Command Palette
Search for a command to run...
AAAI 2025に選出されました!医療画像セグメンテーションにおけるソフト境界と共起の問題を解決するために、中国地質大学らは画像セグメンテーションモデルConDSegを提案した。
医療画像のセグメンテーションは、医療画像処理の分野における重要かつ複雑なステップです。主に医療画像から特別な意味を持つ部分を抽出し、臨床診断、リハビリテーション治療、病気の追跡をサポートします。近年、コンピュータと人工知能のサポートにより、ディープラーニングに基づくセグメンテーション手法が徐々に医療画像セグメンテーションの主流となり、関連する成果も盛んになってきました。
人工知能に関する最高峰の国際会議である第39回AAAI人工知能年次会議(AAAI 2025)で発表された選ばれた成果の中には、医療画像の自動セグメンテーションにおける実りある進歩を改めて示す論文がいくつかありました。その成果の一つである「ConDSeg: コントラスト主導の特徴強化による汎用医療画像セグメンテーションフレームワーク」は、中国地質大学と百度のチームが共同で発表し、大きな注目を集めた。
医用画像セグメンテーションの分野における「ソフト境界」と共起現象という 2 つの大きな課題に対処するために、研究者らはコントラスト駆動型医用画像セグメンテーション用の ConDSeg と呼ばれる一般的なフレームワークを提案しました。このフレームワークは、一貫性強化 (CR) トレーニング戦略、セマンティック情報分離 (Semantic Information Decoupling、SID) モジュール、コントラスト駆動型特徴集約 (Contrast-Driven Feature Aggregation、CDFA) モジュール、サイズ認識デコーダー (Size-Aware Decoder、SA-Decoder) などを革新的に導入し、医療画像セグメンテーション モデルの精度をさらに向上させます。
用紙のアドレス:
https://arxiv.org/abs/2412.08345
オープンソース プロジェクト「awesome-ai4s」は、200 を超える AI4S 論文の解釈をまとめ、膨大なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
医療画像のセグメンテーション精度は2つの大きな課題に直面している
過去 10 年間で、人工知能の台頭により、医療画像の自動セグメンテーションが急速に発展し、医師や研究者は面倒な作業から解放されました。しかし、医療画像の複雑さと専門性を考えると、完全に自動化された画像セグメンテーションを実現するにはまだ長い道のりがあり、精度は無視できない重要な課題です。精度が失われると、自動化は不可能になるからです。
