Command Palette
Search for a command to run...
OpenAudio-s1-mini : Un Outil De Génération TTS Haute Efficacité
Date
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel

Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
2. Exemples de projets
Synthèse vocale

3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
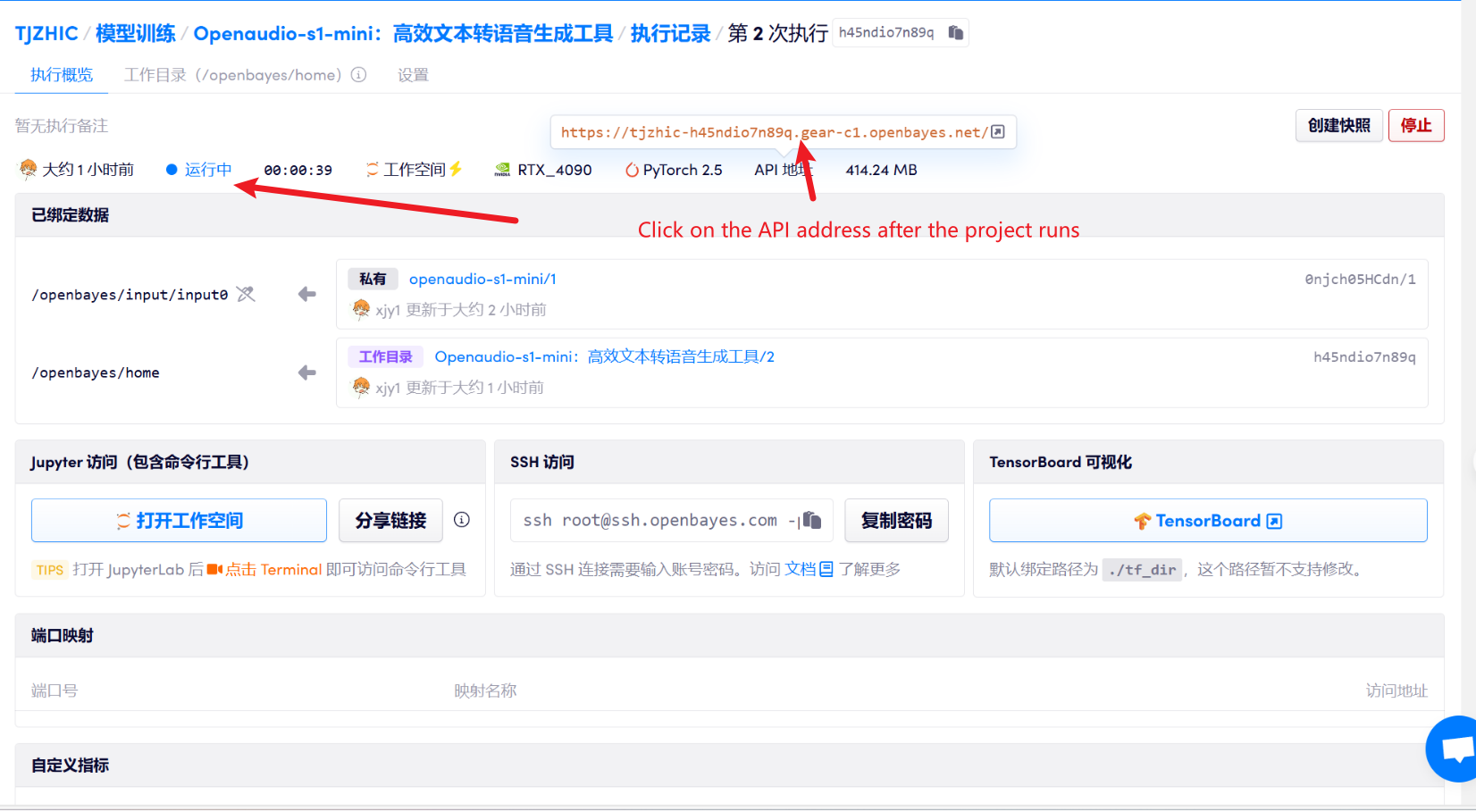
2. Une fois que vous entrez sur la page Web, vous pouvez utiliser le modèle
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page. Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
Comment utiliser
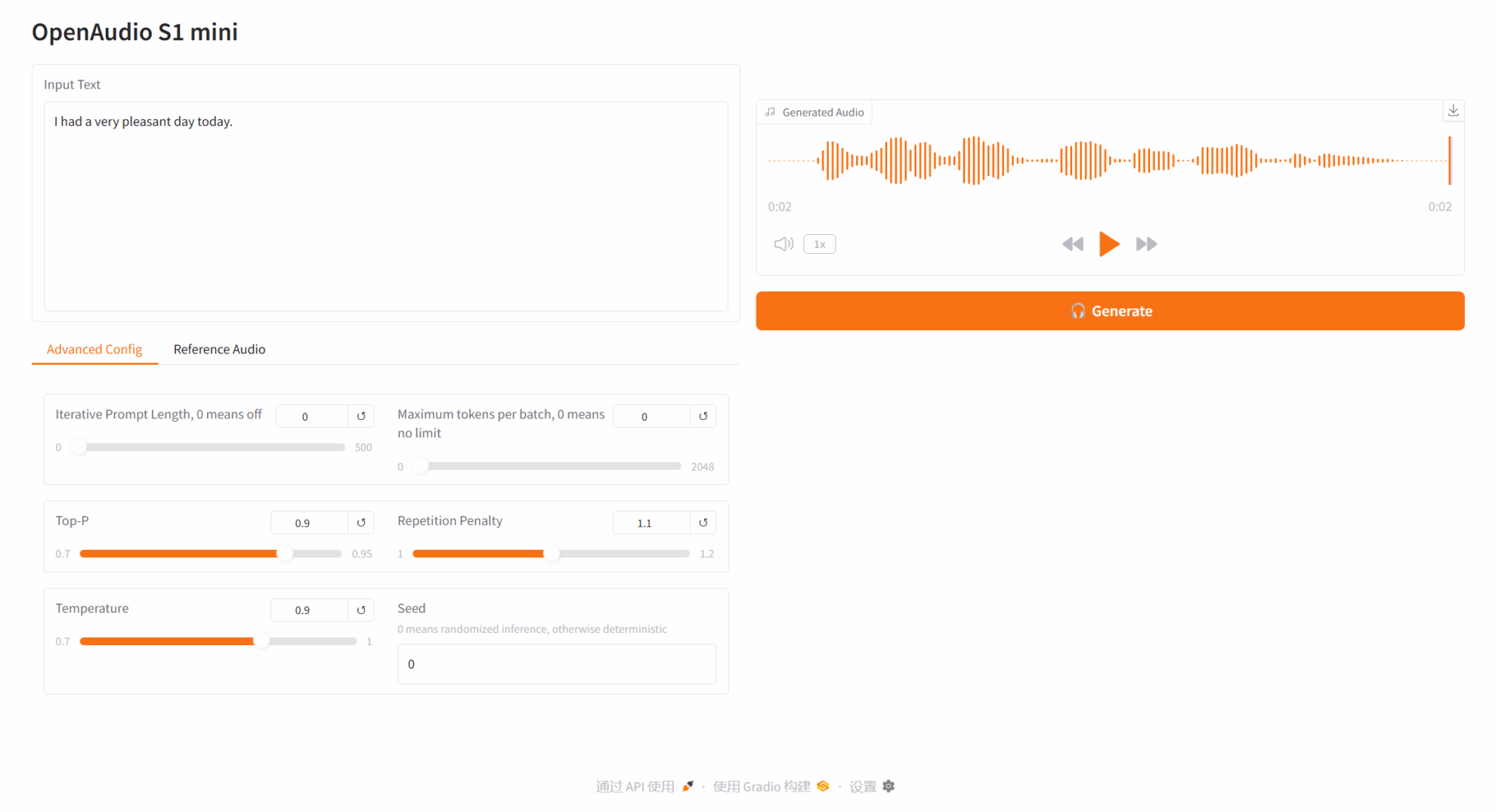
2.1 Texte en audio
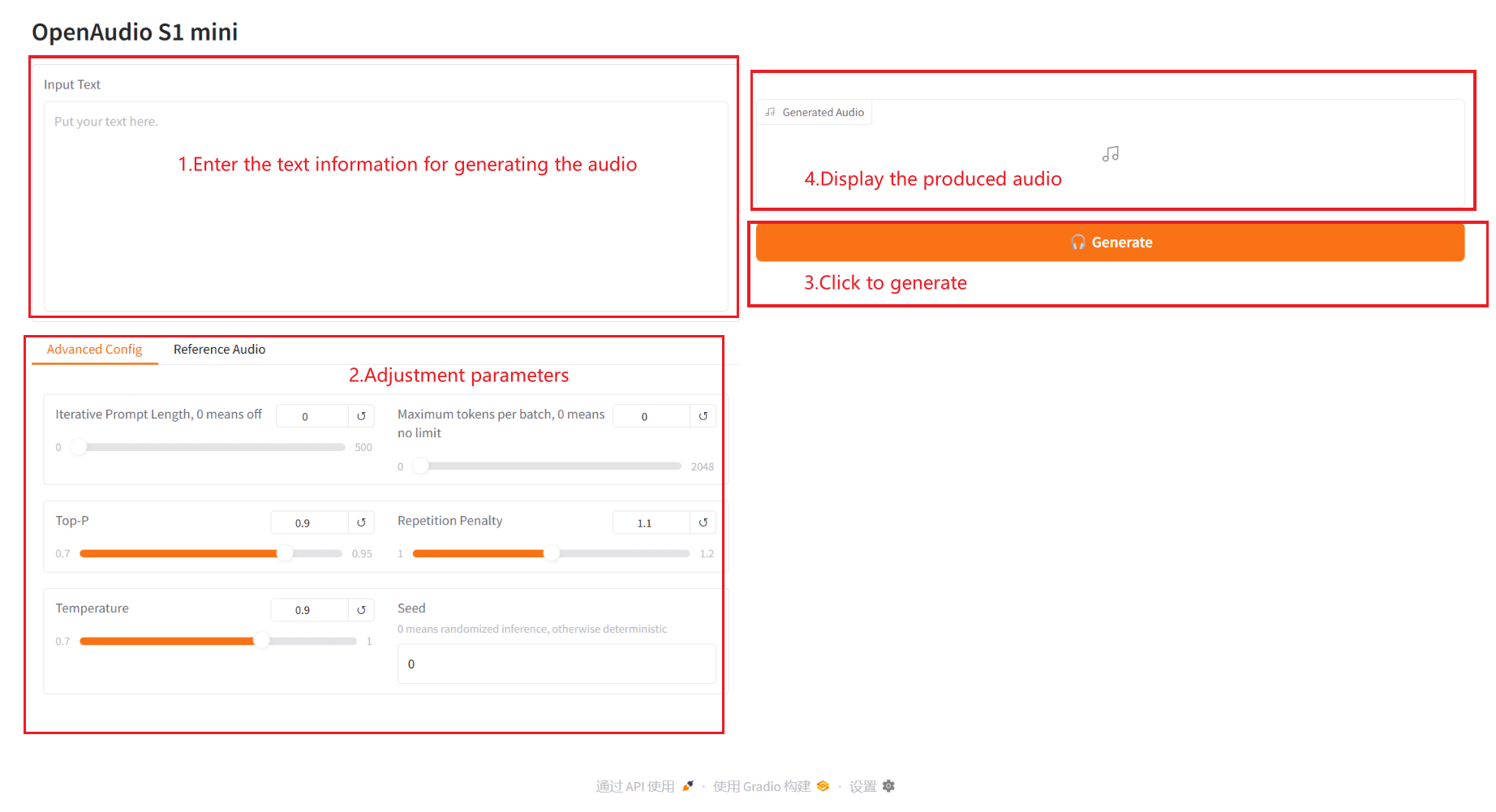
