Command Palette
Search for a command to run...
Déploiement Du Processeur Modèle De Clonage Vocal NeuTTS-Air
1. Introduction au tutoriel

NeuTTS-Air est un modèle de synthèse vocale (TTS) de bout en bout publié par Neuphonic en octobre 2025. Basé sur le backbone Qwen LLM (0,5 milliard de dollars) et le codec audio NeuCodec, il démontre des capacités d'apprentissage en quelques secondes pour le déploiement sur appareil et le clonage vocal instantané. L'évaluation système montre que NeuTTS Air atteint le niveau SOTA parmi les modèles open source, notamment dans les tests de synthèse ultra-réaliste et d'inférence en temps réel. Il est également généralisable à de nouveaux scénarios tels que les agents embarqués et le transfert de style, prend en charge le clonage audio de 3 secondes et génère un contenu conversationnel naturel. Après la formation, il présente la prise en charge de GGML/ONNX et le mécanisme de tatouage numérique, ce qui le place en tête du secteur open source pour l'évaluation de la synthèse vocale sur appareil et l'optimisation de la consommation d'énergie. Certains scénarios sont comparables à des modèles propriétaires.
Ce tutoriel utilise les ressources du processeur, le modèle ne prend en charge que l'anglais et la synthèse vocale prend plus de 30 secondes. Pour une vitesse de traitement plus rapide, vous pouvez utiliser une seule carte RTX 5090 (Tutoriel clone).NeuTTS-Air : un modèle de clonage vocal léger et efficace".
2. Exemples de projets
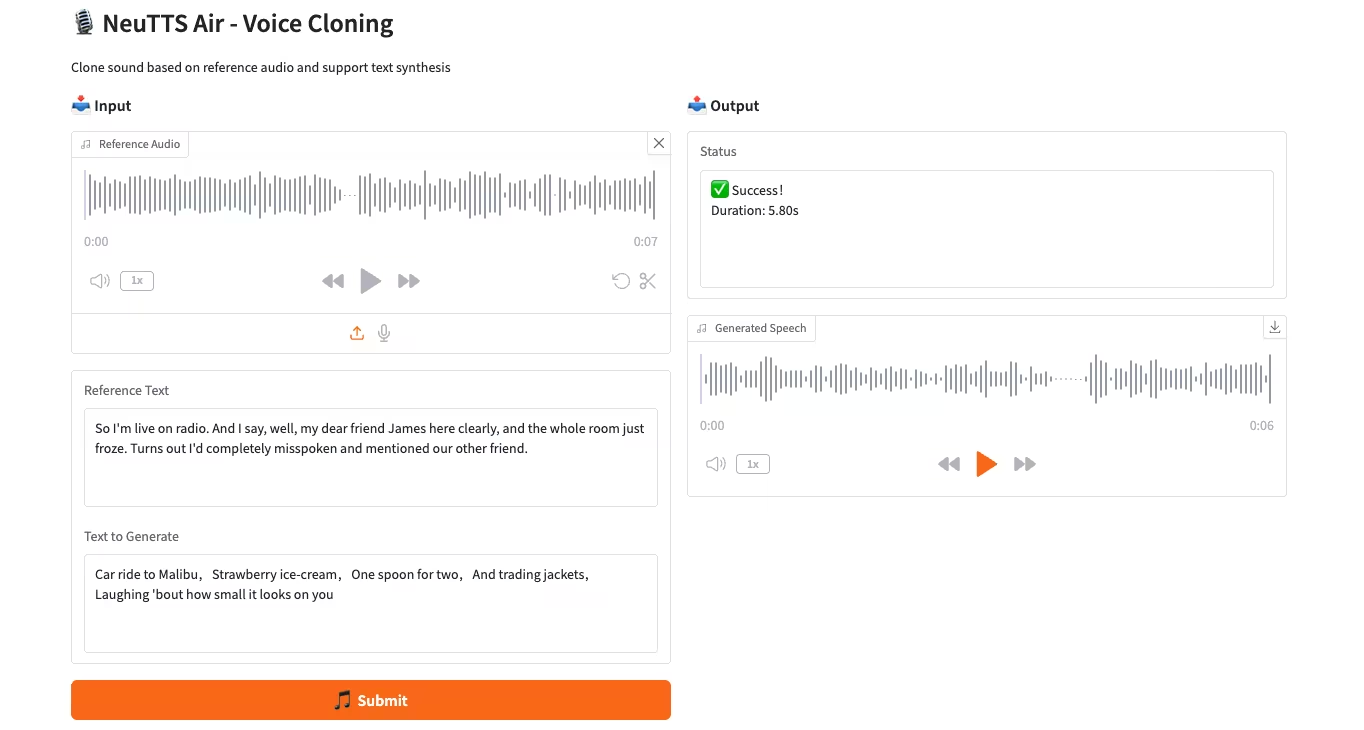
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
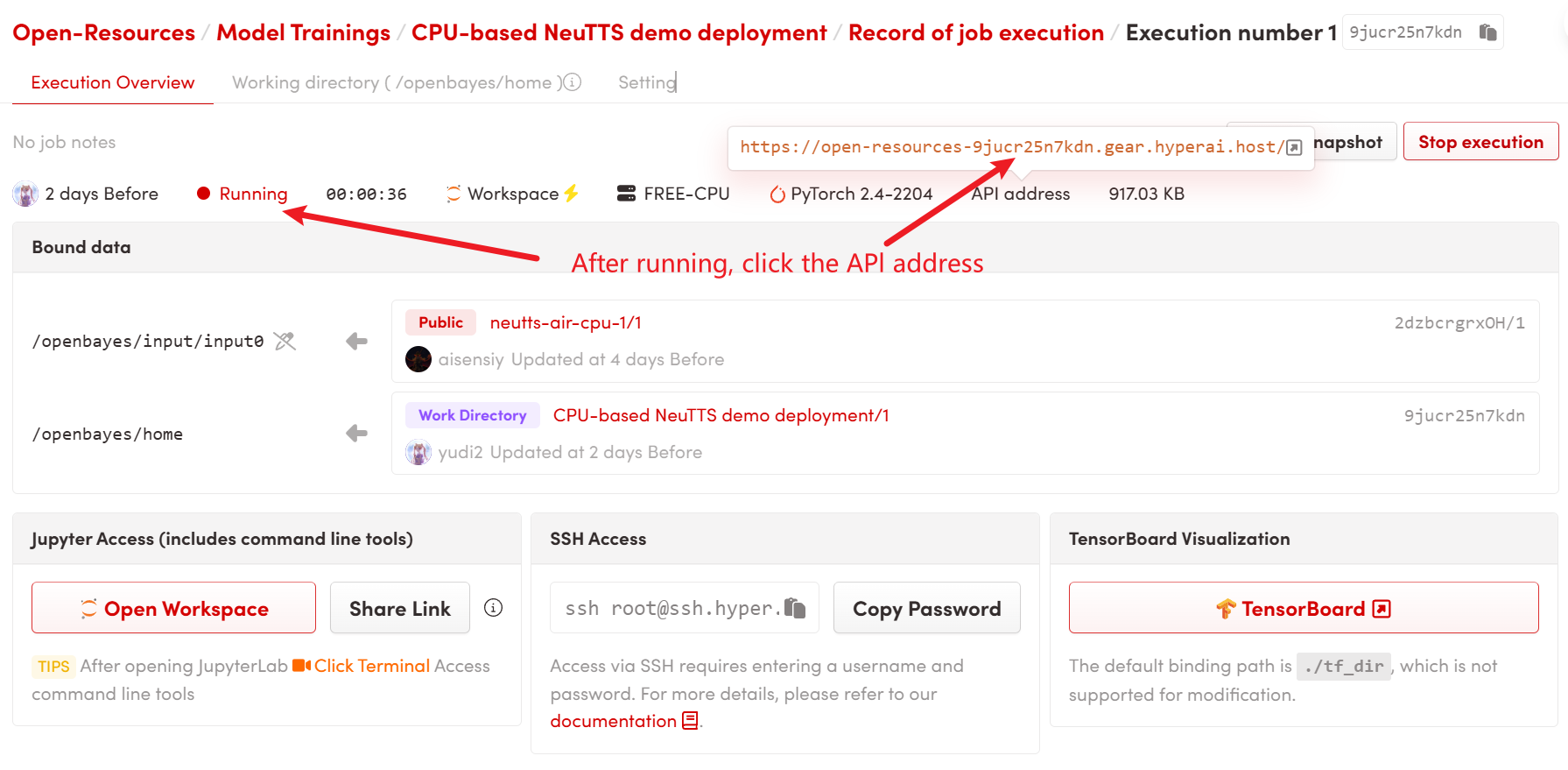
2. Une fois que vous entrez sur la page Web, vous pouvez utiliser le modèle
Si le message « Bad Gateway » s'affiche, cela signifie que le code s'exécute en arrière-plan. Veuillez patienter 2 à 3 minutes, puis actualisez la page.
