Command Palette
Search for a command to run...
Higgs Audio V2 : Redéfinir l'expressivité De La Génération Vocale
Date
Taille
410.43 MB
Balises
Licence
Apache 2.0
GitHub
URL du document
1. Introduction au tutoriel

Ce tutoriel utilise une seule carte graphique RTX 4090. Il propose six exemples de test : voice-clone, smart-voice, multispeaker-voice-description, single-speaker-voice-description, single-speaker-zh et single-speaker-bgm. L'invite système prend en charge l'anglais uniquement.
2. Exemples de projets
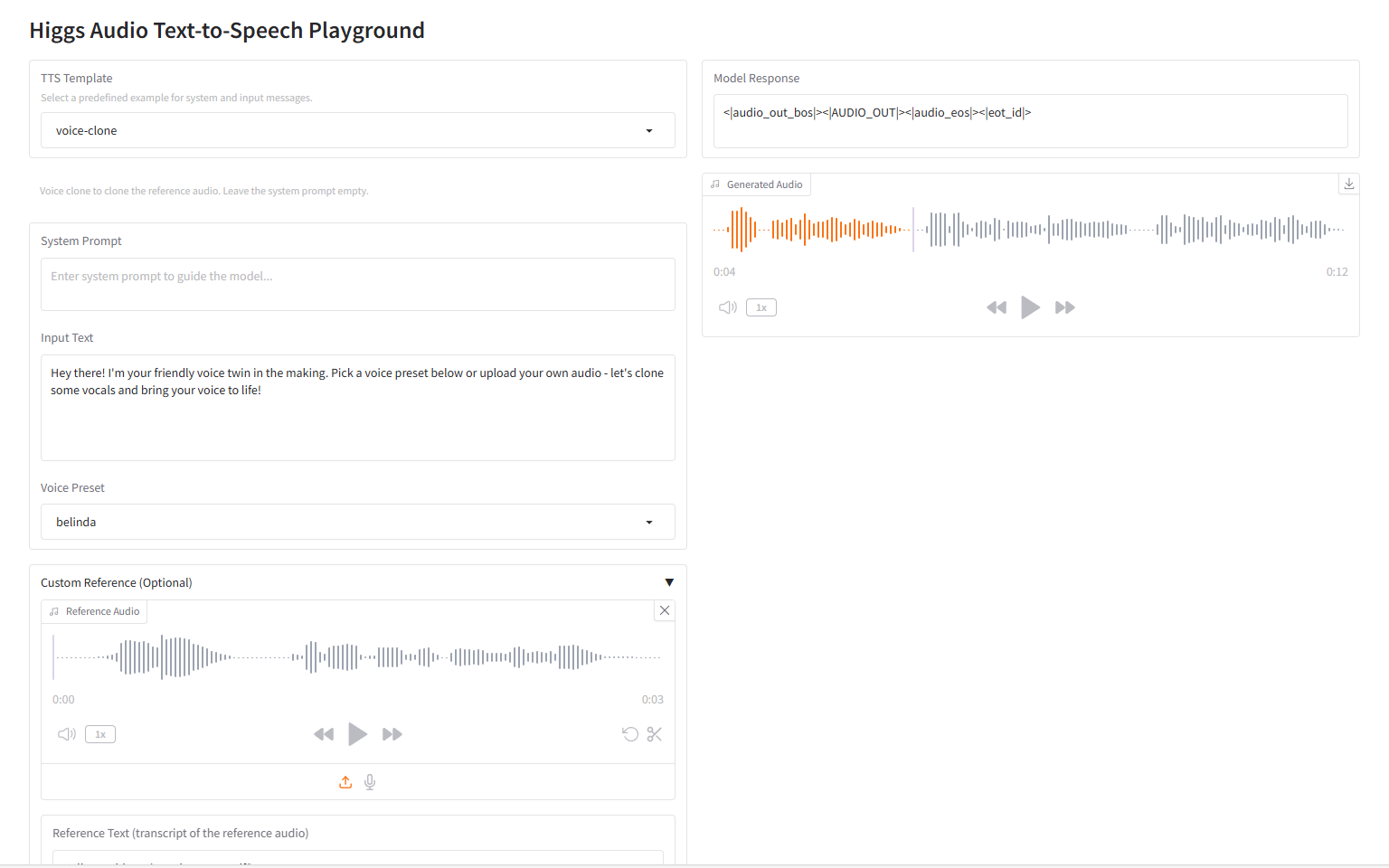
clone vocal
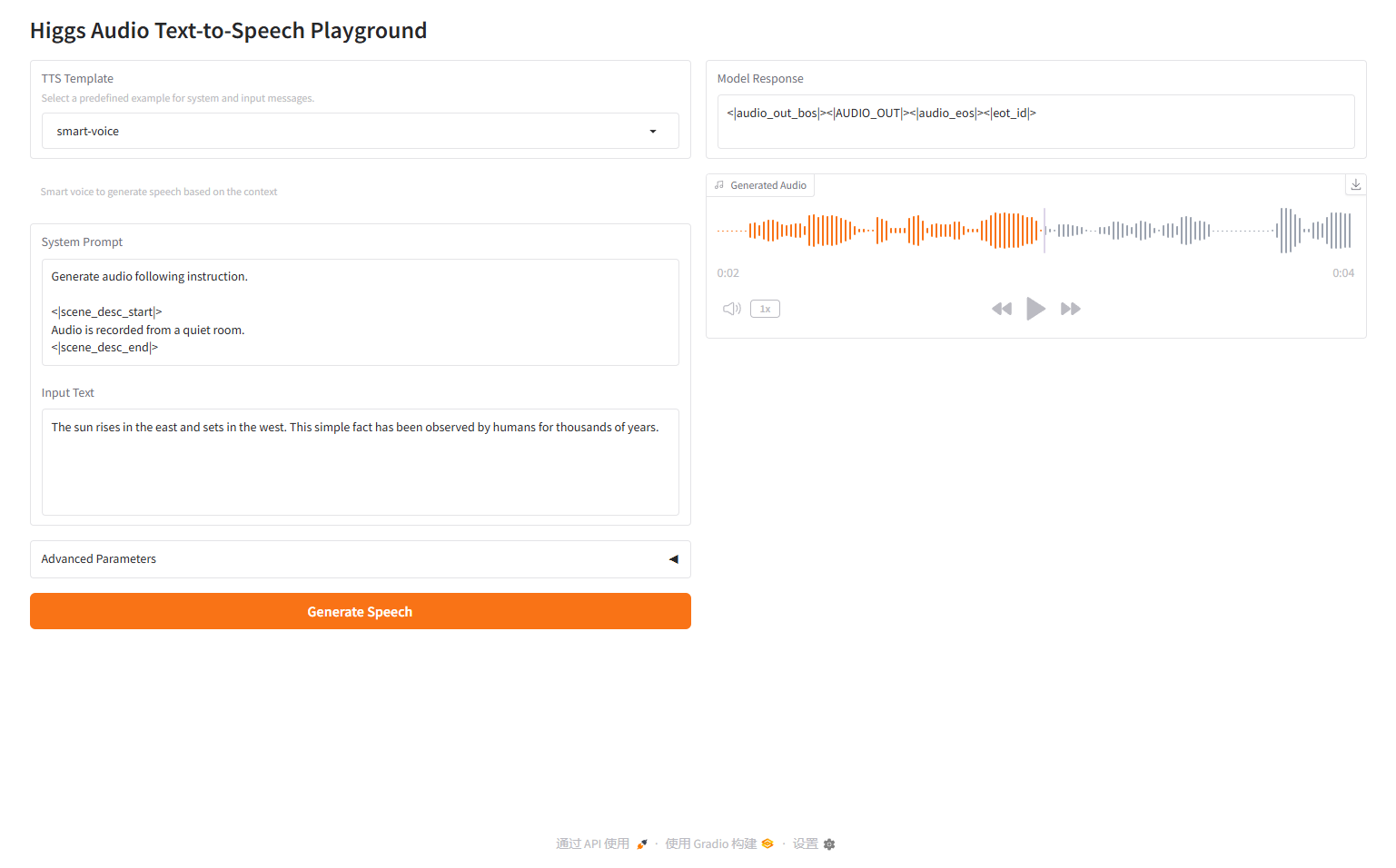
voix intelligente
