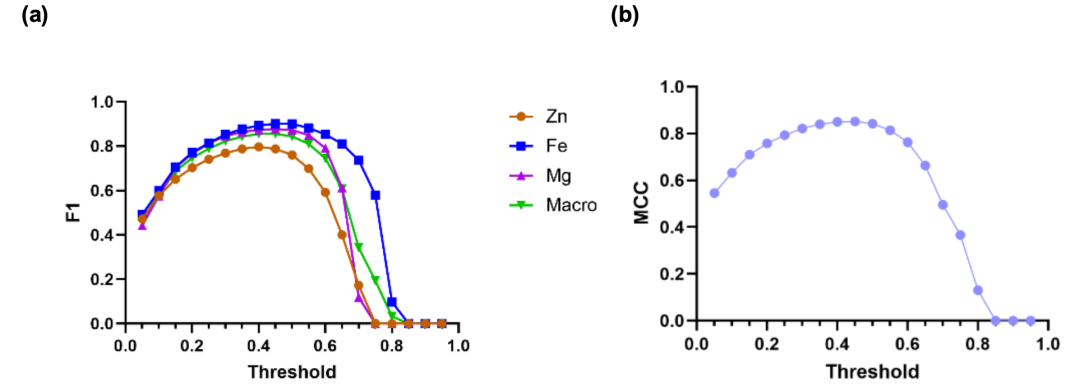
下の図(a)は、各金属とマクロ平均F1スコアおよび決定閾値τの関係を示しています。結果から、τ値が0.25~0.60の範囲でF1スコアが0.81を超え、Feの予測性能が良好であることがわかります。ZnおよびMgの単一金属モデルも、τ = 0.25~0.50および0.25~0.60の範囲でF1スコアが0.79を超えています。全体として、閾値を0.40~0.45に設定すると、マクロ平均F1スコアは0.855でピークに達し、これはすべての金属の適合率と再現率のバランスをとるのに最適な選択です。図(b)はMCCと閾値の関係を示しており、クラスの不均衡が深刻な場合でも、フレームワークが良好なバランスを実現できることをさらに示しています。
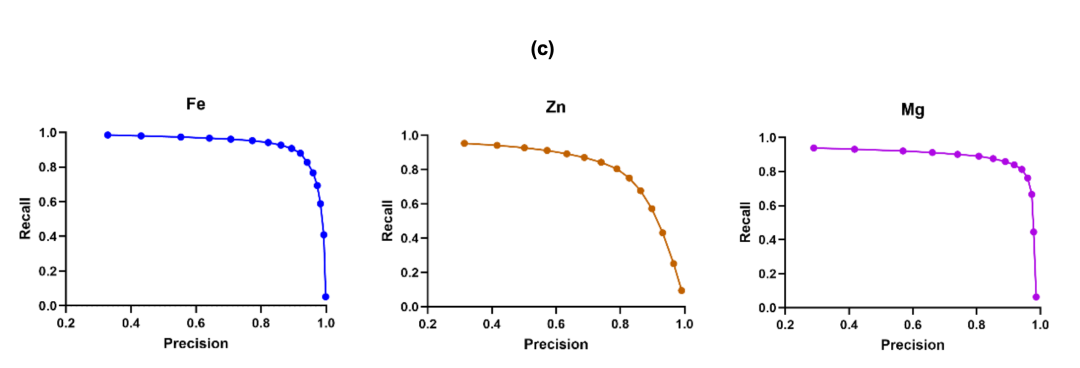
図(c)は、3種類の金属の適合率-再現率曲線を示しています。Feの予測は高い再現率で高い精度を維持しており、包括的なサイトスクリーニングに適していることを示しています。ZnとMgの予測指標も良好なパフォーマンスを示しており、中程度の高い再現率と持続的な適合率を必要とするアプリケーションにおいて、このフレームワークの堅牢性を示しています。
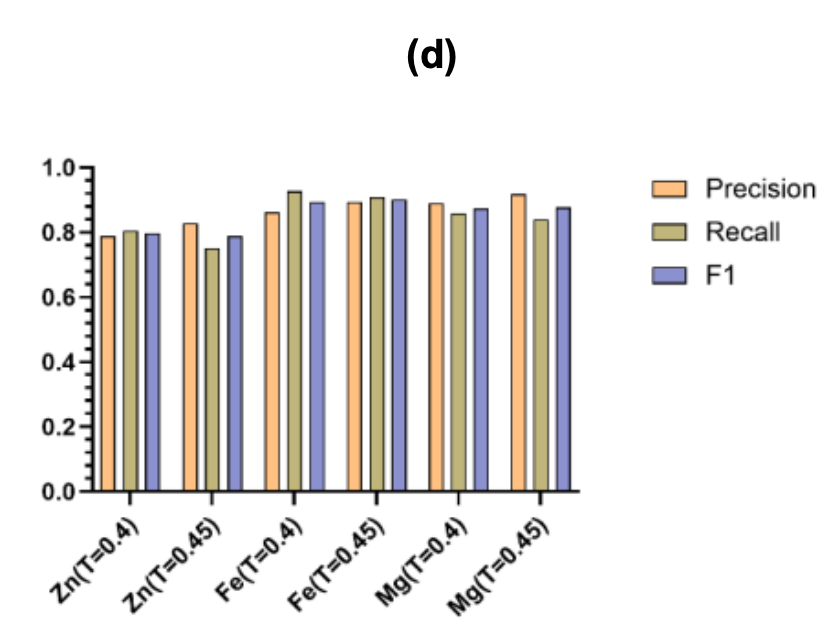
最後に、図(d)は、τ = 0.40と0.45という2つの最適な閾値における、さまざまな金属の予測の精度、再現率、およびF1スコアを示しています。結果は、このフレームワークが様々な金属の特性に応じて柔軟に調整可能であることを示しています。カバレッジ優先のスクリーニングシナリオに使用できるだけでなく、高精度な実験検証のニーズにも応えることができます。
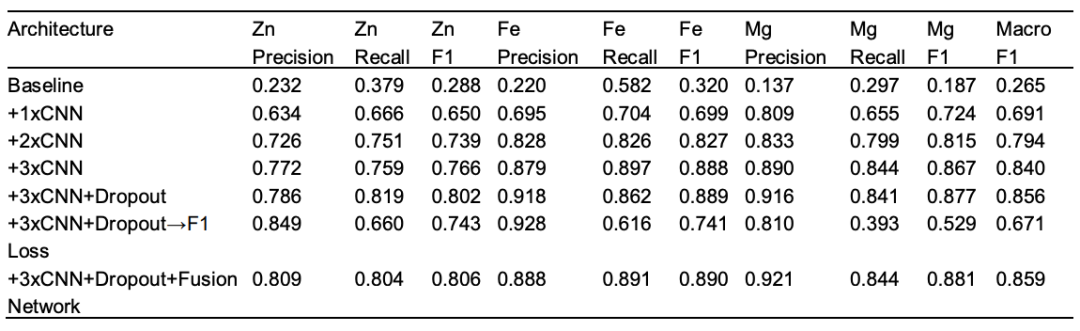
各建築コンポーネントの貢献を評価するために、研究チームは体系的なアブレーション実験も実施し、次の 2 つのコア設計原則を検証しました。(1)加重バイナリクロスエントロピー損失関数は、金属結合部位予測におけるクラス不均衡問題の処理に不可欠です。(2)融合ネットワークアーキテクチャは、予測の一貫性を高め、個々のモデルでは独立して利用できない金属間の関係を捉えます。
