Command Palette
Search for a command to run...
SAM 2 最新应用落地!牛津大学团队发布 Medical SAM 2,刷新医学图像分割 SOTA 榜
2023 年 4 月,Meta 公司发布了 Segment Anything Model (SAM),号称能够「分割一切」,犹如一颗重磅炸弹震荡了整个计算机视觉领域,甚至被很多人看作是颠覆传统 CV 任务的研究。
时隔 1 年多,Meta 再度发布里程碑式更新—— SAM 2 能够为静态图像和动态视频内容提供实时、可提示的对象分割,将图像与视频分割功能整合到了同一个系统中。可想而知,强大的实力使得业界开始加速探索 SAM 在不同领域的应用,尤其是在医学图像分割领域,不少实验室和学术研究团队已经将其视为医学图像分割模型的不二之选。
所谓医学图像分割,就是将医学图像中具有特殊含义的部分分割出来,并提取相关特征,进而为临床诊断、病理学研究等提供可靠依据。
近年来,随着深度学习技术的不断进步,基于神经网络模型的分割已逐渐成为医学图像分割的主流方法,自动化的分割方法大大提升了效率与准确性。然而,鉴于医学图像分割领域的特殊性,其中仍有一些挑战亟待解决。
首先是模型泛化,针对特定目标(如器官或组织)训练的模型很难适应其他目标,因此往往需要针对不同的分割目标重新开发相应的模型;其次是数据差异,许多为计算机视觉开发的标准深度学习框架都是为 2D 图像所设计,但在医学成像中,数据通常是 3D 格式,如 CT 、 MRI 以及超声图像等,这种差异无疑为模型训练造成了巨大的困扰。
为了解决上述问题,牛津大学团队开发了名为 Medical SAM 2 (MedSAM-2) 的医学图像分割模型,该模型基于 SAM 2 框架设计,将医学图像视作视频,不仅在 3D 医学图像分割任务上表现卓越,同时还解锁了一种新的单次提示分割的能力。用户只需为一种新的特定对象提供一个提示,后续图像中同类对象的分割就可以由模型自动完成,而无需进一步输入。
相关论文及成果目前以「Medical SAM 2: Segment medical images as video via Segment Anything Model 2」为题,已发表于预印本平台 arXiv 上。
研究亮点:
* 团队率先推出基于 SAM 2 的医学图像分割模型 MedSAM-2
* 团队采用了一种新颖的「medical-images-as-videos」的理念,解锁了「单次提示分割功能」

论文地址:
https://arxiv.org/pdf/2408.00874
SA-V 视频分割数据集直接下载:
Medical SAM 2 示例医学分割数据集:
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
数据集:分类设计,全面评估
团队通过使用自动生成的掩码提示,在 5 个不同的医学图像分割数据集上进行实验,这些数据集分为两类:
第一类旨在评估一般分割性能,团队选择了腹部多器官分割任务,选用 BTCV 数据集,包含 12 个解剖结构。
第二类旨在评估模型在不同成像模式中的泛化能力,研究人员使用 REFUGE2 数据集对眼底视盘 (Optic disc) 和视杯 (Optic Cup) 图像分割;使用 BraTs 2021 数据集对 MRI 扫描的脑肿瘤分割;使用 TNMIX 基准对超声图像进行甲状腺结节分割,该基准由 TNSCUI 的 4,554 张图像以及 DDTI 的 637 张图像组成;使用 ISIC 2019 数据集对皮肤病变图像进行黑色素瘤或痣分割。