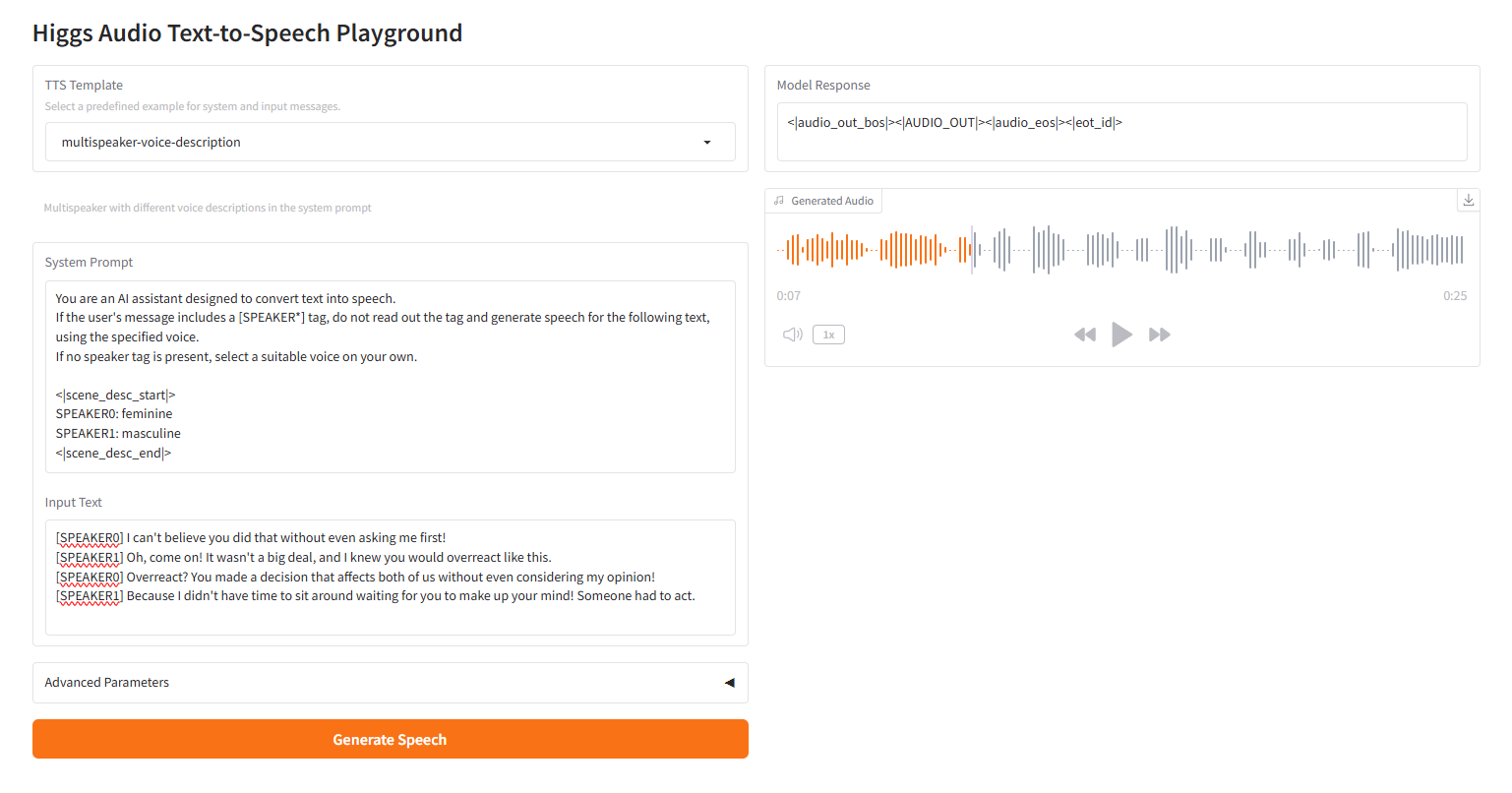
description-voix-multi-locuteurs
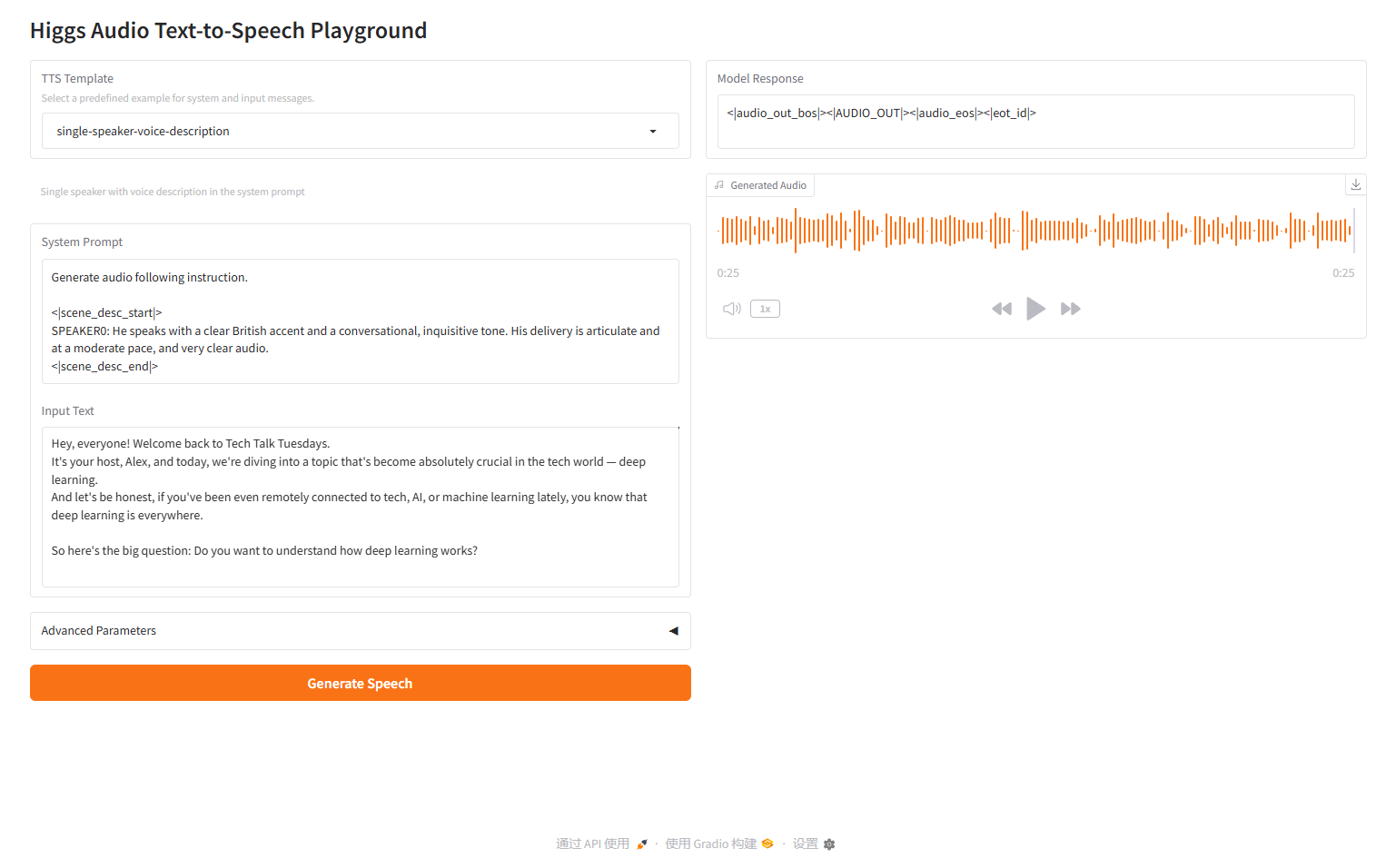
description-de-voix-à-un-locuteur
mono-locuteur-zh
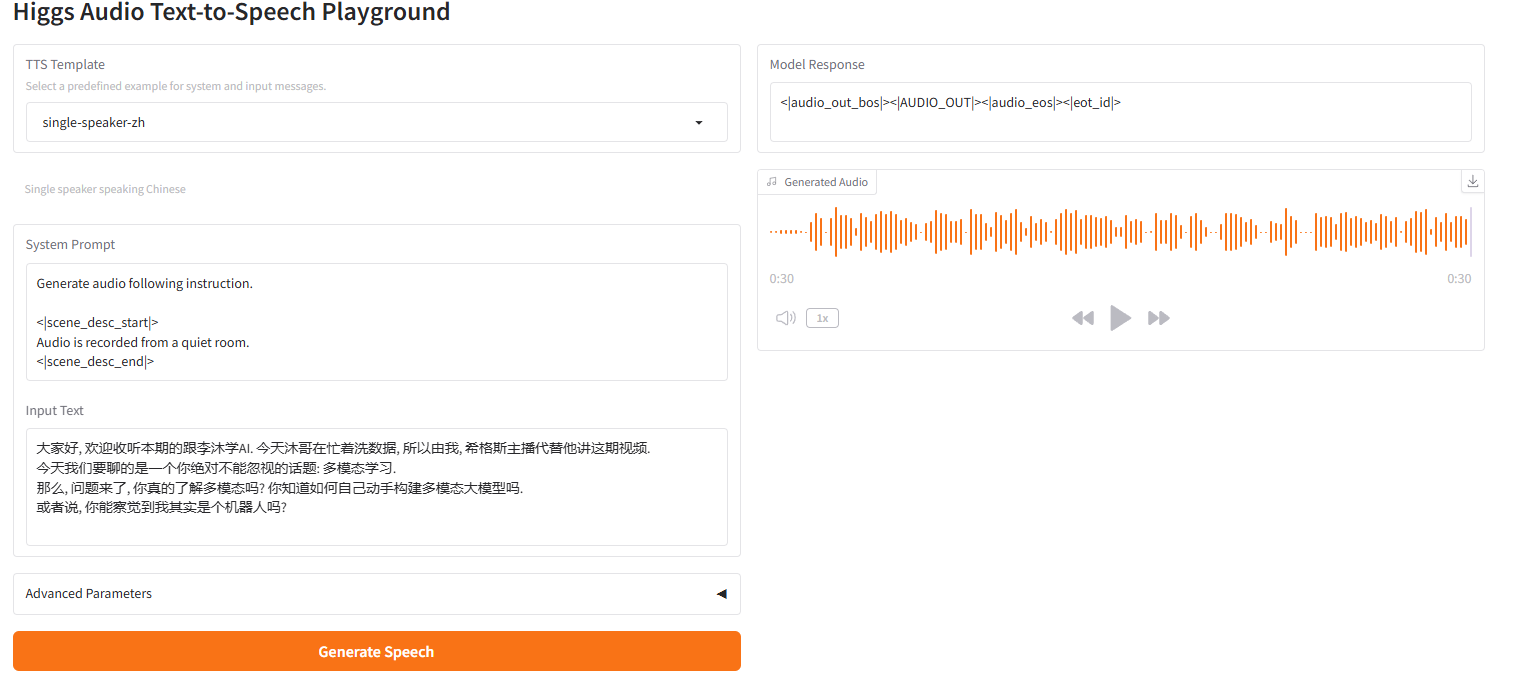
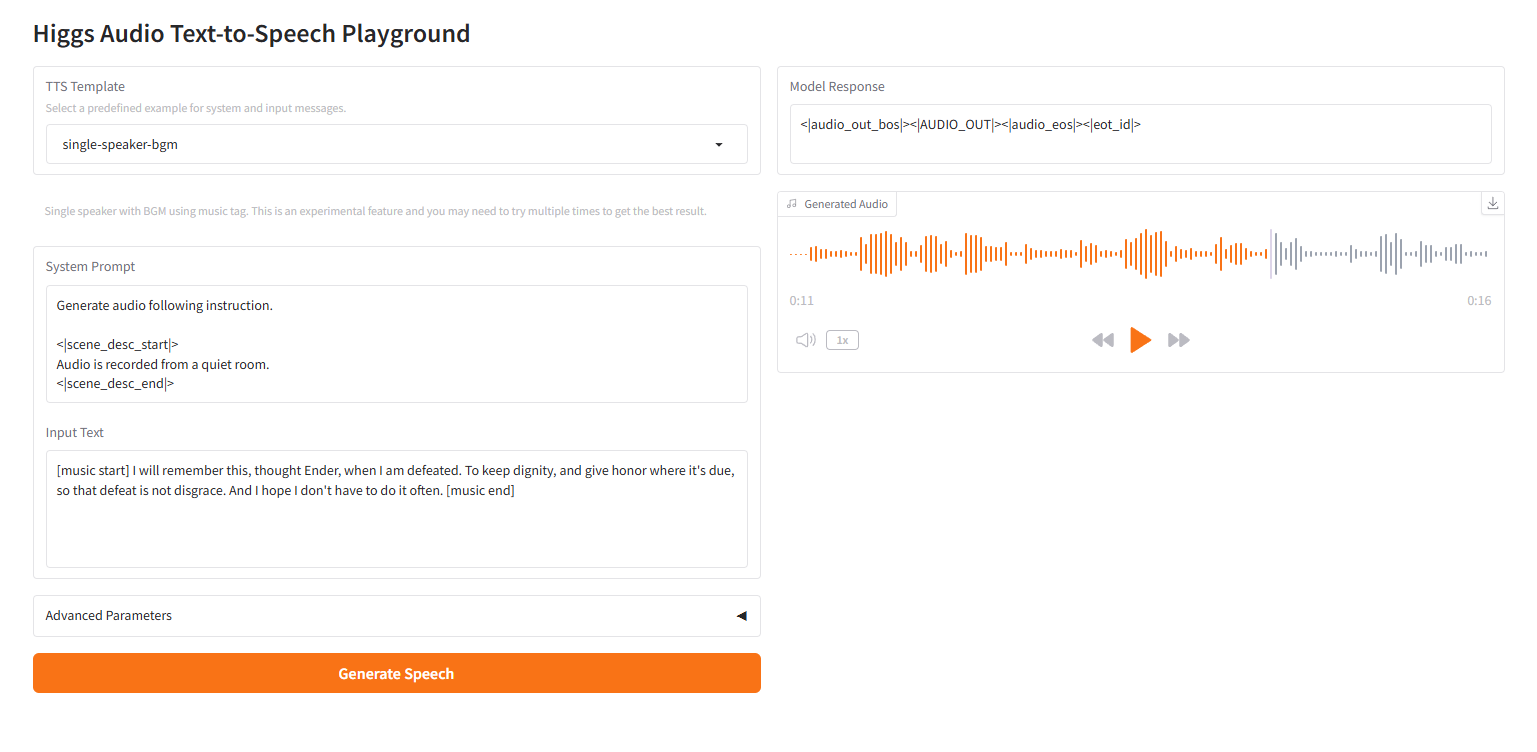
musique de fond à haut-parleur unique
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
