Command Palette
Search for a command to run...
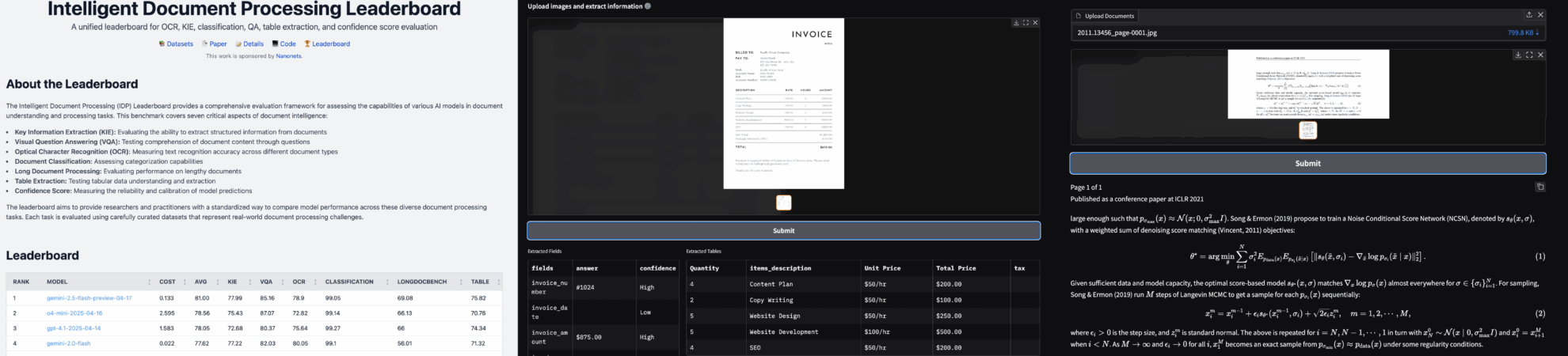
Nanonets-OCR-s : Outil d'extraction Et d'analyse Comparative Des Informations Documentaires
1. Introduction au tutoriel

Nanonets-OCR-s est un modèle de reconnaissance optique de caractères (OCR) lancé par Nanonets le 10 juin 2025. La technologie OCR classique se concentre principalement sur l'extraction de texte brut à