此外,团队设置了 10 个额外的 2D 图像分割任务,通过使用不同类型的提示,进一步评估了模型的单次提示分割能力。具体来说,KiTS23 、 ATLAS23 、 TDSC 和 WBC 等数据集,采用点提示技术;SegRap 、 CrossM23 和 REFUGE 数据集,采用 BBox (bounding box) 提示;CadVidSet 、 STAR 和 ToothFairy 数据集采用掩码提示。
模型架构:针对不同维度医学图像的有效分割处理
MedSAM-2 的架构基本类似于 SAM 2,但研究团队同时为其构建了独特而高效的处理模块和管道,结合置信度记忆库 (Confidence Memory Bank) 和加权拾取策略 (Weighted Pick-up strategy),从技术上对模型的能力予以保障。
具体来说,MedSAM-2 的架构如下图所示,包含:
* 图像编码器 (Image Encoder),将输入抽象为嵌入
* 记忆注意力机制 (Memory Attention),用存储在记忆库中的记忆来调节输入嵌入
* 记忆编码器 (Memory Decoder),将预测帧嵌入抽象化
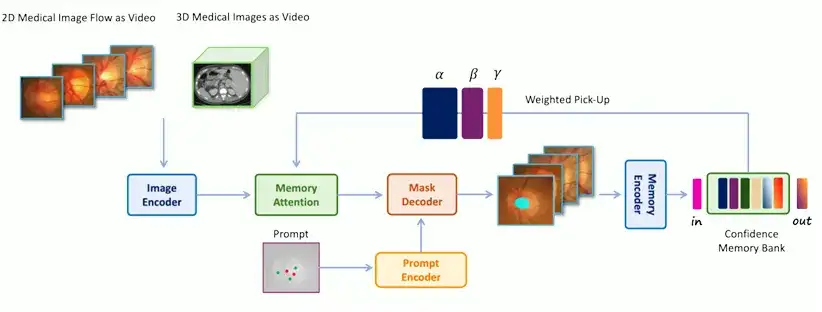
网络中的编码器和解码器与 SAM 中的编码器和解码器相似。编码器由分层视觉转换器组成,解码器包括集成了提示嵌入和图像嵌入的轻量级双向转换器,其中提示嵌入由提示编码器 (Prompt Encoder) 生成;记忆注意力组件由一系列堆叠的注意力块组成,每个块都包含自注意力块及交叉注意力机制。
值得注意的是,MedSAM-2 的一个重要创新在于将医学图像处理视作视频进行分割,这是提高 3D 医学图像分割性能和解锁「单次提示分割功能」的关键,为此团队还为 2D 和 3D 医学图像分别开发了两个不同的运行流程,以针对不同维度的医学图像进行有效的分割处理。
对于 3D 医学图像处理,因为 3D 医学图像中相邻切片之间存在很强的时间关联,其处理方式也类似于处理视频数据,利用 SAM 2 原本的存储系统来检索先前的切片及其相应预测,以进行连续切片分割,随后通过记忆注意力机制增强输入图像嵌入,并将分割结果添加回存储区,以辅助后续切片的分割。
对于 2D 医学图像处理,处理方式与 SAM 2 中使用的时间先进先出队列 (the temporal first-in-first-out queue) 不同,而是将包含相同器官或组织的一组医学图像分组为「医学图像流」,并采用「置信度优先」的存储区来存储模型的模板,根据模型预测的概率计算置信度,同时实施图像多样性约束。在合并输入图像嵌入和存储区信息时,采用加权选择策略。在训练阶段,使用校准头 (calibration head) 确保模型预测更准确。最终实现在没有时间关联的情况下,只需一个样本提示,就能实现对目标的自动分割。
实验结果:MedSAM-2 性能、泛化能力全面领先
研究团队使用了 IoU (Intersection over Union) 和 Dice Score 来评估模型在医学图像分割中的性能,同时引入 Hausdorff Distance (HD95) 度量确保性能评估的准确性。
* loU 也被称为 Jaccard 指数,是一种用于评估特定数据集上目标检测器准确性的度量。
* Dice Score 又称 Dice Coefficient,是比较两个样本之间相似性的统计工具。
* Hausdorff Distance (HD95) 度量是主要用于确定两组点之间差异程度的度量,通常用于评估图像分割任务中物体边界的准确性,对于量化预测分割和实况边界之间距离的最坏情况尤为有效。
