Command Palette
Search for a command to run...
Meta AI らは、反復的な情報交換を可能にし、複数のタスクで SOTA パフォーマンスを実現する新しいタンパク質動的融合特性評価フレームワーク FusionProt を提案しました。
タンパク質は生命機能の実行者であり、その謎は次の 2 つの側面に存在します。1 つはアミノ酸が端から端までつながって形成される 1 次元 (1D) 配列であり、もう 1 つは配列が折り畳まれて巻き付くことで形成される 3 次元 (3D) 構造です。従来のモデルは、ProteinBERTやESMのようなタンパク質言語モデル(PLM)のように「配列言語」を習得するか、GearNetのような3次元タンパク質表現技術のように「構造形態」を識別するか、どちらか一方に特化するのが一般的でした。モデルがこれら2つを組み合わせようとする場合でも、単純化された統合的なアプローチが採用されることが多く、それぞれの専門家が協調的ではなく独立して動作しているように見えます。
このような背景から、テクニオン・イスラエル工科大学とMeta AIの研究チームは共同で、タンパク質表現学習フレームワークFusionProtを提案しました。タンパク質の1次元配列と3次元構造の統一された表現を同時に学習することを目的としています。この研究では、タンパク質言語モデル(PLM)と3D構造グラフ間の適応的な橋渡しとして、学習可能な融合トークンを革新的な方法で導入し、両者間の反復的な情報交換を可能にしました。FusionProtは、タンパク質関連の様々な生物学的タスクにおいて最先端の性能を達成しています。
関連研究は、「FusionProt: タンパク質表現の統合学習のための配列と構造情報の融合」というタイトルで bioRxiv に掲載されました。
研究のハイライト:
* FusionProt フレームワークは、1 次元と 3 次元のモダリティを効果的に統合することで、従来の構造断片化処理の限界を打ち破り、タンパク質の機能と相互作用特性を捕捉する精度を向上させます。
* 学習可能な融合トークンを使用して、タンパク質言語モデル (PLM) とタンパク質 3D 構造グラフ間の反復的な情報交換を可能にする、新しいクロスモーダル融合アーキテクチャ。
* FusionProt は、複数のタンパク質タスクで最先端のパフォーマンスを実現し、ケーススタディを通じて実際の生物学的シナリオへのモデルの適用可能性を実証します。
用紙のアドレス:
公式アカウントをフォローし、「FusionProt」と返信すると完全なPDFが手に入ります。
AIフロンティアに関するその他の論文:
https://hyper.ai/papers
公開されているタンパク質データベースを使用してデータセットを体系的に構築する
本研究では、研究チームは公開されているタンパク質データベースを最大限に活用し、体系的なデータセット構築、厳密なデータ分割戦略、およびマルチタスク評価フレームワークを通じて、FusionProtが複数のタンパク質理解タスクで有効であることを保証しました。
