Command Palette
Search for a command to run...
Démonstration De Reconnaissance Vocale Et De Traduction Whisper-large-v3-turbo

1. Introduction au tutoriel
Whisper est un modèle de reconnaissance vocale à usage général. Il est formé sur un ensemble de données audio vaste et diversifié et peut effectuerMulti-tâches telles que la reconnaissance vocale multilingue et la traduction vocale.
- Reconnaissance vocale multilingue : identifiez automatiquement la langue de l'audio et convertissez-la dans la langue d'origine pour la sortie
- Traduction de la langue : en fonction de la reconnaissance, la langue est traduite en chinois (par défaut) pour la sortie
Lors de l'événement DevDay qui s'est tenu le 1er octobre 2024, OpenAI a annoncé le lancement du modèle de transcription vocale Whisper large-v3-turbo, qui compte un total de 809 millions de paramètres avec presque aucune perte de qualité.8 fois plus rapide que le grand v3
Le modèle de transcription vocale Whisper large-v3-turbo est une version optimisée de large-v3 et ne comporte que 4 couches de décodeur, contre large-v3 qui comporte 32 couches. Modèle Total 809 millions de paramètres, légèrement plus grand que le modèle moyen avec 769 millions de paramètres, mais beaucoup plus petit que le grand modèle avec 1,55 milliard de paramètres.Et la VRAM requise est de 6 Go, tandis que le grand modèle nécessite 10 Go.
2. Étapes de l'opération
Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
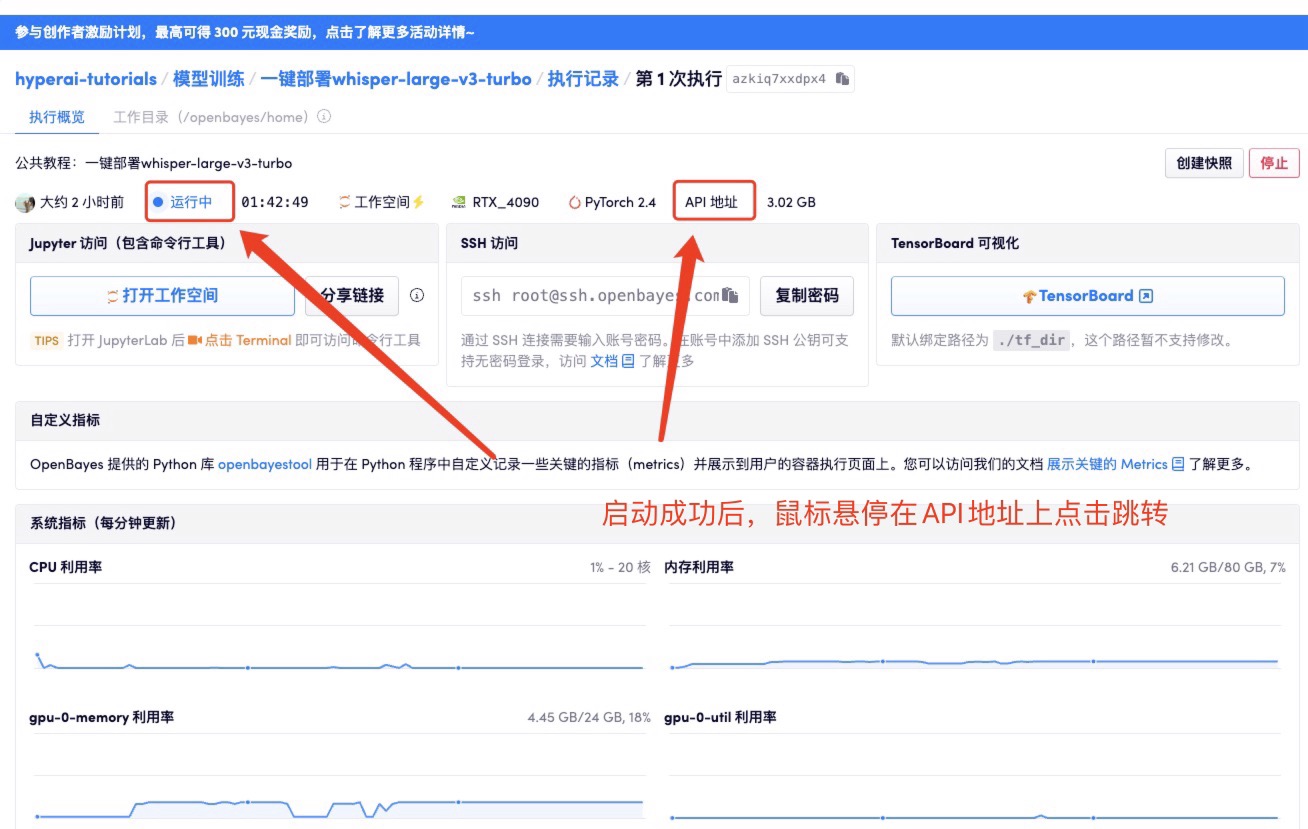
Nous proposons trois fonctions pour la reconnaissance vocale (transcription) ou la traduction (traduction) :