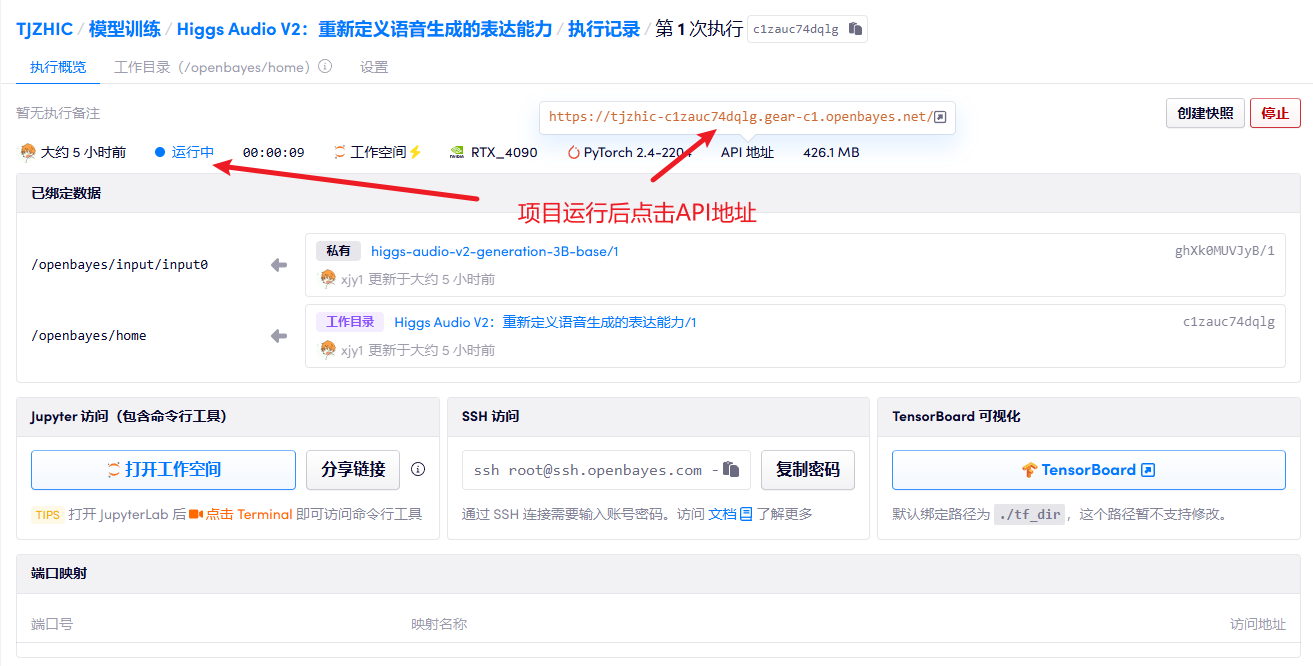
2. Étapes d'utilisation
Si le message « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Le modèle étant volumineux, veuillez patienter 2 à 3 minutes avant d'actualiser la page. Avec Safari, l'audio peut ne pas être lu directement ; il doit être téléchargé avant de pouvoir être lu.