事前トレーニング段階では、この研究ではタンパク質構造データベース (AlphaFold DB) をコアデータソースとして使用しました。このデータベースには、AlphaFold2によって予測された805,000件の高品質な3次元タンパク質構造が含まれています。研究者がこのデータセットを選択した主な理由は以下のとおりです。第一に、AlphaFold2は現在、タンパク質構造予測における最先端モデルとして認められており、その予測は非常に信頼性が高いため、外部の実験構造データの品質と入手可能性への依存を効果的に低減できます。第二に、統一された予測構造を使用することで、データソース間の一貫性が確保され、SaProtやESM-GearNetといった過去の最先端研究との公平な比較が容易になります。
研究チームはさらに、3つの信頼性の高い下流タスクにおいてモデルの性能を体系的に評価しました。これらのタスクでは、信頼性の高いデータ分割機能を提供するDeepFRIのデータセットを使用し、Fmaxを統一的な評価指標として用いることで、酵素機能アノテーションと遺伝子オントロジー推論におけるモデルの性能を包括的に測定しました。変異安定性予測(MSP)タスクでは、ESM-GearNetと同じデータセットと評価プロトコルを用い、AUROCを評価指標として用いて、変異がタンパク質複合体の安定性に及ぼす影響を予測するモデルの能力を評価しました。
「フュージョントークン」による反復的な情報交換メカニズム
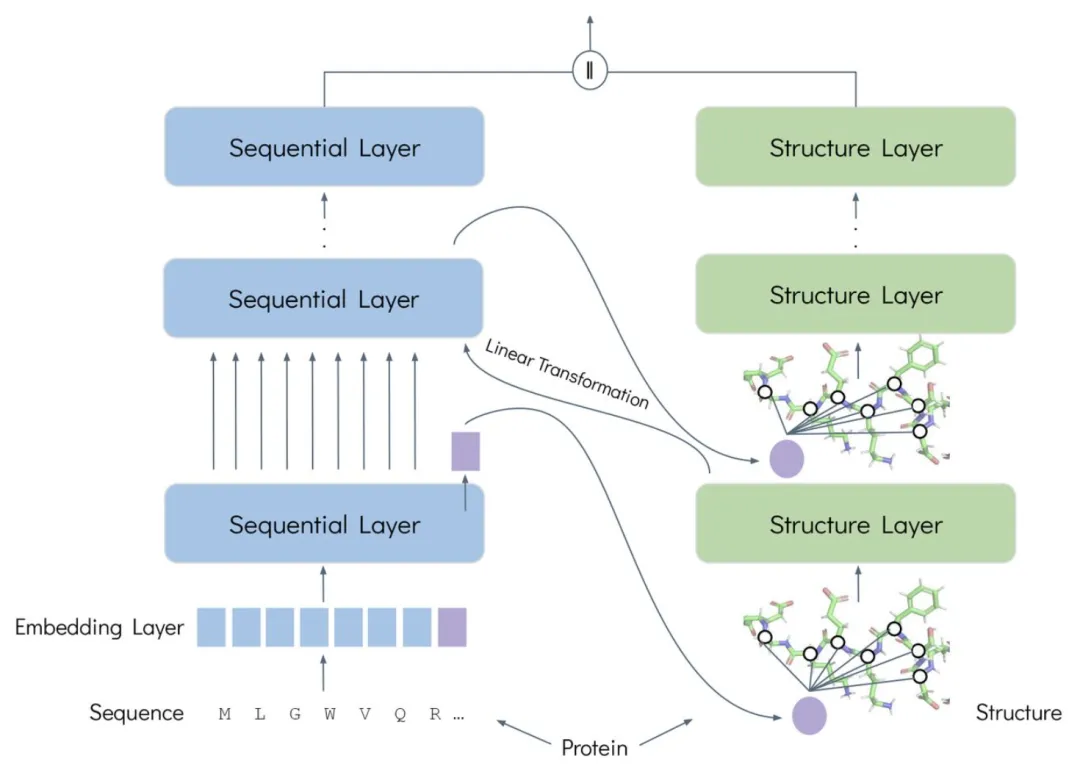
FusionProt の設計は、次の核となるアイデアを中心に展開されています。学習可能な融合トークンを通じて、タンパク質配列と構造の間の双方向の反復的なクロスモーダル相互作用の橋渡しとして機能します。これにより、2 種類の情報の深い融合と統一された表現が実現されます。
まず、このフレームワークは「配列-構造」デュアルモーダル並列エンコードアーキテクチャを基盤として構築されています。配列レベルでは、ESM-2をタンパク質言語モデルとしてアミノ酸配列をエンコードし、構造レベルではGearNetエンコーダを構造モデルとしてタンパク質の三次元構造図をモデリングします。学習可能な融合トークンは、学習プロセス中に二つのモダリティ間を動的に行き来することで、反復的な情報交換と融合を可能にします。配列レベルでは、融合トークンはタンパク質配列に接続され、アミノ酸は関連する固有の融合トークンを照会して貴重な情報を抽出・統合します。構造レベルでは、融合トークンはタンパク質の三次元グラフに追加され、ノードとして統合・接続されます。構造層はメッセージパッシングニューラルネットワークによって処理され、融合トークンはグローバルな空間構造情報を統合します。
第二に、このフレームワークの核となる原動力は、反復的な融合アルゴリズムにあります。このプロセスでは、融合トークンを更新された配列に組み込み、構造層に渡して構造グラフネットワークに新しいノードとして投入します。更新された融合トークンは、次のインタラクションラウンドのために配列層にフィードバックされます。この反復プロセスは、学習可能な線形変換を通じて、異なるモーダル空間を整合・調整します。この反復プロセスを通じて、モデル表現が統合され、統一されたリッチなタンパク質表現が形成されます。