- Microphone Utilisez directement l'appareil pour l'enregistrement en temps réel
- Fichier audio Télécharger un fichier audio hors ligne
- Vidéo en ligne sur YouTube
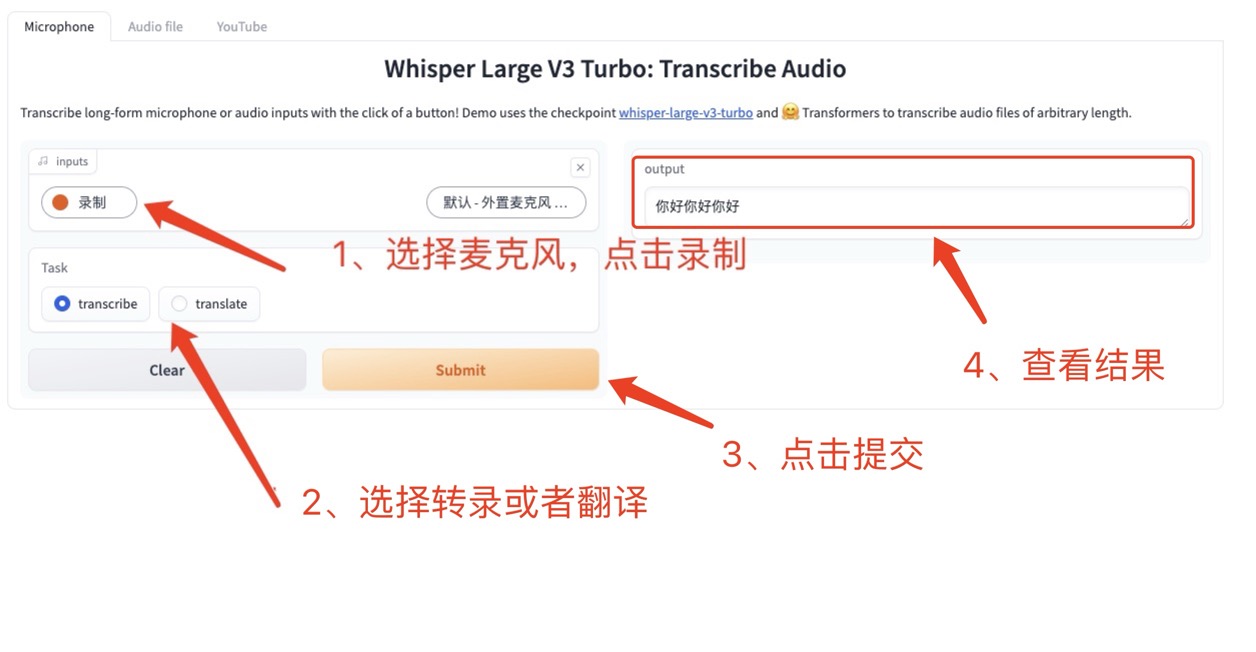
1. Le microphone utilise directement l'appareil pour l'enregistrement en temps réel
Cliquez Microphone (par défaut), utilisez le microphone de l'appareil pour enregistrer l'audio. Après l'enregistrement, l'audio sera téléchargé sur la plateforme, sélectionnez la transcription ou la traduction, puis cliquez sur Soumettre pour générer le texte spécifié. (La traduction peut être inexacte pour des raisons de performances du modèle)
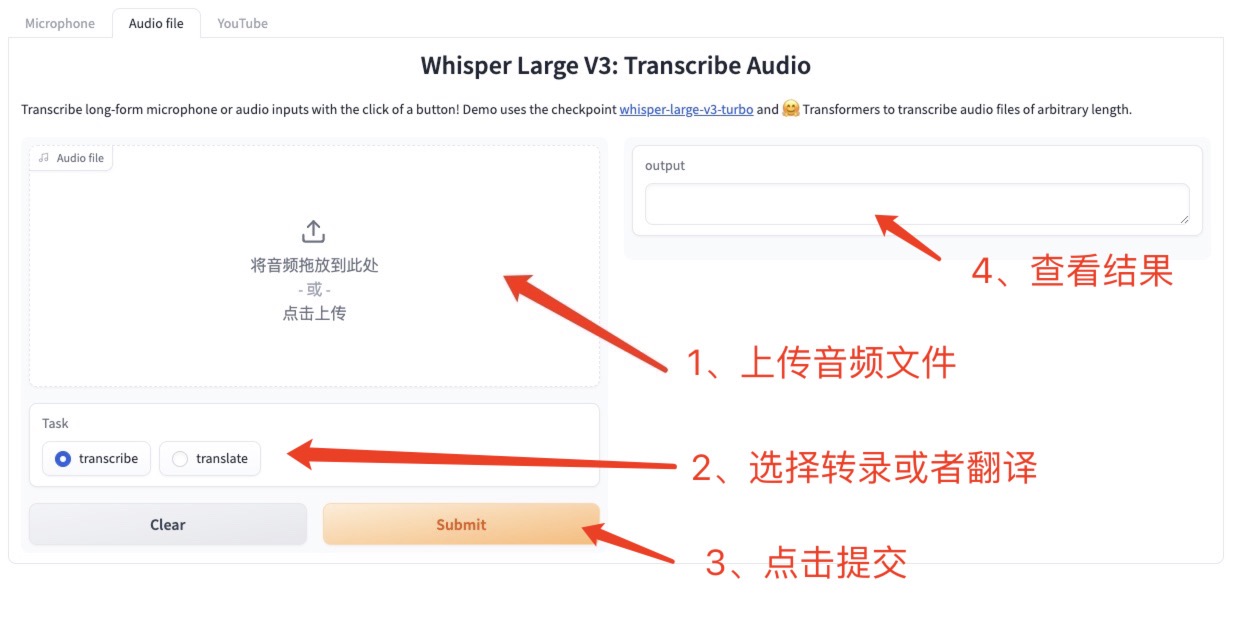
2. Téléchargement de fichiers audio hors ligne