現在の視点から見ると、医療画像における「ソフト境界」と共起現象は、医療画像のセグメンテーション精度の向上を妨げる主な問題です。
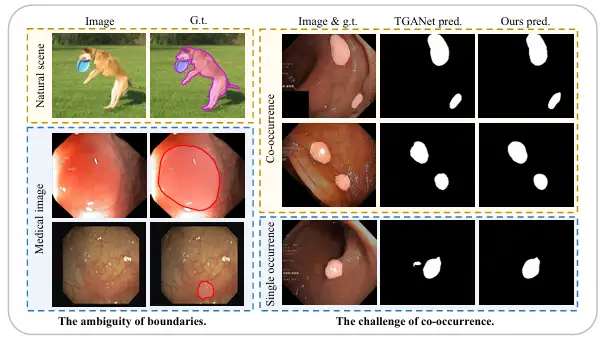
まず、前景と背景の境界が明確な自然画像と比較すると、医療画像では、前景(ポリープ、腺、病変など)と背景の間に曖昧な「ソフト境界」があることがよくあります。その主な理由は、病理組織と周囲の正常組織の間に遷移領域があり、境界を定義するのが難しいためです。さらに、ほとんどの場合、医療画像に見られる照明効果の悪さとコントラストの低さにより、病理組織と正常組織の境界がさらに不明瞭になり、境界を区別することがさらに困難になります。
第二に、自然界にランダムに現れる物体とは異なり、医療画像内の臓器や組織は高度に固定され規則的であるため、医療画像に異なる画像特徴、組織、または病変が同時に現れるという共起現象も広く見られます。たとえば、内視鏡によるポリープ画像では、小さなポリープが同様の大きさのポリープと一緒に現れることが多いため、モデルはポリープとは関係のない特定の共起特徴を非常に簡単に学習できます。ただし、病理組織が単独で現れる場合、モデルは正確な予測を行うことができないことがよくあります。
上記の課題に対処するために、近年、これに焦点を合わせた研究方法がますます増えています。例えば、深圳大学医学部バイオメディカル工学部の岳光輝准教授のチームは、正確なポリープのセグメンテーションに使用できる境界制約ネットワーク BCNet を発表しました。このネットワークでは、浅いコンテキスト特徴、高レベルの位置特徴、および追加のポリープ境界監視を組み合わせることで境界を捉えることができる両側境界抽出モジュールについて言及しています。この結果は、「ポリープのセグメンテーションのためのクロスレイヤー機能統合による境界制約ネットワーク」というタイトルで IEEE Journal of Biomedical and Health Informatics に掲載されました。
用紙のアドレス:
https://ieeexplore.ieee.org/document/9772424
例えば、上海科技大学バイオメディカル工学部の初代学部長である沈丁岡教授らのチームは、ポリープのセグメンテーションに使用できるクロスレベル特徴集約ネットワーク CFA-Net を提案しました。このネットワークは、境界認識特徴を生成する境界予測ネットワークを設計し、階層的戦略を使用してこれらの特徴をセグメンテーション ネットワークに統合します。この結果は、「ポリープセグメンテーションのためのクロスレベル特徴集約ネットワーク」というタイトルで Pattern Recognition に掲載されました。