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
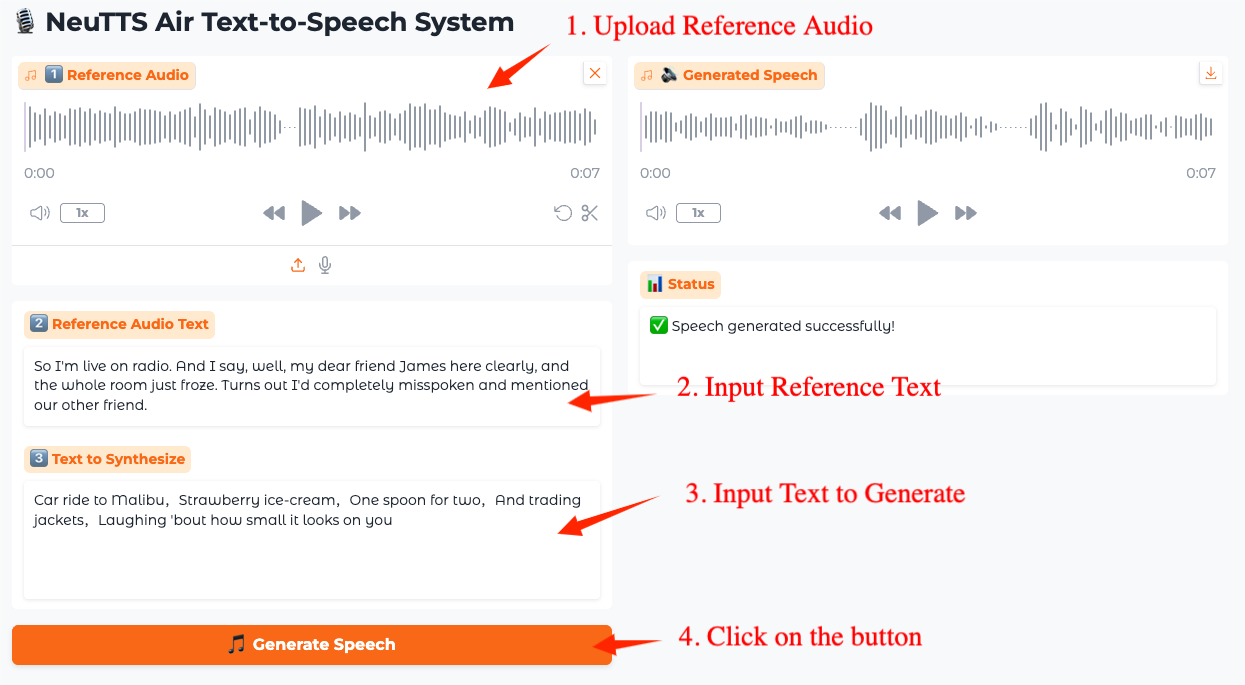
Comment utiliser
La durée minimale de l'entrée audio est de 3 secondes et la durée recommandée est de 3 à 15 secondes. La durée maximale de la sortie audio est d'environ 30 secondes
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.