最後に、FusionProt は事前トレーニングの目標として Multiview Contrastive 学習を使用します。連続するサブシーケンスをランダムに選択し、15%のグラフエッジを非表示にすることで、多様なビューが構築されます。次に、InfoNCE損失関数を使用して、潜在空間内の表現を整列させ、低次元潜在空間にマッピングされたときに関連するタンパク質サブコンポーネントの類似性を維持します。実装では、研究チームは上記のAlphaFold DBデータベースで事前トレーニングを実行しました。事前トレーニング中、FusionProtは学習率2e-4、グローバルバッチサイズ256タンパク質を使用し、50ラウンドのトレーニングを実施しました。入力シーケンスは、長いタンパク質シーケンスに対応するために1,024トークンに切り捨てられました。さらに、タスク固有の分類ヘッド予測を追加し、最新のSaProtモデルと同じハイパーパラメータを評価することで、微調整を実行しました。すべての実験は4 x NVIDIA A100 80GB GPUで実行され、1回の事前トレーニングセッションには約48時間かかりました。
既存のSOTAを総合的に凌駕する融合機構は大きな効果を発揮する
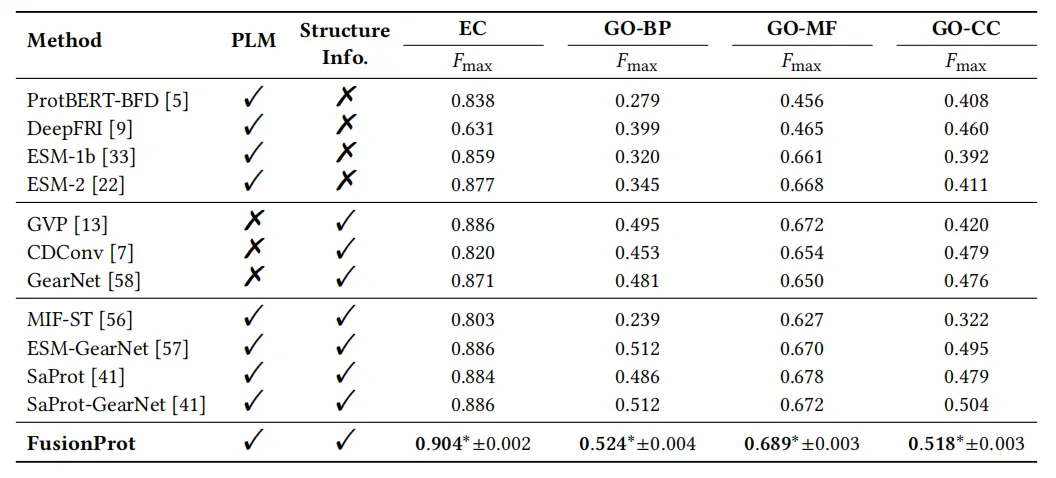
この研究は、複数の下流タスクで広範囲にテストされました。結果は、FusionProt フレームワークが複数のベンチマークで SOTA パフォーマンスを達成したことを示しています。実験結果を下の図に示します。
EC数予測評価において、研究チームはFusionProtの性能を11のベースラインモデルと比較しました。その結果、FusionProtは最高のFmax = 0.904を達成し、配列のみに依存するモデル(ProtBERT-BFD、0.838、ESM-2、0.877など)を大幅に上回り、構造情報のみを使用するGearNet(0.871)も上回りました。同時に、これら2種類の情報を活用しようとする他の手法(MIF-ST、ESM-GearNetなど)と比較しても、依然として優位に立っています。この結果は、あるモダリティを別のモダリティの文脈として単純に用いる場合と比較して、FusionProtの反復的な融合メカニズムは重要な3次元構造情報をより完全に保持し、触媒活性を左右する微妙な構造の違いをより正確に捉えることができることを示しています。
GO 用語予測評価では、FusionProt は生物学的プロセス、分子機能、細胞成分の 3 つのサブタスクで最高の結果を達成し、配列と構造の共同モデリングにおける学習可能な融合トークンの有効性を改めて実証しました。
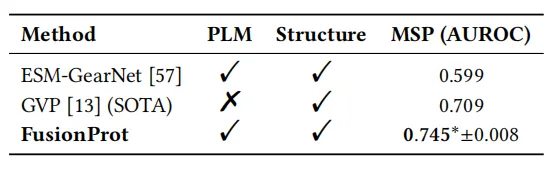