2.1 Clonage vocal
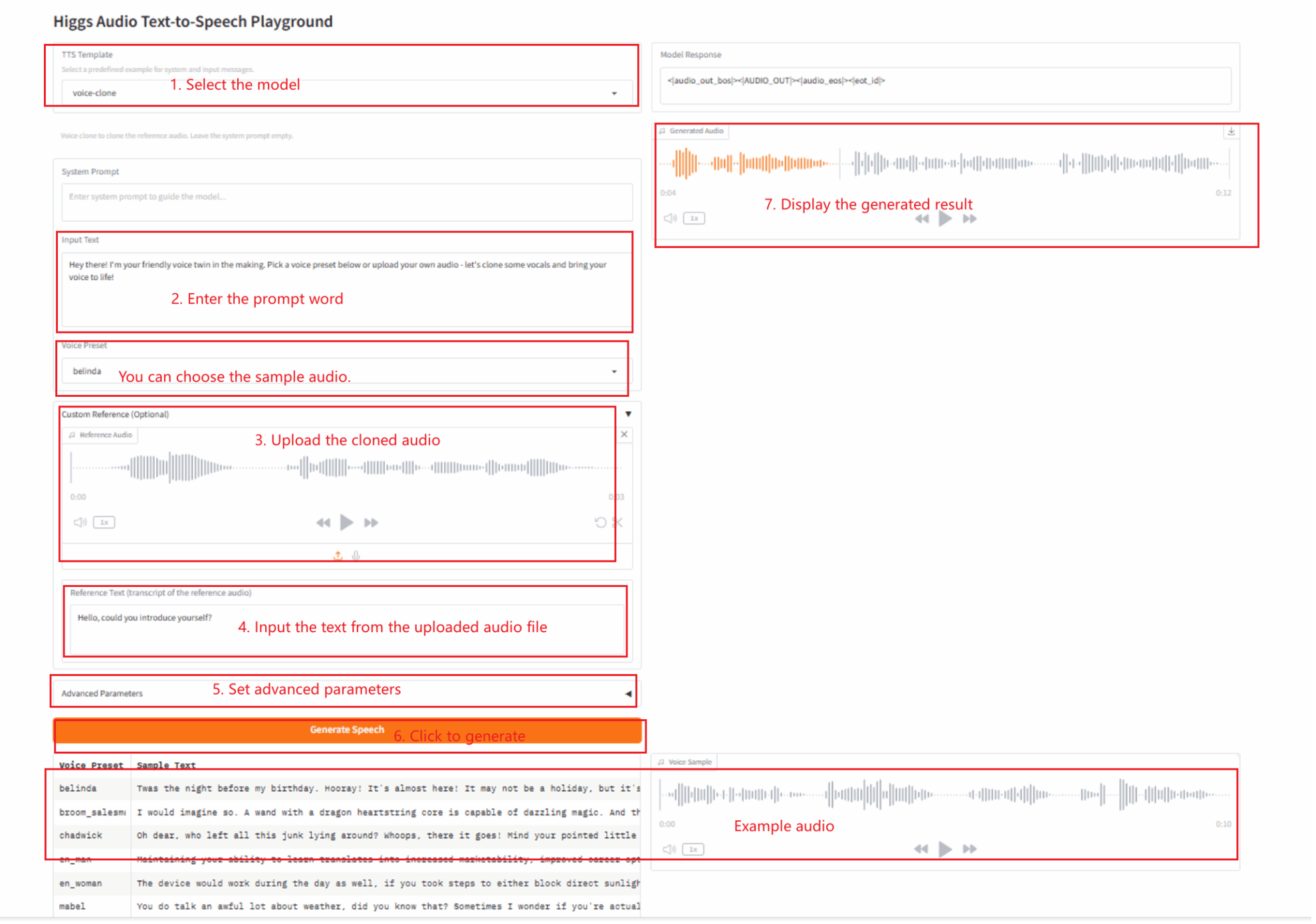
Description des paramètres
- Paramètres avancés :
- Jetons d'achèvement max. : limite la longueur du texte audio généré (en jetons). Plus la valeur est élevée, plus le texte audio généré peut être long.
- Température : contrôle le caractère aléatoire de la sortie générée. Des valeurs faibles (par exemple, 0,1) rendent la sortie plus déterministe et reproductible ; des valeurs élevées (par exemple, 1,0) rendent la sortie plus variée et créative, mais potentiellement incohérente.
- P supérieur : limite la plage d'étiquettes (probabilités cumulées) que le modèle prend en compte à chaque étape. Des valeurs faibles (comme 0,5) rendent la sortie plus concentrée ; des valeurs élevées (comme 0,95) la diversifient.
- Top K : restreint le modèle à la sélection des K marqueurs les plus probables à chaque étape. Des valeurs faibles augmentent la fiabilité des résultats ; des valeurs élevées (ou -1 pour désactiver) les diversifient.
- Longueur de la fenêtre RAS : active la fonction de détection des doublons et définit la taille de la fenêtre de texte pour la recherche des doublons. Définissez la valeur sur 0 pour désactiver cette fonctionnalité.
- Nombre maximal de répétitions RAS : en conjonction avec la fenêtre RAS, définit le nombre maximal de répétitions d'un contenu dans la fenêtre. Une valeur faible réduit les répétitions, tandis qu'une valeur élevée permet des répétitions plus naturelles.