Cliquez Fichier audio, téléchargez ou faites glisser l'audio à exécuter dans l'interface, sélectionnez la transcription ou la traduction, puis cliquez sur Soumettre pour générer le texte spécifié.
3. Vidéo en ligne YouTube (en raison de problèmes de réseau, elle peut ne pas être reconnue et nécessite plusieurs tentatives. La démo est fournie à titre indicatif uniquement)
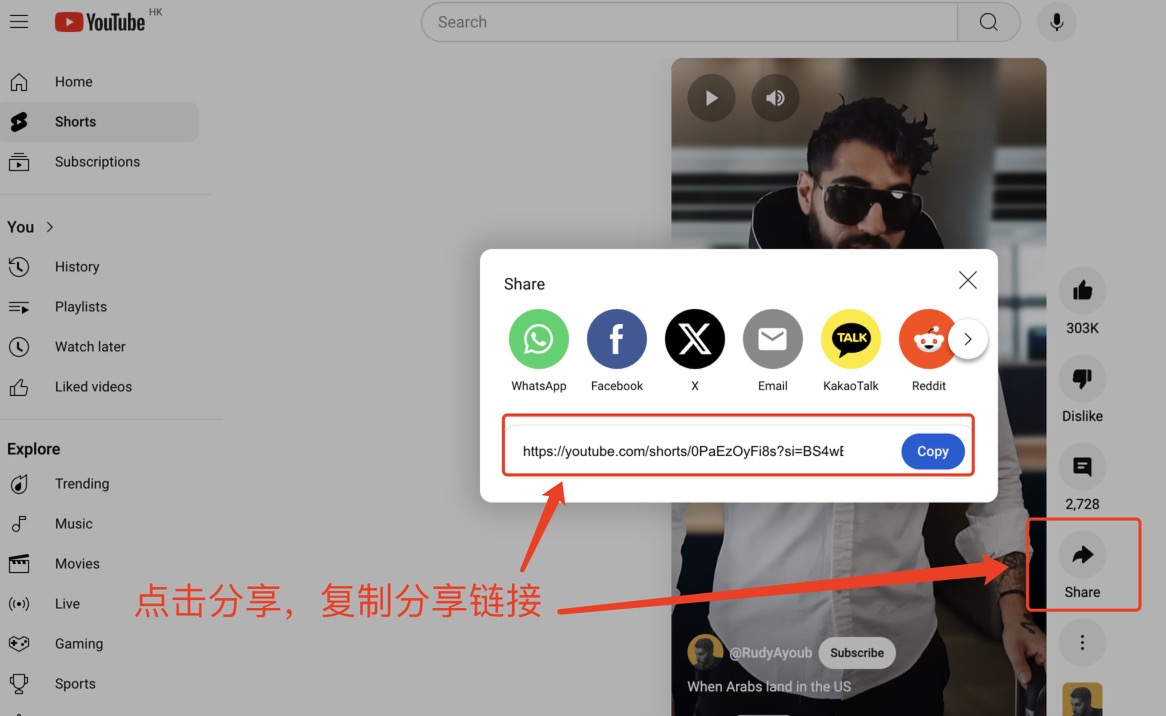
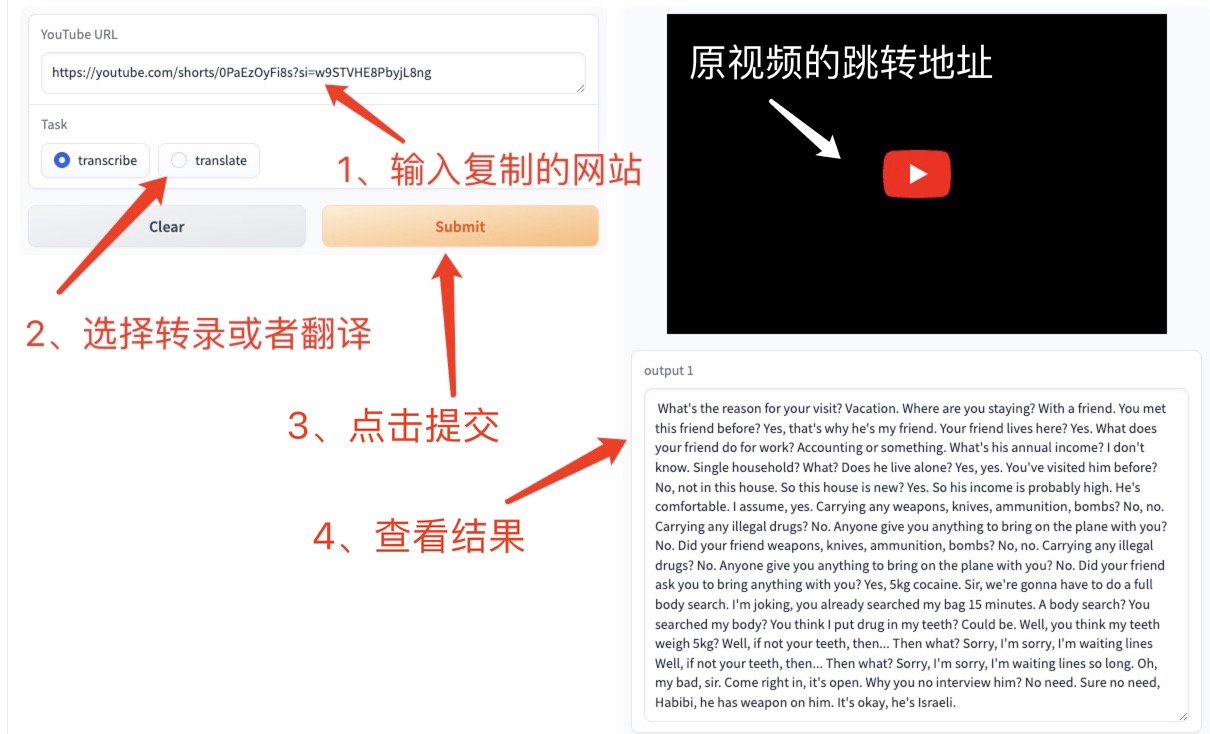
Parcourez la page Web YouTube et trouvez la vidéo que vous souhaitez. Cliquez sur Partager à droite et une URL apparaîtra. Copiez cette URL dans la zone de texte de la page Web. URL YouTube , sélectionnez Transcrire ou Traduire, puis cliquez sur Soumettre pour générer le texte spécifié.
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.