研究チームは、変異安定性予測の評価も行いました。実験結果では、FusionProtが評価対象とした全ての手法の中で最高のAUROC(平均オーロカ係数)を達成し、統計的有意性(p < 0.05)を示しました。この性能は、現在の最先端手法であるGVPと比較して5.11 TP3Tも大幅に向上しており、反復的な融合メカニズムが長距離配列構造依存性の統合に有効であることを示しています。さらに、FusionProtは学習可能な融合トークンを介して双方向のクロスモーダルインタラクションを可能にし、タンパク質表現をより表現力豊かで生物学的根拠に基づいたものにします。
FusionProtの主要設計の有効性を評価するため、研究チームはさらなるアブレーション実験を実施しました。チームは異なる融合注入頻度でシステムをテストし、融合マーカーが標準頻度で配列エンコーダーと構造エンコーダー間の相互作用を複数回実行した場合に最適なパフォーマンスが達成され、相互作用頻度を下げるとパフォーマンスが大幅に低下することを発見しました。これは、クロスモーダル依存関係を捉えるには頻繁な情報交換が重要であることを示しています。
最後に、生物学的なケース解析において、FusionProtはRNAポリメラーゼωサブユニットタンパク質のEC番号を予測することに成功しました。これは従来の手法では扱いが困難でした。この結果はESM-2などのモデルでは全く当てはまりませんでしたが、学習された表現が複雑な「構造と機能」の関係を捉えることができ、医薬品開発やタンパク質機能解析における幅広い応用の可能性を示していることをさらに証明しました。
クロスモーダル融合は明らかなトレンドとなっている
FusionProtはタンパク質表現学習の新たな道を切り開き、タンパク質の「言語」と「形態」は互いにではなく、互いにコミュニケーションをとるべきであることを実証しました。生命科学における人工知能の継続的な進歩に伴い、クロスモーダル融合は明確なトレンドとなっています。
ウェストレイク大学は、構造を考慮した語彙の概念を提唱し、アミノ酸残基トークンと構造トークンを組み合わせて、約4,000万個のタンパク質配列と構造のデータセットを用いて、大規模な汎用タンパク質言語モデルSaProtを学習しました。このモデルは、10の重要な下流タスクにおいて、既存のベースラインモデルを総合的に上回る性能を示しました。関連研究「SaProt:構造を考慮した語彙によるタンパク質言語モデリング」は、ICLR 2024に選出されました。
用紙のアドレス:
https://openreview.net/forum?id=6MRm3G4NiU
モントリオール大学とMilaが共同で発表した「構造整合型タンパク質言語モデル」では、対照学習を用いて構造情報を組み込んだ構造整合型タンパク質言語モデルが提案されています。このモデルは、予測された構造トークンを最適化することで、タンパク質接触予測タスクのパフォーマンスを大幅に向上させます。
用紙のアドレス:
https://arxiv.org/abs/2505.16896
2023年から2024年にかけてのAI4S分野の高品質な論文と詳細な解釈記事をワンクリックで入手⬇️