首先,团队将 MedSAM-2 与一系列 SOTA 医学图像分割方法进行了基准测试,包括针对 2D 和 3D 医学图像的分割任务。对于 3D 医学图像,提示随机提供,概率为 0.25;对于 2D 医学图像,概率为 0.3 。
为了在 3D 医学图像上评估所提模型的一般性能,团队将 MedSAM-2 与 BTCV 多器官分割数据集上建立的先进分割方法进行了比较,包括知名的 nnUNET 、 TransUNet 、 UNetr 、 Swin-UNetr 模型以及 Diffusion-based 模型(如 EnsDiff 、 SegDiff 和 MedSegDiff)。此外团队还对原版 SAM,全微调 MedSAM 、 SAMed 、 SAM-Med2D 、 SAM-U 、 VMN 以及 FCFI 等交互式分割模型进行对比评估。性能使用 Dice Score 进行量化,结果如下图所示:
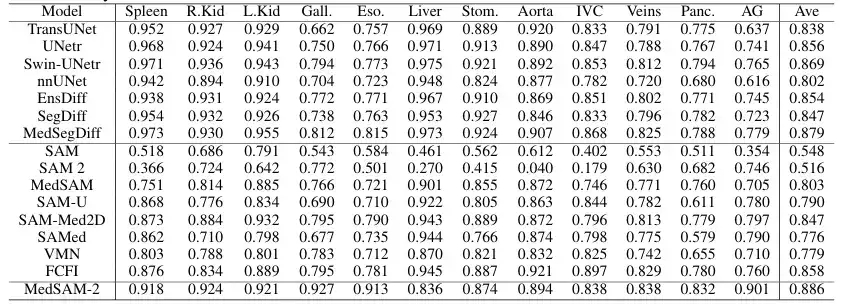
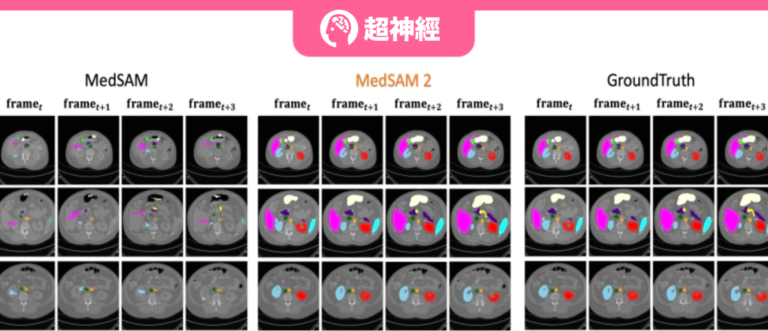
结果显示,MedSAM-2 相比之前的 SAM 和 MedSAM 进步显著。在 BTCV 数据集上,MedSAM-2 在多器官分割任务上实现了卓越的性能,达到了 88.57% 的最终 Dice 分数。在交互模型中,MedSAM-2 保持领先地位,比之前领先的交互式模型 Med-SA 的表现高出 2.78% 。所有这些交互式模型都需要每一帧给出提示,而 MedSAM-2 在给出较少提示的情况下取得了更好的结果。
在 2D 医学图像分割任务上,团队将 MedSAM-2 与针对不同图像模式的特定任务而定制的方法进行了比较。具体来看,针对视杯分割,与 ResUnet 和 BEAL 进行了比较;针对脑肿瘤分割,与 TransBTS 和 SwinBTS 进行了比较;针对甲状腺结节分割,与 MTSeg 和 UltraUNet 进行了比较;针对皮肤病变分割,与 FAT-Net 和 BAT 进行了比较。此外,团队还对交互式模型进行了基准测试,结果如下图所示:
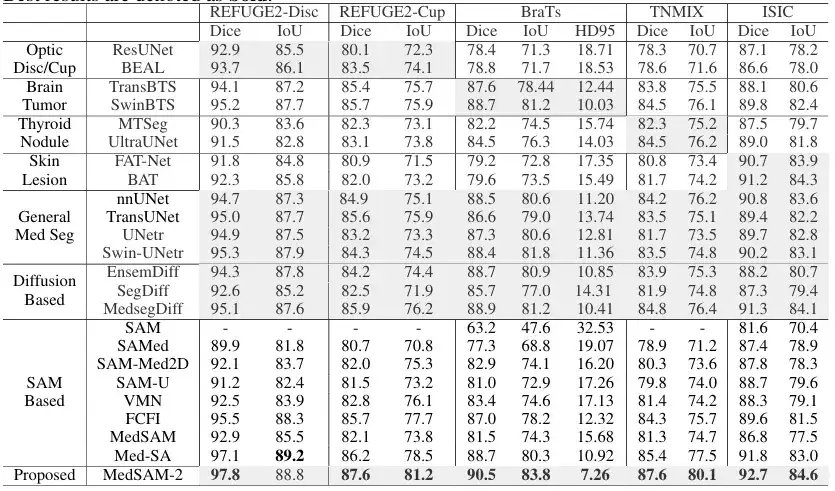
结果显示,MedSAM-2 在 5 个不同的任务中优于所有其他方法,展示了其在不同医学图像分割任务中卓越的泛化能力。具体来说,MedSAM-2 在视杯上实现了 2.0% 的改进,在脑瘤上实现了 1.6% 的改进,在甲状腺结节上实现了 2.8% 的改进。在交互式模型对比中,MedSAM-2 依旧保持性能领先。
最后,团队还评估了 MedSAM-2 在仅给出一个提示时的性能,并且顺序图像之间没有明确的联系,这进一步验证了 MedSAM-2 单次提示分割的能力。具体来说,团队将 MedSAM-2 与 PANet 、 ALPNeu 、 SENet 和 UniverSeg 进行了比较,所有模型测试期间均只给出一个提示。另外,团队还将 MedSAM-2 与单镜头模型如 DAT 、 ProbONE 、 HyperSegNas 以及 One-prompt 进行了比较。
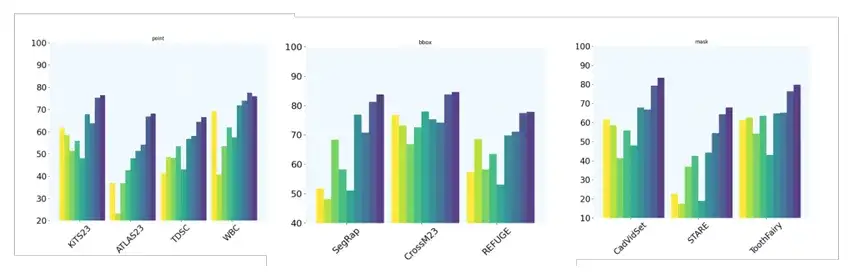
结果显示,MedSAM-2 展示出了跨各种任务的稳健泛化能力,即使与经过高强度训练的 One-prompt 相比,仍表现出色,在 10 个任务中的比较只有 1 个落了下风。另外在所有方法都提供掩码的场景中,MedSAM-2 显示出了更明显的优势,通常平均超过第二位 3.1%,是所有提示设置中最大的差距。
SAM 助力医学图像分割研究如火如荼
