HyperAI
Command Palette
Search for a command to run...
VoxCeleb2 音声認識データセット
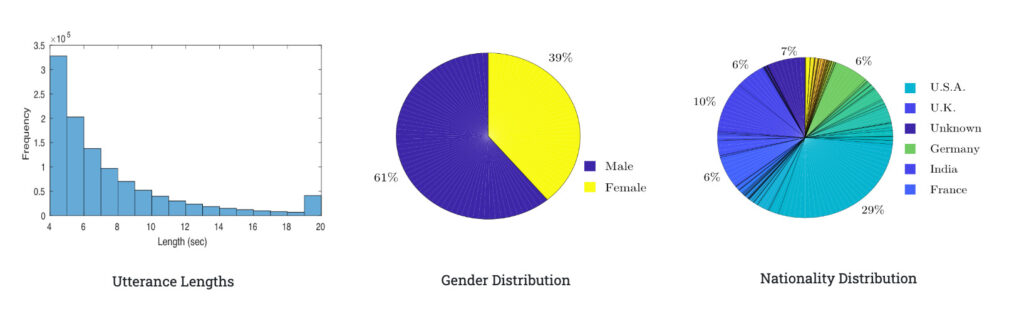
VoxCeleb2 は、オープンソース メディアから派生した大規模な話者認識データ セットで、6,000 人を超える話者からの 100 万コーパスで構成されています。このデータ セットは自然のシーンで収集されたため、スピーチ クリップには笑い、会話、チャンネル効果、音楽などの多くの干渉が含まれています。
VoxCeleb2 のコーパスは多言語対応であり、145 か国の話者が幅広いアクセント、年齢、人種、言語をカバーしています。同時に、データセットにはオーディオとビデオが含まれており、視覚的な音声合成、音声分離、顔と音声のクロスモーダル変換、ビデオ顔認識などの問題を解決するのにも適しています。
データセットの詳細:
VoxCeleb2.torrent
シーディング 2ダウンロード中 0完了 651総ダウンロード数 1,474
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。