Command Palette
Search for a command to run...
Chatterbox TTS : Démonstration De Synthèse Vocale
1. Introduction au tutoriel

L'une des fonctionnalités clés de Chatterbox est le clonage vocal sans échantillon, qui permet de générer des voix personnalisées très réalistes avec seulement 5 secondes d'audio de référence, sans processus d'apprentissage complexe. De plus, Chatterbox prend en charge le contrôle de l'exagération émotionnelle, permettant aux utilisateurs d'ajuster l'intensité émotionnelle, le débit de parole et l'intonation de la voix pour la rendre plus expressive. La capacité de synthèse en temps réel à très faible latence de Chatterbox, avec une latence inférieure à 200 millisecondes, le rend idéal pour les applications interactives telles que les assistants virtuels et le doublage en temps réel. Pour garantir la sécurité et la traçabilité du contenu, la technologie de tatouage neuronal Perth de Resemble AI est intégrée à l'audio généré par Chatterbox afin d'éviter les abus.
Les principales innovations sont les suivantes :
- Contrôle de l'exagération émotionnelle : en ajustant les paramètres (tels que l'exagération = 0,7 + cfg = 0,3), vous pouvez obtenir un style de discours allant du fade au dramatique.
- Capacité de synthèse en temps réel : délai d'inférence < 200 ms, adapté aux scénarios interactifs en temps réel
Les ressources informatiques de ce tutoriel utilisent une seule carte RTX 4090. Les instructions de ce modèle ne prennent en charge que l'anglais.
2. Étapes de l'opération
1. Démarrez le conteneur
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
2. Étapes d'utilisation
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
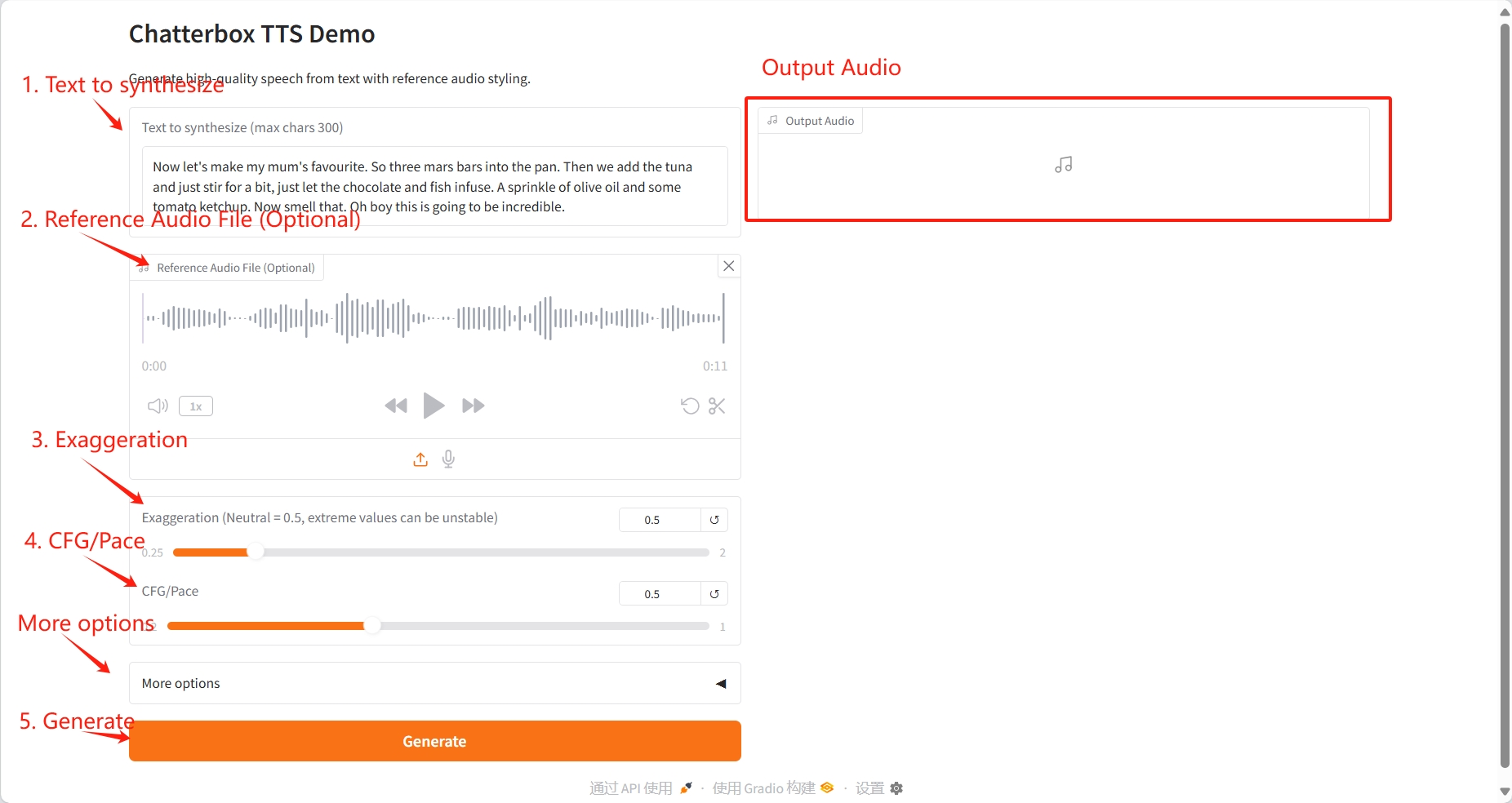
1. Génération de texte
Paramètres spécifiques :
- Texte à synthétiser : saisissez le texte à synthétiser. La longueur maximale est de 300 caractères (le texte trop long sera automatiquement tronqué).
- Fichier audio de référence (facultatif) : fournit un fichier audio de référence pour permettre au système d'imiter le style de voix, l'intonation et le rythme de l'orateur.
- Exagération (Neutre = 0,5) : Contrôle l'exagération de l'expression émotionnelle et du ton de la voix.
- CFG/Pace : Contrôle le rythme et la vitesse de la parole.
- Graine aléatoire (0 pour aléatoire) : définir la graine aléatoire.
- Température : Contrôle le caractère aléatoire et la diversité des expressions vocales.
résultat 
3. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.