用紙のアドレス:
https://www.sciencedirect.com/science/article/abs/pii/S0031320323002558
しかし、これらの方法はすべて、境界関連の監督を明示的に導入することで境界に対するモデルの注意力を向上させますが、あいまいな領域における不確実性を自発的に削減するモデルの能力を根本的に強化することはできませんでした。したがって、過酷な環境では、これらの方法の堅牢性は依然として弱く、モデルのパフォーマンスを向上させるには依然として限界があります。同時に、前景と背景、および画像内の異なるエンティティを正確に区別できないことは、ほとんどのモデルが直面している問題のままです。
これまでの方法とは異なり、中国地質大学と百度のチームが実施した研究で、研究者らはコントラスト主導の医療画像セグメンテーションのための「ConDSeg」と呼ばれる一般的なフレームワークを提案した。具体的なイノベーションは次のとおりです。
* 過酷な環境での堅牢性テストに対応して、研究者は、エンコーダーの堅牢性を高め、高品質の特徴を抽出するための一貫性強化 (CR) 事前トレーニング戦略を提案しました。同時に、セマンティック情報分離 (SID) モジュールは、特徴マップを前景、背景、不確実な領域に分離し、特別に設計された損失関数を通じてトレーニング中に不確実性を減らすことを学習できます。
* 提案されたコントラスト駆動型特徴集約 (CDFA) モジュールは、SID によって抽出されたコントラスト特徴を通じて、多層特徴の融合と強化をガイドします。サイズ認識デコーダー (SA デコーダー) は、画像内のさまざまなエンティティをより適切に区別し、異なるサイズのエンティティを個別に予測して、共通の特徴の干渉を克服することを目的としています。
ConDSegの4つの主要なイノベーションにより、医療画像のセグメンテーション精度が向上
全体、この研究で提案された ConDSeg は、2 段階アーキテクチャを備えた一般的な医療画像セグメンテーション フレームワークです。以下に示すように:
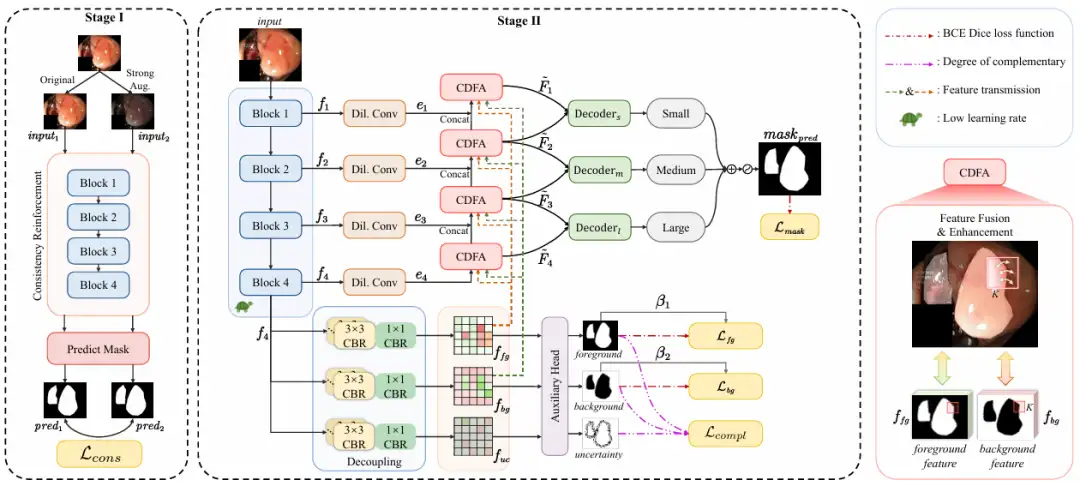
第一段階では、この研究の目的は、低照度および低コントラストのシーンにおけるエンコーダの特徴抽出能力と堅牢性を最大化することです。