本次论文的发布可谓是对 SAM 及 SAM 2 在医学领域潜力的又一次深挖,为医学图像分割领域提供了一种全新的思路与方法,尤其是在临床应用中展现了极大的潜力和价值,能够大幅缩减医学图像分割的工作量,提升医学图像分割效率和精准度。
而更值得一提的是,正如文章开头所言,不少实验室和学术团队都在挖掘 SAM 的潜力,在医学图像分割赛道上,也不止本论文中所提的牛津大学团队。
无独有偶,就在 SAM 发布不久,深圳大学医学部生物医学工程学院倪东教授团队联合英国牛津大学、苏黎世联邦理工学院、浙江大学、深圳市人民医院和度影医疗等单位,就 SAM 在医学影像任务上的应用开启了全面、多角度的实验和评估。相关论文及成果以「Segment Anything Model for Medical Images?」为题,发表于国际医学图像分析领域的顶级期刊「Medical Image Analysis」上。

在这篇论文的研究中,相关团队最终构建了一个超大规模医学影像分割数据集 COSMOS 1050K,包含 18 种影像模态、 84 个生物医学领域分割目标、 1050K 2D 图像和 6033K 分割掩膜。基于该数据集,研究人员对 SAM 进行了全面评估,探索了提升 SAM 在医学目标感知方面的能力。
COSMOS 1050K 医学图像分割数据集直接下载:
除此之外,上海复旦大学大数据学院和上海交通大学生物医学工程学院的团队同样也对 SAM 在医学图像分割领域方面进行了一系列研究,相关论文以「Segment anything model for medical image segmentation: Current applications and future directions」为题,收录于 arXiv 、 Computer in Biology and Medicine 等知名学术网站和期刊上。

该论文则着重探讨了在自然图像分割中取得显著成就的 SAM 在医学图像分割领域的应用可能,并对探索了对 SAM 模块微调及类似架构的重新训练,以适应医学图像分。
论文地址:
https://www.sciencedirect.com/science/article/abs/pii/S0010482524003226
总而言之,正如以上论文所探讨的一样,科学家们通过对 SAM 潜力的发掘,将医学图像的处理和分析变得更加简单和高效,这无论对学术界、医学界甚至病人而言,都将是值得期待的结果。同时,像 SAM 这样的通用图像分割模型的发布,也是给各领域打开了一扇神奇的大门,相信不仅是医学影像领域,未来如自动驾驶、新媒体、 AR/VR……或许都将受益无穷。
抽奖赠书

HyperAI 超神经联合电子工业出版社为大家带来了赠书福利!我们准备了 5 本超干货科普图书「AI for Science:人工智能驱动科学创新」,快来参与抽奖吧~
参与方式
关注 HyperAI 超神经公众号,并在后台回复「AI4S 赠书」,点击抽奖页面参与抽奖,我们共为大家准备了 5 本图书,快递包邮送到您手中,快来参与吧!
图书简介
从预测蛋白质结构,到推测基因突变的致病性,AI 引领的新范式已经让我们看到包括生命科学在内的各个科学领域的新机遇。
「AI for Science:人工智能驱动科学创新」一书聚焦于人工智能与材料科学、生命科学、电子科学、能源科学、环境科学五大领域的交叉融合,通过深入浅出的语言,对基本概念、技术原理和应用场景进行了全面的介绍,让读者可以快速掌握 AI for Science 的基础知识。此外,对于每个交叉领域,本书通过案例进行了详尽的介绍,梳理了产业地图,并给出了相关政策启示。