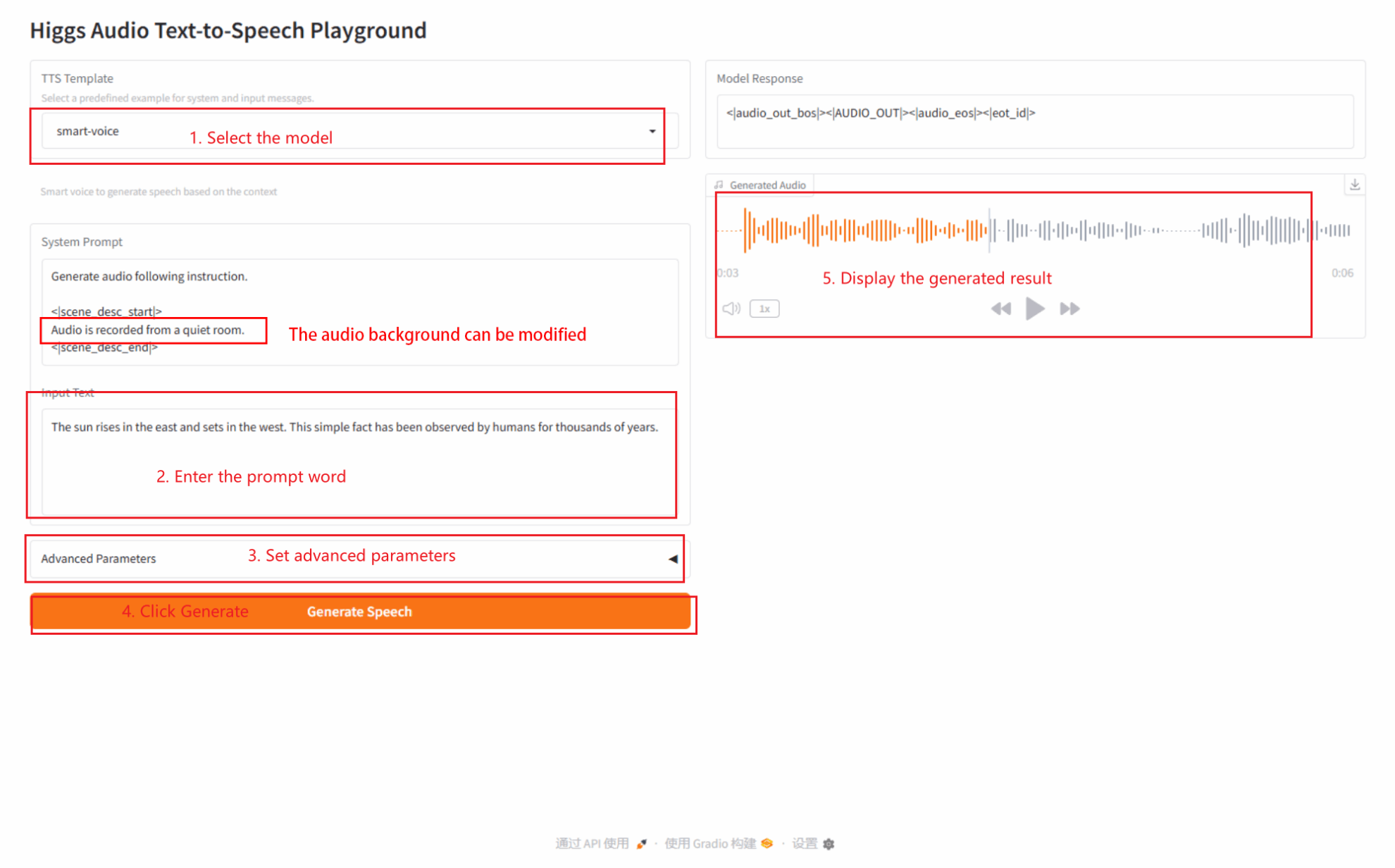
2.2 voix intelligente
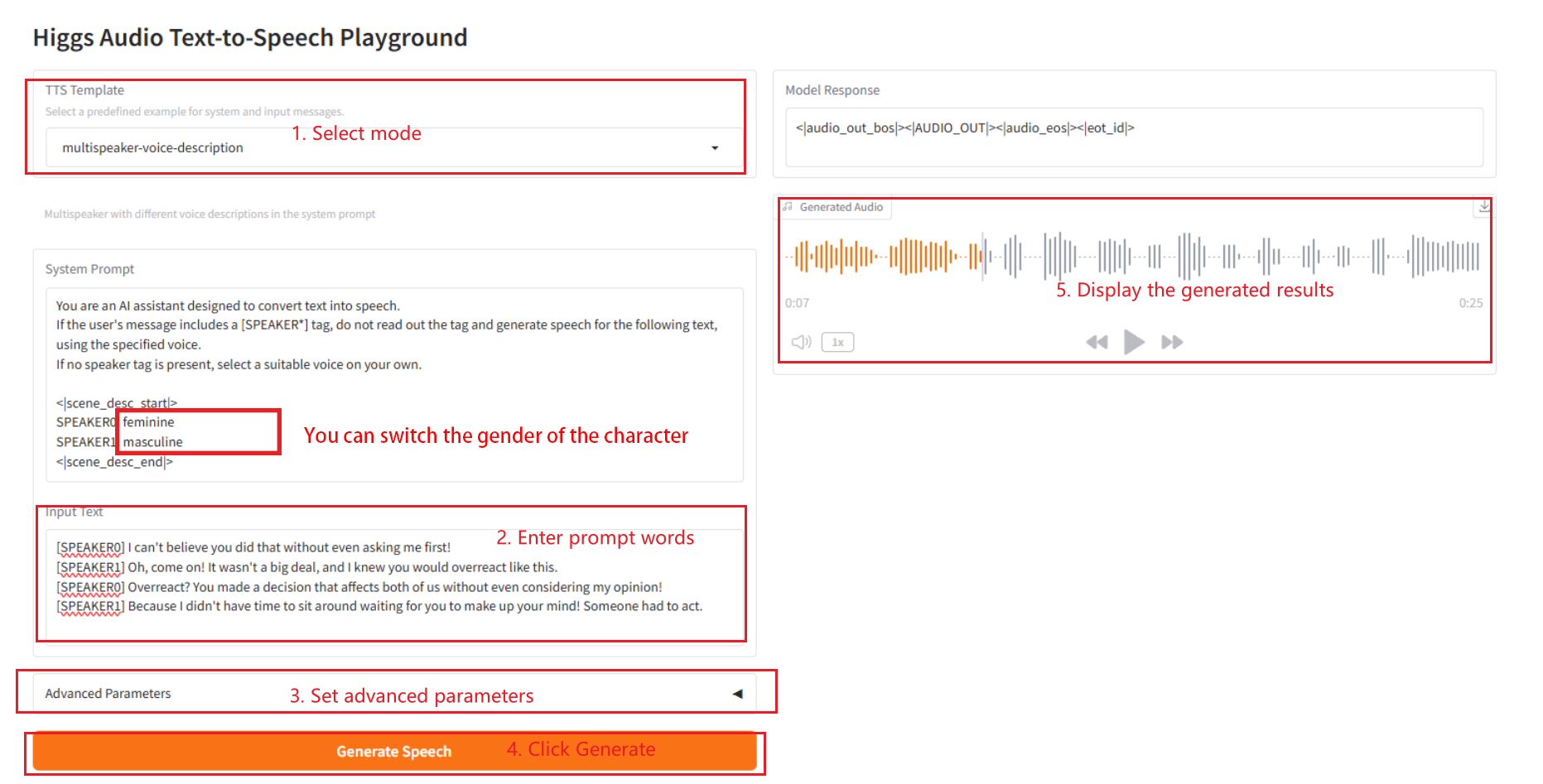
2.3 description vocale multi-locuteurs
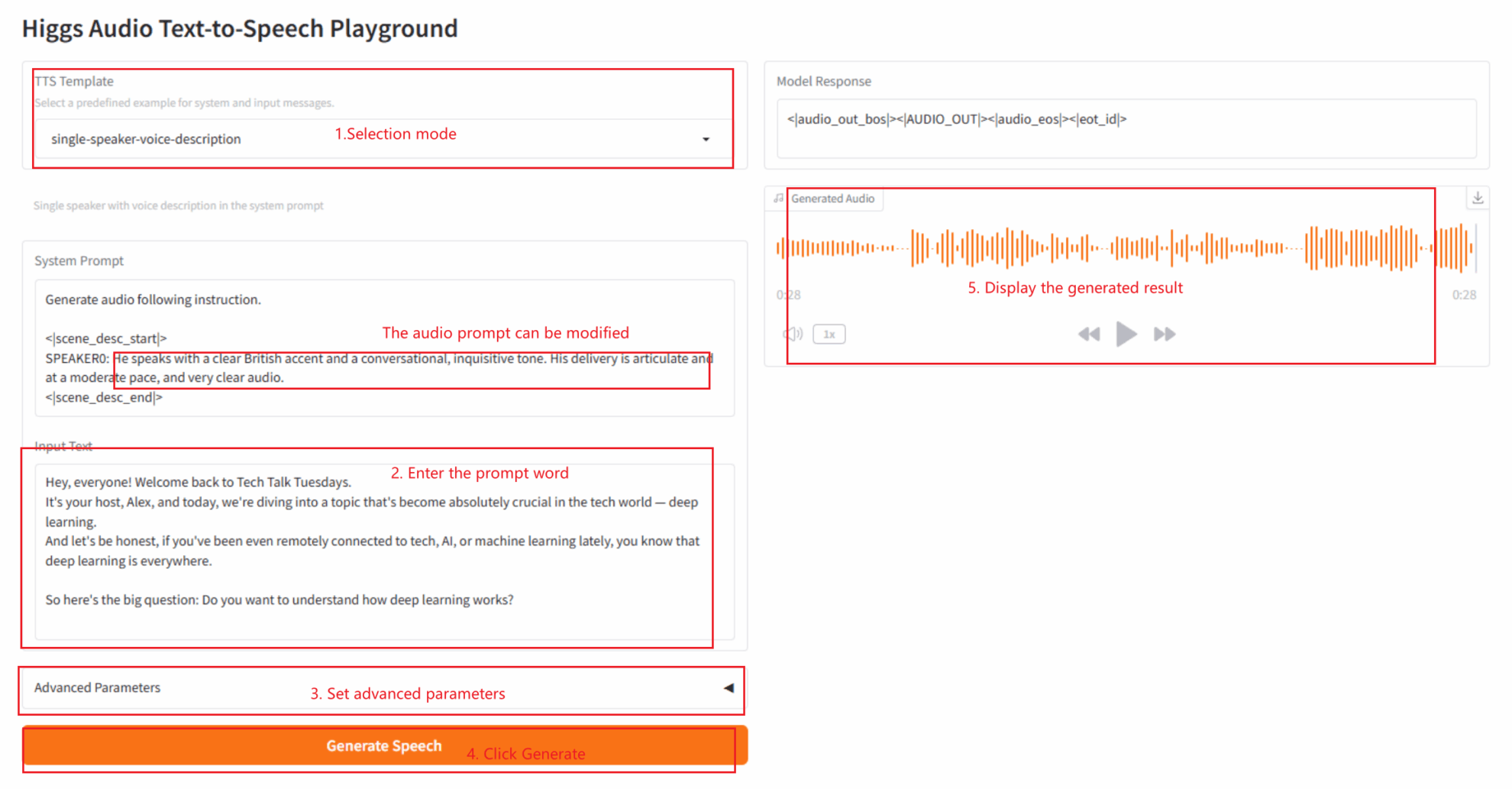
2.4 description vocale d'un seul locuteur
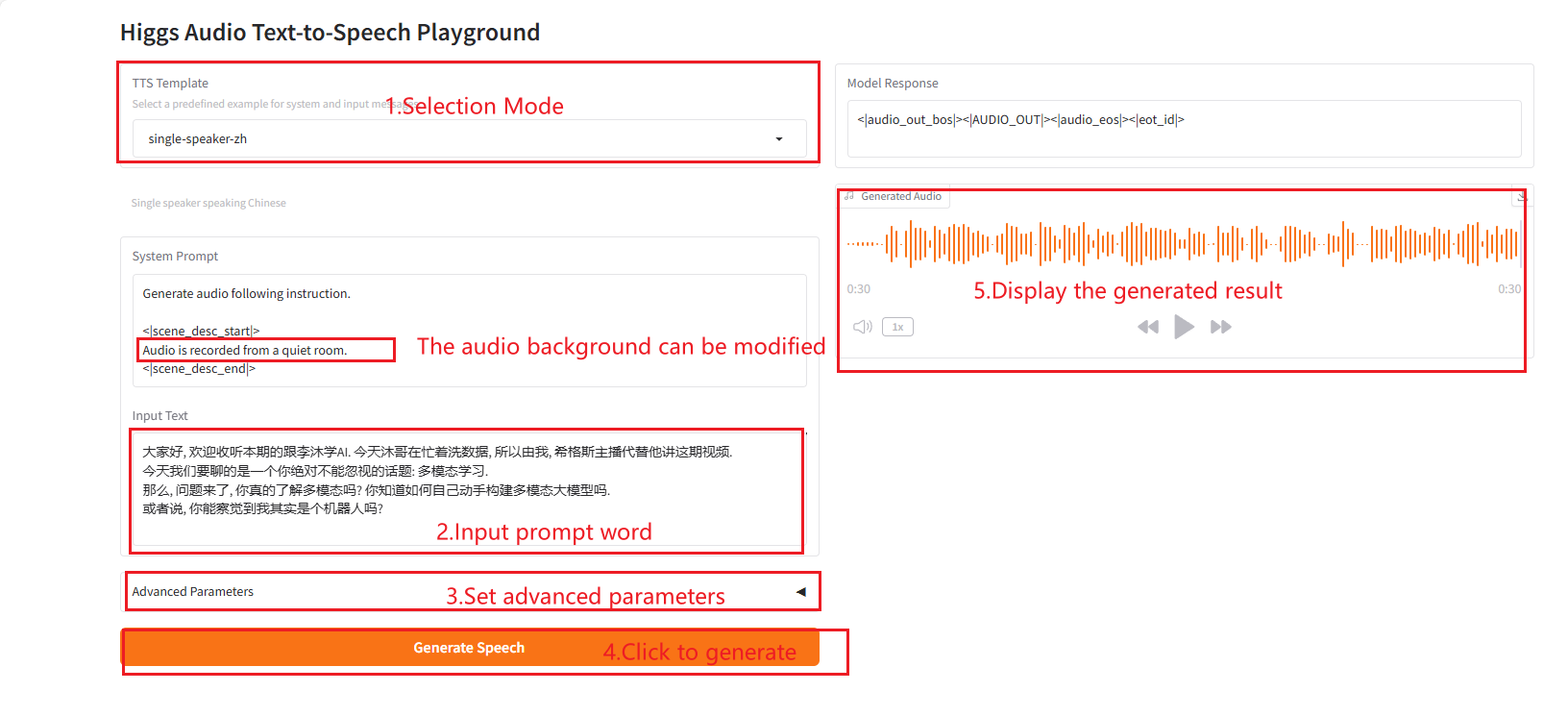