研究者らは、エンコーダーの予備トレーニングを実行するための CR 事前トレーニング戦略を導入し、エンコーダーをネットワーク全体から分離し、単純な予測ヘッド (Predict Mask) を設計しました。元の画像 (Original) と強調された画像 (Strong Aug.) をエンコーダーに入力することで、予測されたマスク間の一貫性が最大化され、さまざまな照明やコントラストの課題に対するエンコーダーの堅牢性が強化され、過酷な環境で高品質の特徴を抽出する能力が向上します。強化方法には、明るさ、コントラスト、彩度、色相をランダムに変更するだけでなく、ランダムにグレースケール画像に変換したり、ガウスぼかしを追加したりすることが含まれます。
研究チームが提案した一貫性損失 Lcons は、ピクセルレベルの分類精度に基づいて設計されていることも特筆に値します。これは、単純な 2 値化操作とバイナリ クロスエントロピー (BCE) 損失計算を使用して、予測されたマスク間のピクセルレベルの違いを直接比較します。この方法は計算が簡単で数値的不安定性を回避できるため、大規模データに適しています。
第二段階では、ネットワーク全体を微調整し、エンコーダの学習率を低く設定します。4 つのステップに分かれています。
* 特徴抽出、ResNet-50 エンコーダーは、異なるレベルで異なる意味情報を持つ特徴マップ f₁ から f₄ を抽出します。
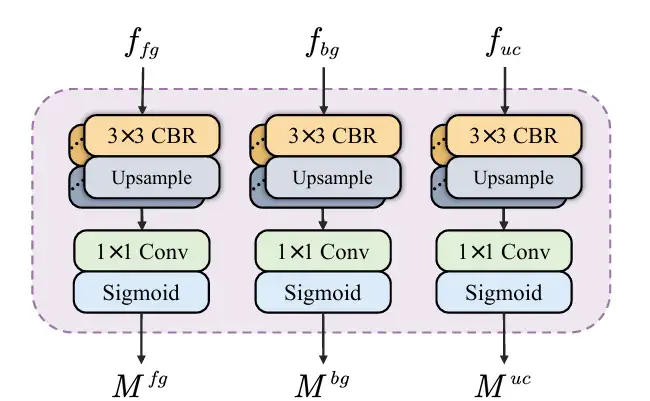
* 意味情報の分離: 深い意味情報を持つ特徴マップ f₄ が SID に入力され、前景、背景、不確実な領域の情報を含む特徴マップに分離されます。 SID は、それぞれ複数の CBR モジュールで構成される 3 つの並列ブランチから開始されます。特徴マップ f₄ が 3 つのブランチに入力されると、それぞれ前景、背景、不確実領域の特徴が強化された、異なる意味情報を持つ 3 つの特徴マップが取得されます。次に、補助ヘッドが 3 つの特徴マップを予測し、前景、背景、不確実領域のマスクを生成します。損失関数の制約により、SID 学習は不確実性を低減し、前景と背景の間のマスク精度を向上させます。次の図に示すように:
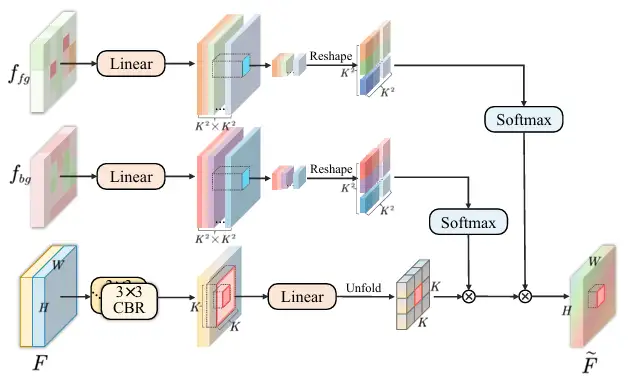
* 特徴集約: 特徴マップ f₁ から f₄ が CDFA モジュールに入力され、分離された特徴マップに基づいてマルチレベルの特徴マップが徐々に融合され、前景と背景の特徴の表現が強化されます。 CDFA は、SID によって分離された前景と背景のコントラスト特徴を使用してマルチレベルの特徴融合をガイドするだけでなく、セグメント化されるエンティティと複雑な背景環境をモデルがより適切に区別できるようにもします。次の図に示すように:
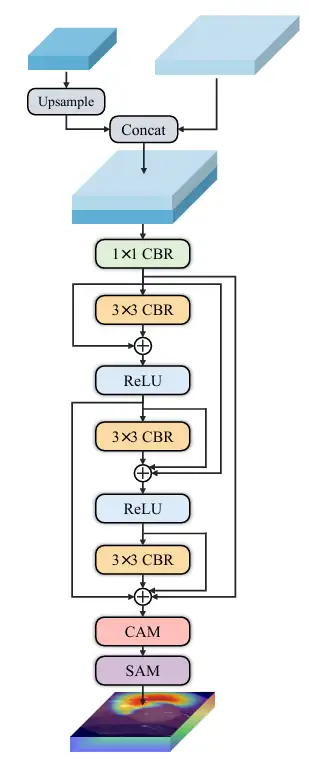
