HyperAI
Command Palette
Search for a command to run...
ドメイン適応型セマンティック セグメンテーション用の LoveDA リモート センシング土地被覆データセット
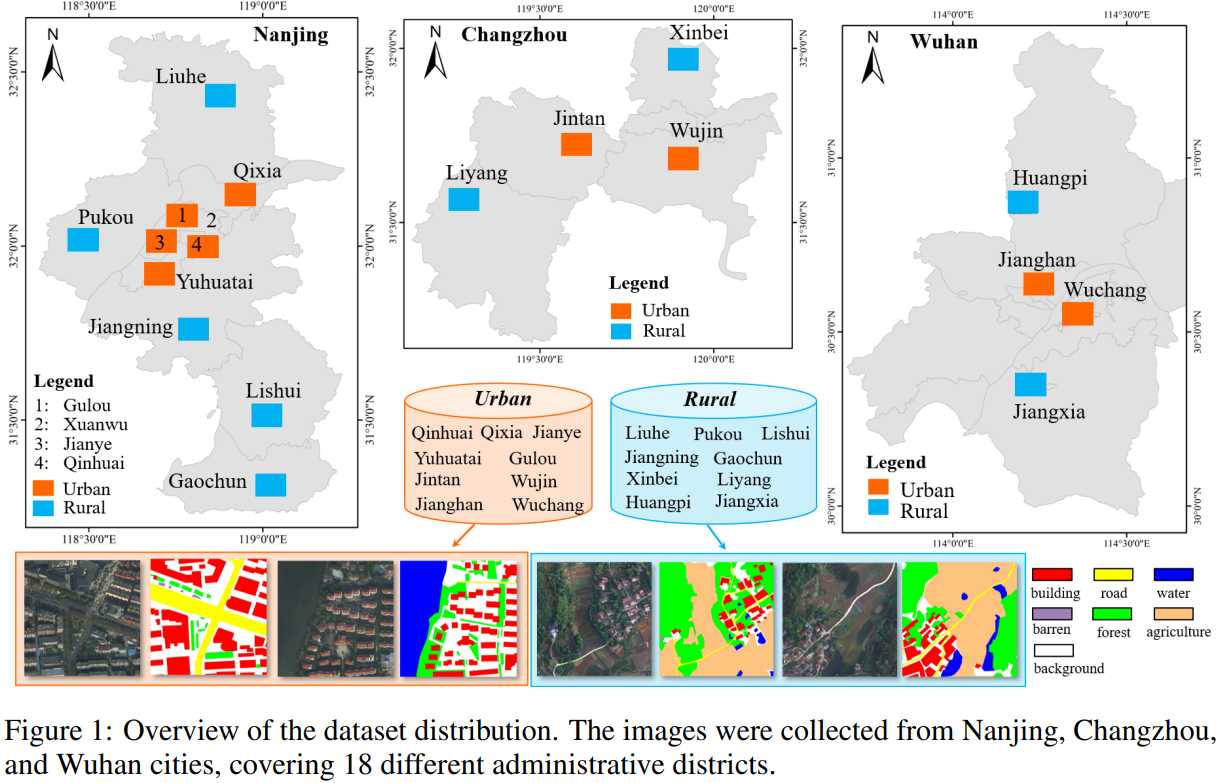
LoveDA データセットは、リモート センシングの分野で使用される土地被覆データセットであり、ドメイン適応型セマンティック セグメンテーション用に特別に設計されています。これは、武漢大学の測量、地図作成、およびリモート センシング情報工学の国家重点研究所の RSIDEA チームによって構築され、リモート センシング分野におけるセマンティック セグメンテーションと転移学習の研究を促進することを目的としています。 LoveDA データセットの主な機能をいくつか示します。
- マルチスケール オブジェクト: データセット内の高空間解像度 (HSR) 画像は、中国の 3 つの異なる都市にある 18 の複雑な都市および田園シーンから収集されました。これらのシーン内の同じカテゴリのオブジェクトは、異なる地理的景観でまったく異なるスケールの変化を示しています。
- 複雑な背景のサンプル: LoveDA データセットには、特にバックグラウンド サンプルの場合に、豊富な詳細とより大きなクラス内変動が含まれているため、分類タスクの複雑さが増大します。
- 一貫性のないクラス分布: 都市と田園のシーンではカテゴリの分布に違いがあります。都市のシーンには建物や道路などの人工物が多く含まれますが、田園のシーンには水域や森林などの自然要素が多く含まれます。
- 適用性: このデータセットは、土地被覆のセマンティック セグメンテーション タスクと教師なしドメイン適応 (UDA) タスクの両方に適しており、研究者に新たな課題と研究の方向性を提供します。
- 大規模な注釈: LoveDA データセットには 5,987 枚の高解像度画像と 166,768 個の注釈付きセマンティック オブジェクトが含まれており、この種のデータセットとしては最大の 1 つとなっています。
- データソース: データセットの画像は Google Earth プラットフォームから取得され、南京、常州、武漢から収集され、総面積 536.15 平方キロメートルをカバーしています。
- オープンソース: LoveDA データセットは無料でオープンソースであり、関連するコードとデータは GitHub で見つけることができ、コミュニティ内での研究とコラボレーションを促進します。
- 社会的影響: このデータセットは、リモート センシング分野における土地被覆マッピング技術を進歩させるために開発されたもので、フィールド マッピングに必要な人的および物的リソースの削減など、社会にプラスの影響を与える可能性があります。 LoveDA データセットのリリースは、リモート センシング分野の研究者に、実際的な問題を解決し、関連技術の開発を促進するための挑戦的なデータ リソースを提供します。
LoveDA.torrent
シーディング 1ダウンロード中 0完了 329総ダウンロード数 690
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。