2,5 haut-parleur unique-zh
2.6 musique de fond à haut-parleur unique
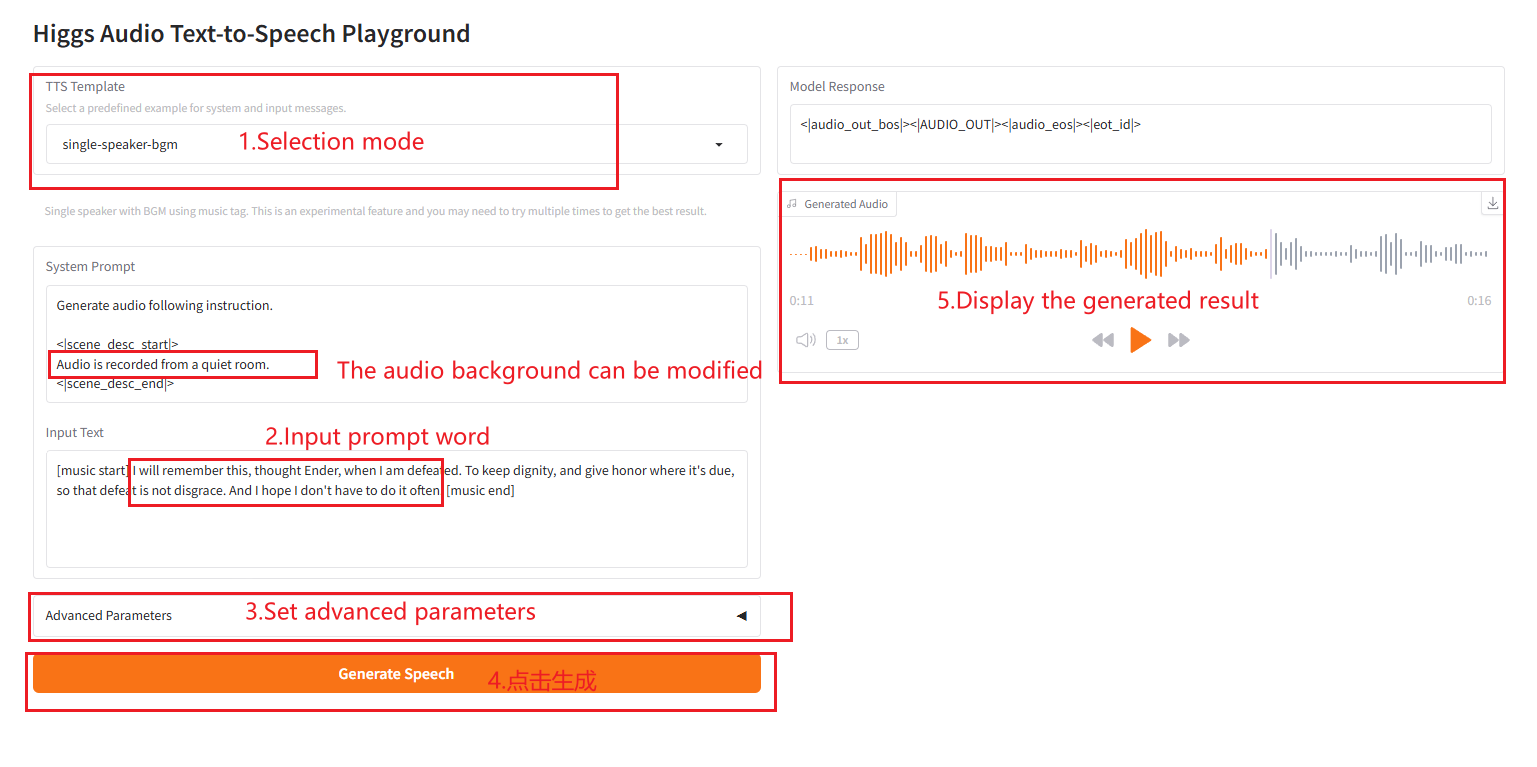
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{higgsaudio2025,
author = {{Boson AI}},
title = {{Higgs Audio V2: Redefining Expressiveness in Audio Generation}},
year = {2025},
howpublished = {\url{https://github.com/boson-ai/higgs-audio}},
note = {GitHub repository. Release blog available at \url{https://www.boson.ai/blog/higgs-audio-v2}},
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.