最も基本的な単一CNN層から開始した場合、平均F1はわずか0.265でした。畳み込み層を増やすことでパフォーマンスは大幅に向上し、3層CNNでは平均F1が0.840に増加し、階層的特徴抽出の重要性を実証しました。ドロップアウトを導入することでF1は0.856に増加し、過学習を防ぎ、汎化を向上させました。クラスの不均衡に対処するため、研究チームは重み付きバイナリクロスエントロピー損失関数を設計し、全体的な精度を犠牲にすることなく再現率を大幅に向上させました。最後に、融合層を追加することで平均F1はさらに0.859に向上しました。この融合層は金属間の依存関係を効果的にモデル化し、残留物レベルの予測の精度と堅牢性を向上させます。
金属-タンパク質相互作用マイニングを加速する新しいエンジン
この新たなフレームワークは金属タンパク質のアノテーションを進歩させ、金属-タンパク質相互作用の解析を加速させる重要なエンジンとなりつつあります。生物学における金属-タンパク質相互作用の探究の重要性は否定できず、この研究分野は大きな注目を集めています。様々な研究チームの研究者が、様々な視点から新たなアプローチとツールを積極的に模索しています。以下に、2つの優れた成果をご紹介します。
スイス連邦工科大学ローザンヌ校(EPFL)が開発した2つのツール、Metal3DとMetal1Dは、タンパク質構造における亜鉛イオンの位置予測精度を向上させるために開発されました。Metal3Dフレームワークは、トレーニングデータを変更することで他の金属にも拡張可能です。関連研究「Metal3D:タンパク質における金属イオンの位置予測精度向上のための汎用ディープラーニングフレームワーク」がNature Communications誌に掲載されました。
用紙のアドレス:
https://www.nature.com/articles/s41467-023-37870-6
arXivに掲載された「腫瘍タンパク質-金属結合のための解釈可能なマルチモーダル学習:進歩、課題、そして展望」と題された研究は、機械学習を用いた腫瘍タンパク質-金属結合の予測における最新の進歩と課題を体系的にまとめています。また、効率的な金属医薬品の設計に向けて、タンパク質間相互作用データを統合して金属結合の構造的知見を得ること、そして金属結合後の腫瘍タンパク質の構造変化を予測することという、2つの有望な方向性を提示しています。
用紙のアドレス:
https://arxiv.org/abs/2504.03847
参考リンク:
1.https://pubs.acs.org/doi/10.1021/cr300014x