partir d'images, tandis que Nanonets-OCR-s va plus loin. Il est capable de reconnaître plusieurs éléments dans les documents, tels que des formules mathématiques, des images, des signatures, des filigranes, des cases à cocher et des tableaux, et de les organiser dans un format Markdown structuré. Cette capacité lui permet d'être performant lors du traitement de documents complexes, tels que des articles universitaires, des documents juridiques ou des rapports commerciaux. Son résultat est non seulement facile à lire, mais constitue également une base solide pour le traitement automatisé en aval.
Ce tutoriel utilise une seule carte RTX 4090 comme ressource. Il propose deux fonctions : 1. Extraire des informations de documents ; 2. Convertir des images et des PDF en Markdown.
2. Exemples de projets
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
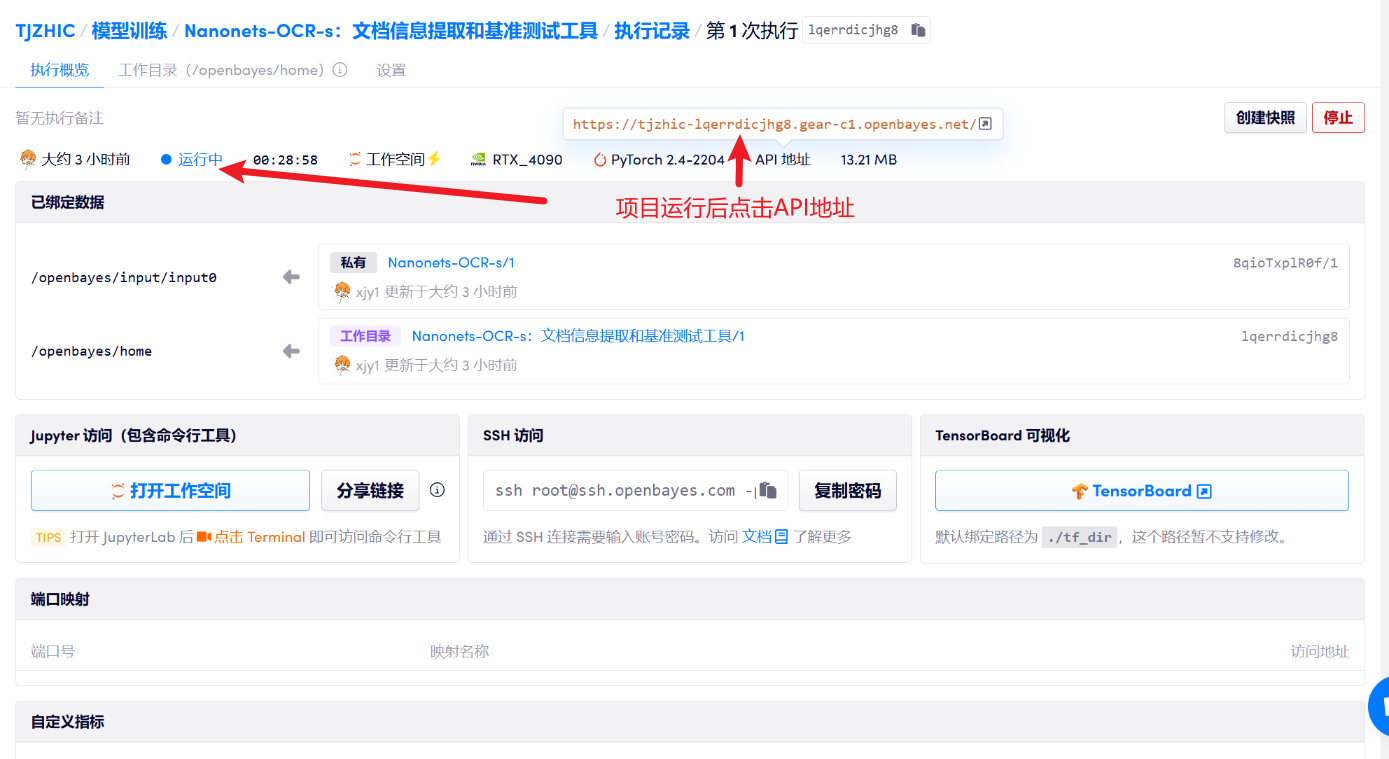
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
2.1 Extraction d'informations à partir de documents
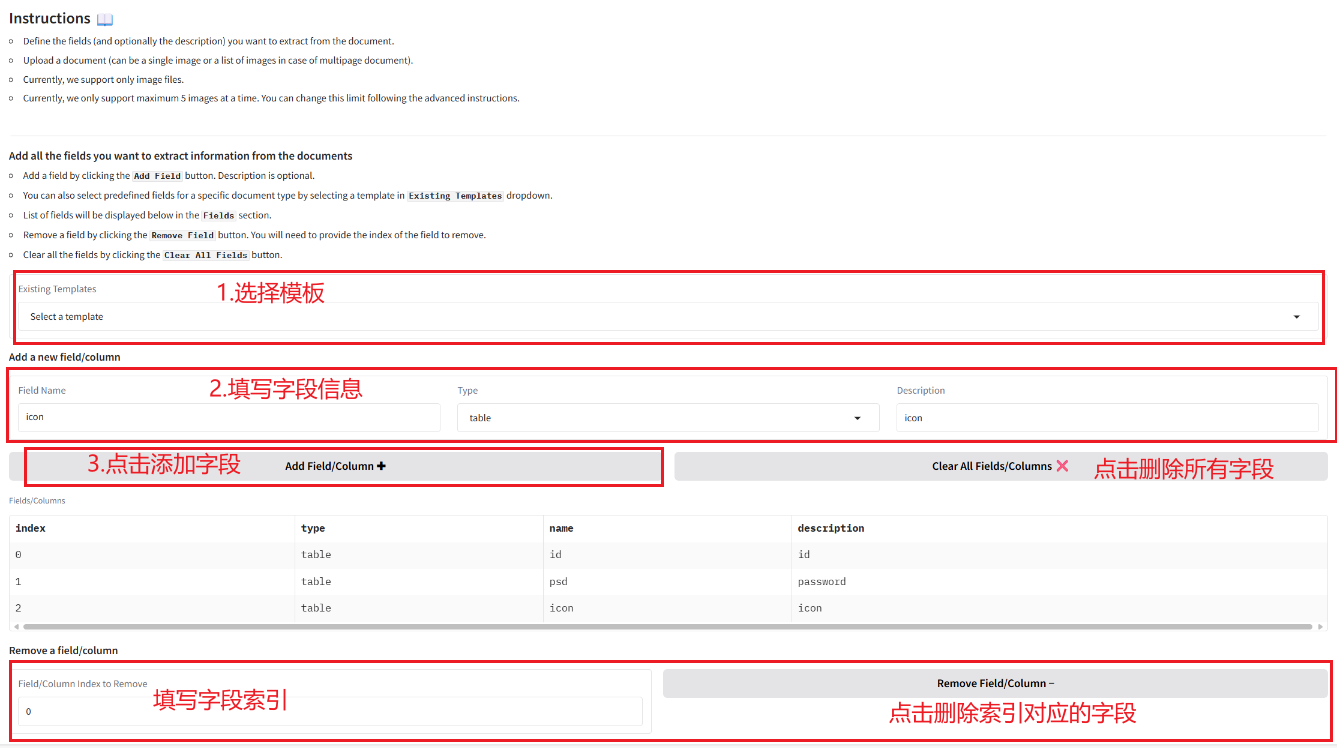
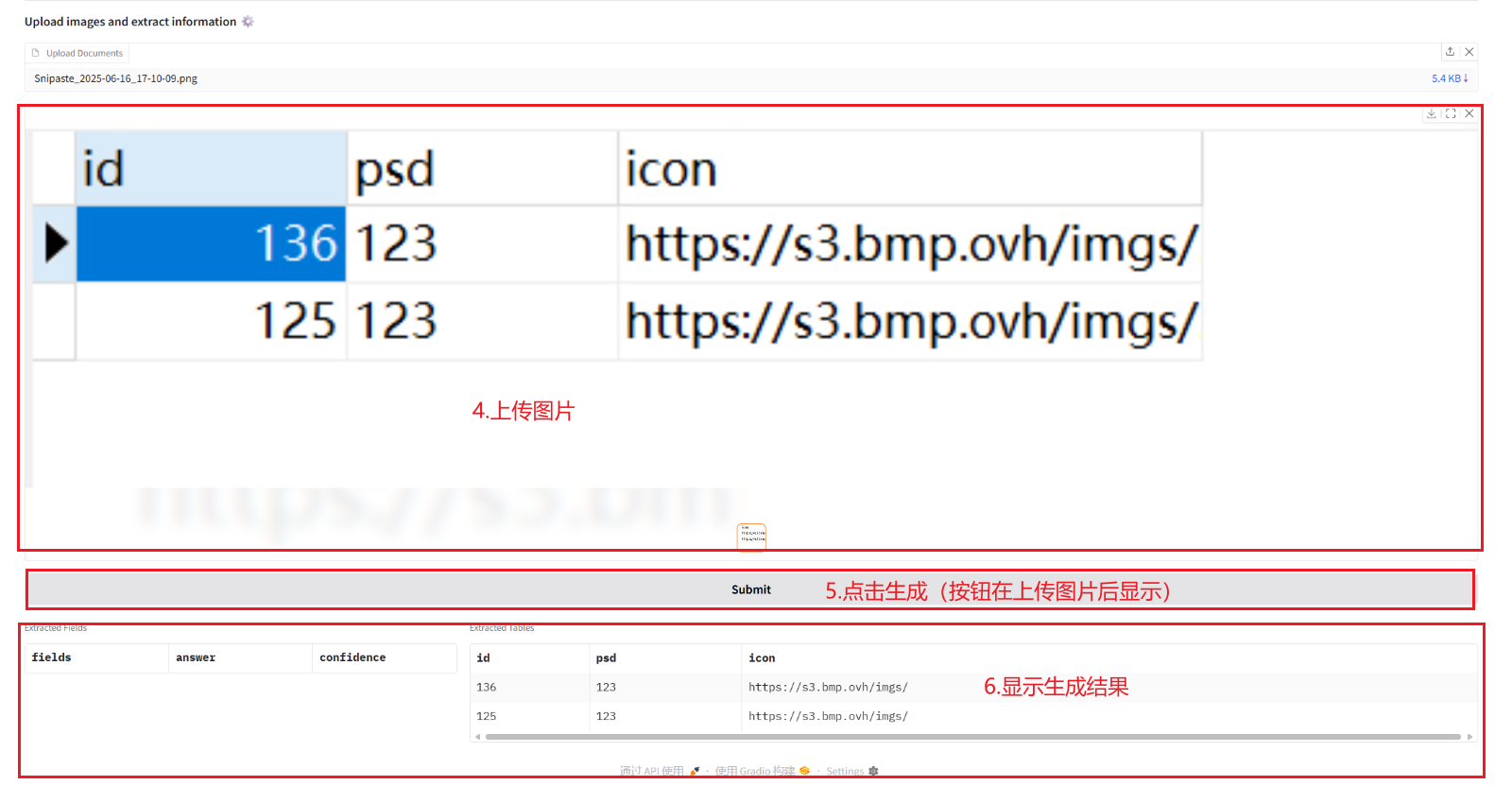
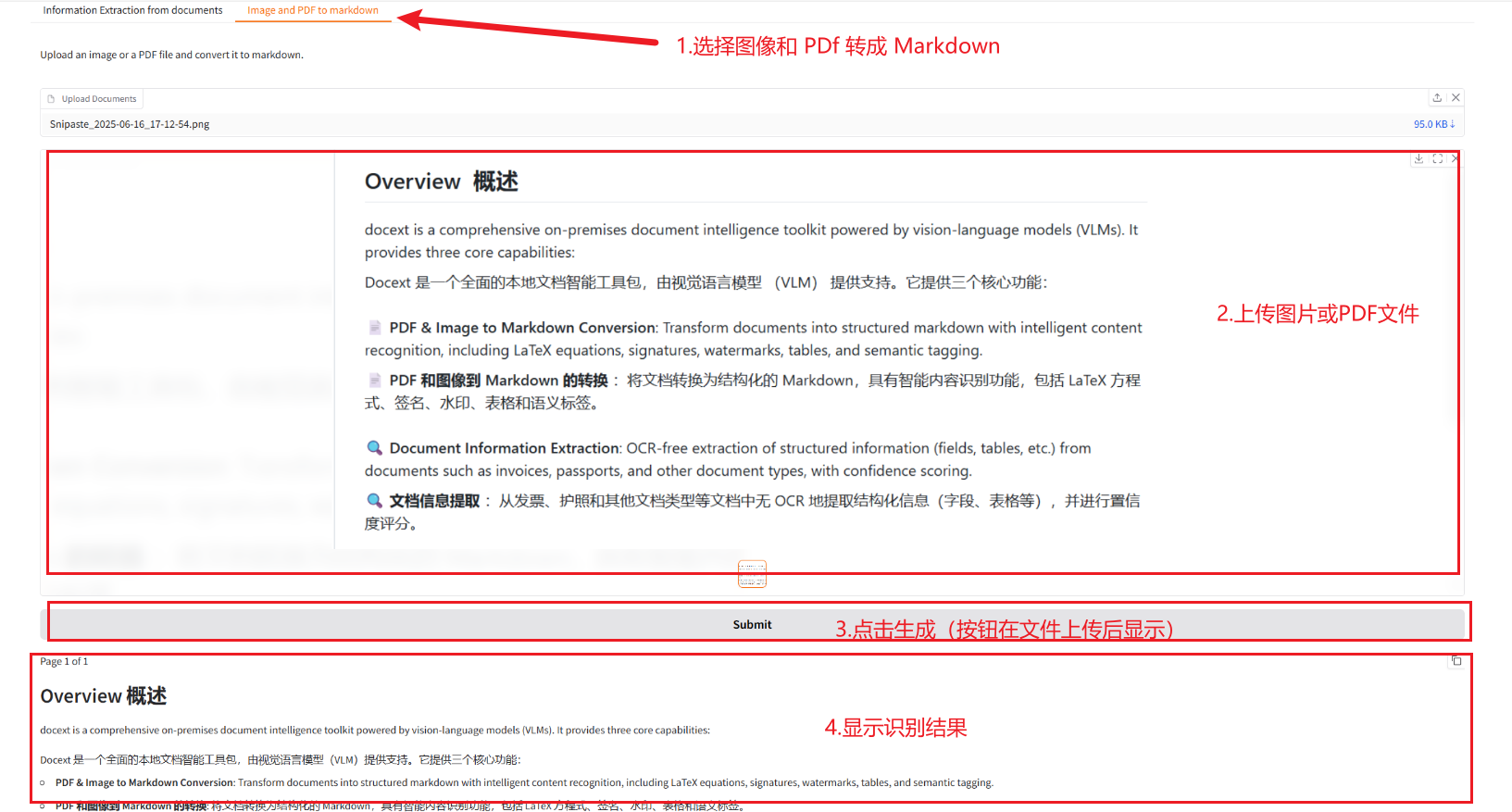
2.2 Convertir des images et des PDF en Markdown
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.