* マルチスケール予測では、研究者らは小、中、大サイズの 3 つのデコーダーを構築しました。デコーダー ₛ、デコーダー ₘ、デコーダー ₗ はそれぞれ特定のレベルで CDFA からの出力を受け取り、サイズに応じて画像内の複数のエンティティを見つけます。各デコーダーの出力は統合されて最終的なマスクが生成されるため、モデルは大きなエンティティを正確にセグメント化し、小さなエンティティを正確に配置することができ、共起現象が誤って学習されることを防ぎ、デコーダーのスケール特異点の問題を解決します。次の図に示すように:
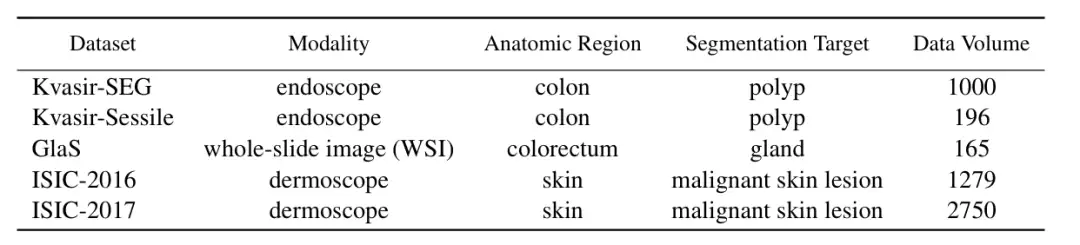
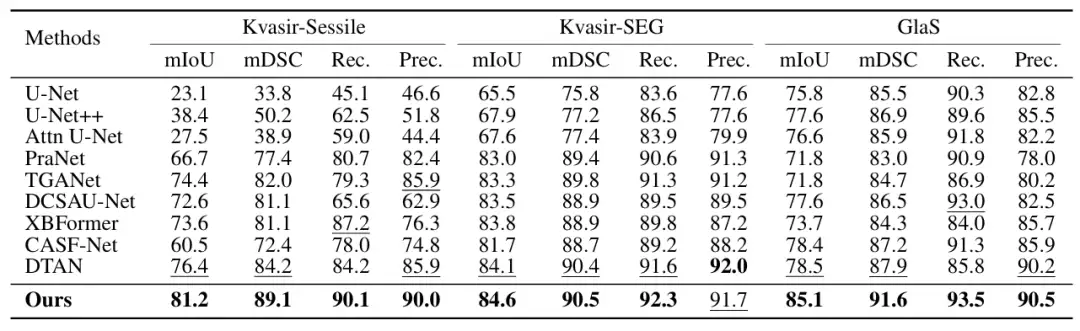
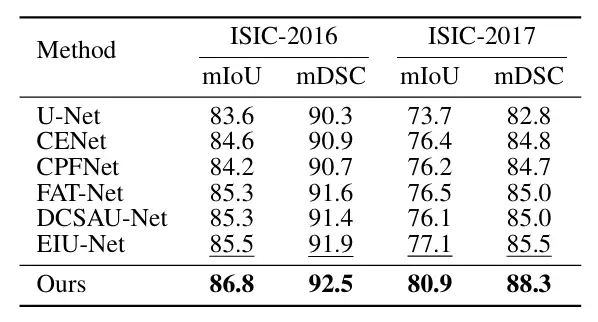
医療画像セグメンテーション分野におけるConDSegの性能を検証するために、研究者らは、3 つの医療画像タスク (内視鏡検査、全スライス画像、皮膚鏡検査) をテストするために、5 つの公開データセット (Kvasir-SEG、Kvasir-Sessile、GlaS、ISIC-2016、ISIC-2017、下図参照) を選択しました。研究者らは画像のサイズを 256 × 256 ピクセルに変更し、バッチ サイズを 4 に設定しました。最適化には Adam オプティマイザーが使用されました。
主な比較対象には、U-Net、U-Net++、Attn U-Net、CENet、CPFNet、PraNet、FATNet、TGANet、DCSAUNet、XBoundFormer、CASF-Net、EIU-Net、DTAN などの最先端の方法が含まれます。結果は、提案された方法が 5 つのデータセットすべてで最高のセグメンテーション パフォーマンスを達成することを示しています。以下に示すように:
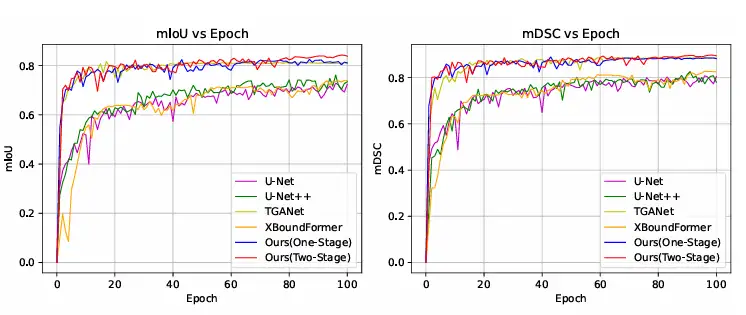
さらに、研究者らは、Kvasir-SEG データセットでトレーニング収束曲線を他の方法と比較しました。結果は、ConDSeg は 1 段階のトレーニングだけでも高度なレベルに到達できることを示しており、完全な ConDSeg フレームワークを使用した場合、この方法は最速の収束速度と最高のパフォーマンスを達成しました。下の図の通りです。
医療画像のセグメンテーションは資本と技術のホットな話題となっている
医療画像のセグメンテーションは、臨床医学と医学研究の両方で重要な役割を果たしています。特別に訓練された AI システムは、その高い効率性とインテリジェンスによって従来の医療画像のセグメンテーション手法を変革し、医療スタッフや科学研究者にとって欠かせない補助ツールとなっています。医療画像セグメンテーションがこのような発展と成果を達成できたのは、資本と技術という二重の原動力によるものです。
