Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
2. Exemples de projets
3. Étapes de l'opération
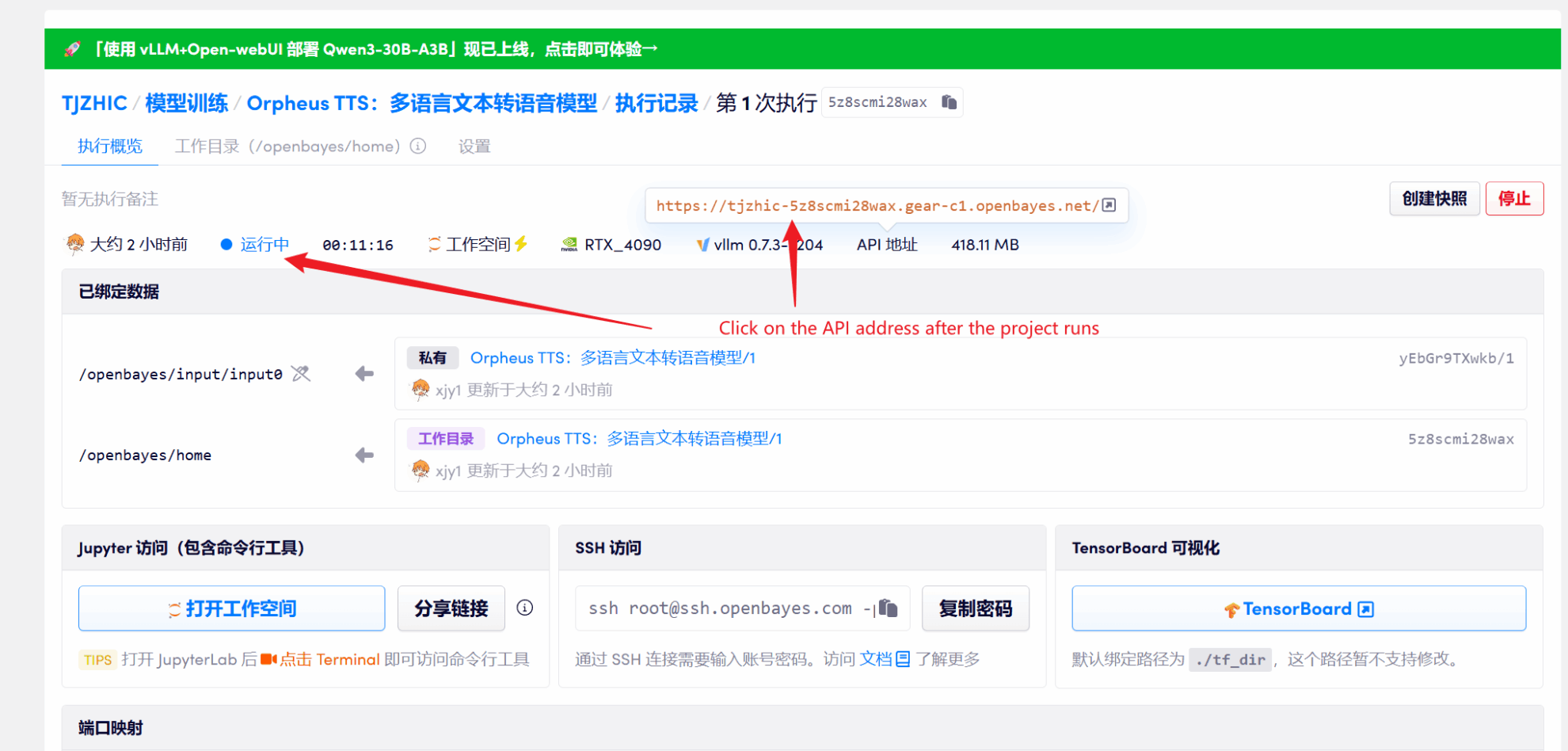
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
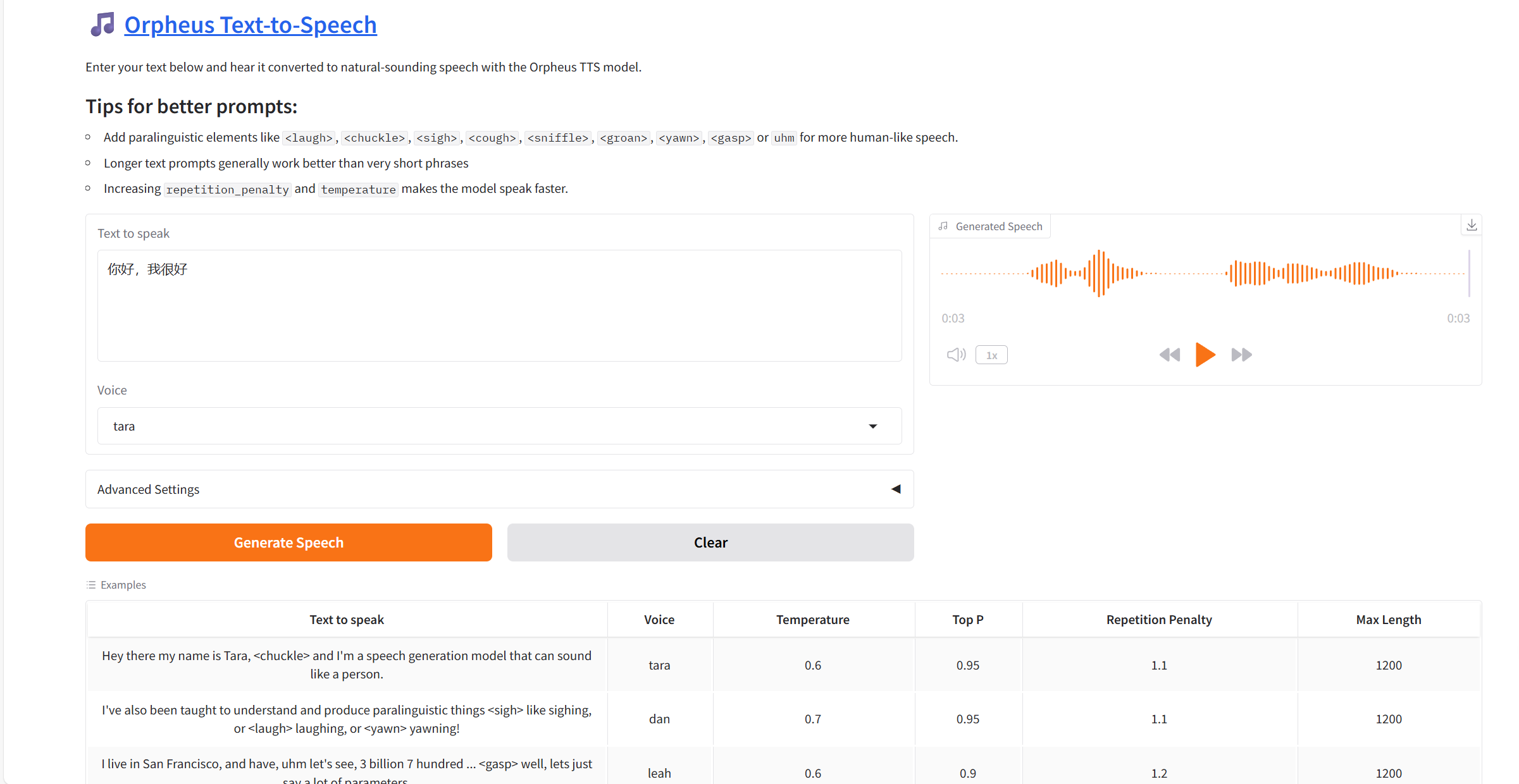
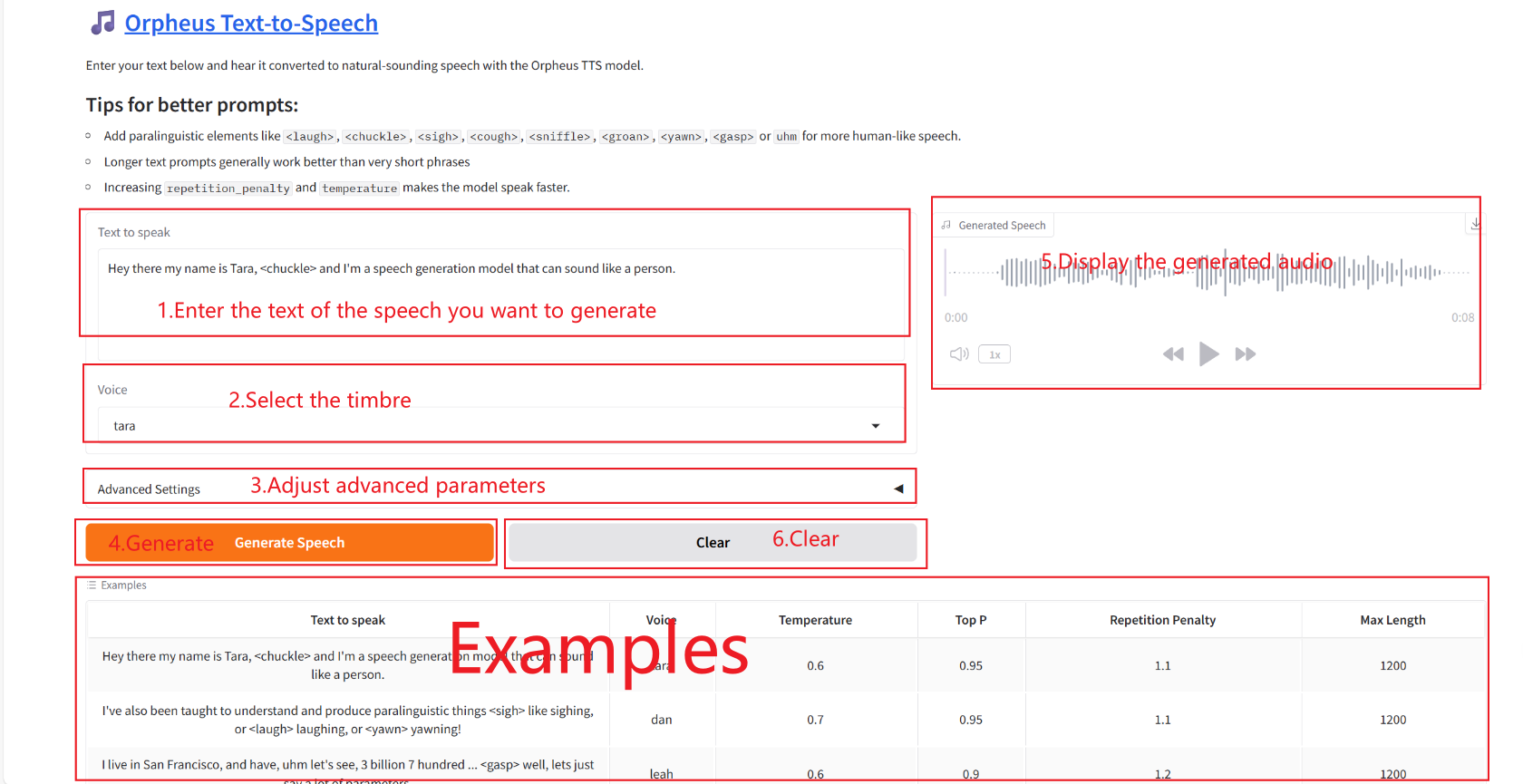
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
❗️Conseils d’utilisation importants :
Température: Contrôlez le caractère aléatoire et la créativité de la génération.
Haut P : Contrôle la plage de sélection des jetons candidats.
Pénalité de répétition : Supprimez les schémas répétitifs dans le discours.
Longueur maximale : Contrôle la durée de l'audio généré.
Comment utiliser
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture. L’effet anglais est meilleur que l’effet chinois.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Soutien au projet
Merci à l'utilisateur Github xxxjjjyyy1 Déploiement de ce tutoriel.
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.
Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
2. Exemples de projets
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
❗️Conseils d’utilisation importants :
Température: Contrôlez le caractère aléatoire et la créativité de la génération.
Haut P : Contrôle la plage de sélection des jetons candidats.
Pénalité de répétition : Supprimez les schémas répétitifs dans le discours.
Longueur maximale : Contrôle la durée de l'audio généré.
Comment utiliser
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture. L’effet anglais est meilleur que l’effet chinois.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Soutien au projet
Merci à l'utilisateur Github xxxjjjyyy1 Déploiement de ce tutoriel.
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.