Description des paramètres :
- Configuration avancée :
- Longueur de l'invite itérative : Longueur de l'invite itérative. 0 signifie désactivé. Une valeur différente de zéro contrôle la longueur du texte d'invite utilisé à chaque génération itérative de la parole.
- Nombre maximal de jetons par lot : nombre maximal de jetons par lot. 0 signifie illimité. Une valeur différente de zéro limite le nombre maximal de jetons traités par lot.
- Haut – P : probabilité d’échantillonnage du noyau, qui contrôle la diversité et la certitude du texte généré.
- Pénalité de répétition : coefficient de pénalité de répétition, utilisé pour contrôler la fréquence de répétition du contenu dans le texte généré. Plus la valeur est élevée, plus la répétition est évitée.
- Température : coefficient de température qui ajuste le caractère aléatoire du texte généré. Plus la valeur est élevée, plus le texte est aléatoire.
- Graine : graine aléatoire, utilisée pour générer des nombres aléatoires fixes afin de garantir des résultats reproductibles.
- Audio de référence :
- Utiliser le cache mémoire : sélectionnez si vous souhaitez utiliser le cache mémoire.
- Audio de référence : téléchargez un fichier audio (fichier wav) à utiliser comme référence.
- Texte de référence : saisissez le contenu textuel de l’audio téléchargé.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.