資金面では、AIとバイオメディカルの学際分野が近年投資界で話題となっており、今年はAI駆動型医療画像が好調なスタートを切る先頭に立った。 1月28日、スペインの医療用画像機器会社Quibimは5,000万米ドル(約3億6,000万人民元)のシリーズA資金調達を完了したと発表した。 Quibim のコア技術は、医療画像データに基づく人工知能分析であり、同社の QP-Liver はびまん性肝疾患の MR 診断用の自動セグメンテーション ツールであることは特筆に値します。
技術面では、AIと医療画像セグメンテーションの組み合わせは、長い間、主要な研究室の研究焦点の1つでした。たとえば、マサチューセッツ工科大学のコンピューターサイエンスおよび人工知能研究所 (MIT CSAIL) のチームは、マサチューセッツ総合病院およびハーバード大学医学部の研究者と共同で、インタラクティブな生物医学画像セグメンテーションの一般的なモデルである ScribblePrompt を提案しました。このモデルは、落書き、クリック、境界ボックスなどのさまざまな注釈方法を使用する注釈者が、トレーニングされていないラベルや画像タイプであっても、生物医学画像セグメンテーション タスクを柔軟に実行できるようにサポートします。
「ScribblePrompt: あらゆるバイオメディカル画像のための高速かつ柔軟なインタラクティブセグメンテーション」と題された関連成果は、最高峰の国際学術会議 ECCV 2024 に採択されました。
用紙のアドレス:
https://arxiv.org/pdf/2312.07381
さらに、オックスフォード大学のチームは、Meta がリリースした SAM 2 をベースに、医療画像を動画として扱う Medical SAM 2 (MedSAM-2) と呼ばれる医療画像セグメンテーション モデルを開発しました。このモデルは、3D 医療画像セグメンテーション タスクで優れたパフォーマンスを発揮するだけでなく、新しいシングル プロンプト セグメンテーション機能も実現します。ユーザーは新しい特定のオブジェクトのヒントを提供するだけで、後続の画像内の類似オブジェクトのセグメンテーションは、それ以上の入力なしにモデルによって自動的に完了されます。
つまり、AIはもはや棚上げの技術ではない。医療画像の自動セグメンテーションの開発は、バイオメディカル分野におけるAIの潜在力を裏付け、資本化のストーリーも次々と実証され、その商業的実現可能性も証明されている。将来、医療画像分野における最も重要なリンクとして、医療画像セグメンテーションは確実にAIの恩恵を受け、急速に発展するでしょう。医療画像セグメンテーションの分野での成功により、より広範なバイオメディカル市場に資本も投入され、技術、資本、ビジネスの完璧なクローズドループが実現します。








